[Today I Learn]
- SQL codekata
- Python codekata
- 오전 통계학 실습 세션
- 오후 통계학 이론 세션
- 통계학 기초 vod
[SQL codekata]
- 문제 1.
1. 문제 링크: https://www.hackerrank.com/challenges/weather-observation-station-4/problem
2. 정답 코드
select count(city)-count(distinct city)
from station
- 문제 2.
1. 문제 링크: https://www.hackerrank.com/challenges/weather-observation-station-6/problem
2. 정답 코드
select distinct city
from station
WHERE city regexp '^a|^e|^i|^o|^u'
- 문제 3.
1. 문제 링크: https://www.hackerrank.com/challenges/weather-observation-station-7/problem
2. 정답 코드
select distinct city
from station
where city regexp 'a$|e$|i$|o$|u$'
- SQL regexp
| . | 문자 하나 | "..." | 문자열의 길이가 세 글자 이상인 것 |
| | | 또는 (or) | "a|b" | 'a' 또는 'b'에 해당하는 문자열 |
| [] | [] 안에 나열된 패턴에 해당하는 문자열 | "[123]d" | 대상 문자열에서 '1d', '2d', '3d' 중 하나에 해당하는 문자열 |
| ^ | 시작하는 문자열 | "^a" | a로 시작하는 문자열 |
| $ | 끝나는 문자열 | "b$" | b로 끝나는 문자열 |
[Python codekata]
- 문제 1.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120836?language=python3
2. 정답 코드
def solution(n):
cnt = 0
for i in range (1,n+1):
if n % i == 0:
cnt += 1
return cntdef solution(n):
cnt = 0
for i in range (1, int(n**0.5)+1):
if n%i == 0:
cnt += 2
if i*i == n:
cnt -= 1
return cntdef solution(n):
return len([i for i in range (1,n+1) if n%i == 0])def solution(n):
cnt = 0
for i in range(n): # 0~n-1
if n%(i+1) == 0:
cnt+=1
return cnt
- 문제 2.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120905?language=python3
2. 정답 코드
def solution(n, numlist):
answer = []
for i in numlist:
if i % n == 0:
answer.append(i)
return answerdef solution(n, numlist):
answer = [i for i in numlist if i%n==0]
return answer
[ 오전 통계학 실습 세션 ]
- 지수분포

- 특징: 무기억성 - 지금까지 기다린 시간은 앞으로 기다릴 시간에 영향을 주지 않는다.
- 실용 예제: 고객 도착 간격, 기계 고장까지 시간, 전화 통화 간격
- 포아송과의 관계: 단위 시간당 lambda번 발생하면, 사건 사이의 간격은 지수분포를 따른다 (평균 간격 = 1/lambda)
print("\n" + "="*60)
print("Part 5.2: 지수 분포")
print("="*60)
# 실습: 기계 수명 분석
print("\n[실습] 기계 수명 분석")
print("기계의 평균 수명: 1000시간")
print("(즉, 시간당 고장률 λ = 1/1000 = 0.001)")
mean_lifetime = 1000 # 평균 수명 (시간)
lambda_rate = 1 / mean_lifetime
# scipy.stats를 이용한 지수 분포
# scipy에서는 scale = 1/lambda = 대기시간
exp_dist = stats.expon(scale=mean_lifetime) # 사건이 발생할 때까지 대기시간
# (1) 500시간 이내에 고장날 확률
print(exp_dist.cdf(500))
# (2) 1500시간 이상 작동할 확률
print(exp_dist.sf(1500)) # 1 - (1500시간 내에 고장날 확률)
# (3) 기대값과 표준편차
print(exp_dist.mean())
print(exp_dist.std())
# (4) 중앙값 (50%가 고장나는 시점)
print(exp_dist.median())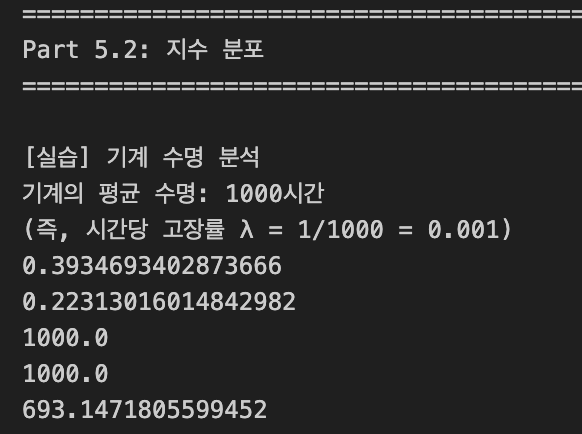
# 시각화
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
x = np.linspace(0, 4000, 1000) # 0이상 4000이하 1000등분해서 1000개 데이터 생성
# PDF
pdf = exp_dist.pdf(x)
axes[0].plot(x, pdf, 'b-', linewidth=2)
axes[0].fill_between(x, pdf, alpha=0.3)
axes[0].axvline(mean_lifetime, color='red', linestyle='--', label=f'평균 수명 = {mean_lifetime}시간')
axes[0].set_xlabel('시간')
axes[0].set_ylabel('확률 밀도')
axes[0].set_title('지수 분포: 기계 수명 PDF', fontweight='bold')
axes[0].legend()
# 생존 함수 (1 - CDF)
survival = 1 - exp_dist.cdf(x)
axes[1].plot(x, survival, 'b-', linewidth=2)
axes[1].axhline(0.5, color='red', linestyle='--', alpha=0.5)
axes[1].axvline(exp_dist.median(), color='green', linestyle=':', label=f'중앙값 = {exp_dist.median():.0f}시간')
axes[1].set_xlabel('시간')
axes[1].set_ylabel('생존 확률')
axes[1].set_title('지수 분포: 생존 함수', fontweight='bold')
axes[1].legend()
plt.tight_layout()
plt.show()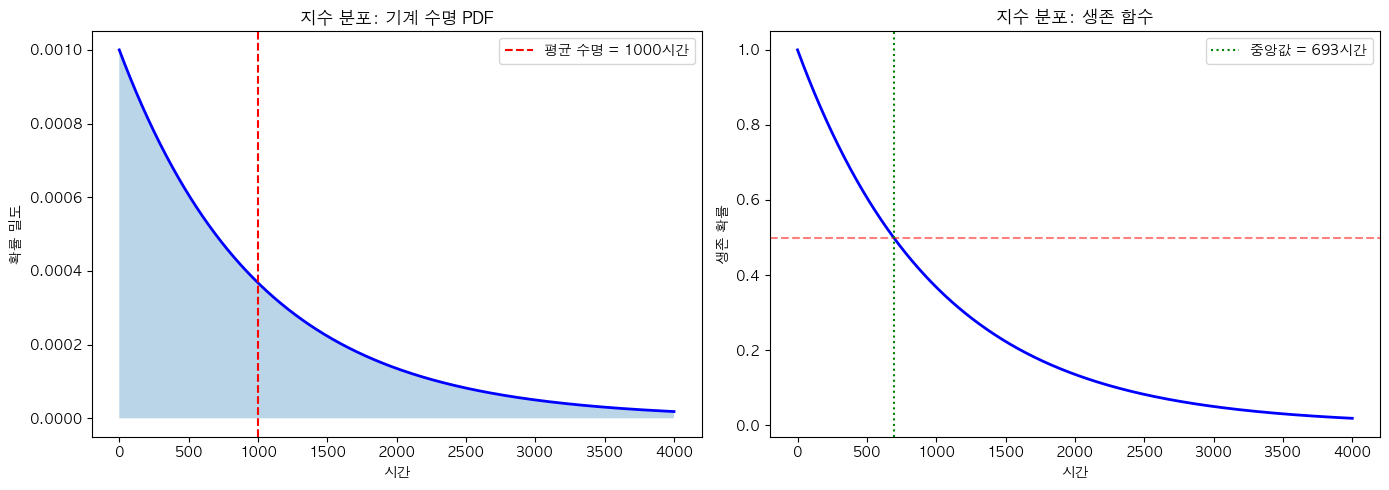
- 정규 분포


# 시각화
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
x = np.linspace(150, 196, 1000)
# PDF
pdf = norm_dist.pdf(x)
axes[0].plot(x, pdf, 'b-', linewidth=2)
axes[0].fill_between(x, pdf, alpha=0.3)
axes[0].axvline(mu, color='red', linestyle='--', label=f'평균 = {mu}cm')
axes[0].axvline(mu - sigma, color='orange', linestyle=':', alpha=0.7)
axes[0].axvline(mu + sigma, color='orange', linestyle=':', alpha=0.7, label=f'±1σ 구간')
axes[0].set_xlabel('키 (cm)')
axes[0].set_ylabel('확률 밀도')
axes[0].set_title('정규 분포: 한국 성인 남성 키', fontweight='bold')
axes[0].legend()
# 다양한 μ, σ 비교
params = [(173, 6, '평균 173, σ=6'), (180, 6, '평균 180, σ=6'), (173, 10, '평균 173, σ=10')]
for mu_i, sigma_i, label in params:
pdf = stats.norm.pdf(x, loc=mu_i, scale=sigma_i)
axes[1].plot(x, pdf, linewidth=2, label=label)
axes[1].set_xlabel('키 (cm)')
axes[1].set_ylabel('확률 밀도')
axes[1].set_title('μ와 σ에 따른 정규 분포 변화', fontweight='bold')
axes[1].legend()
plt.tight_layout()
plt.show()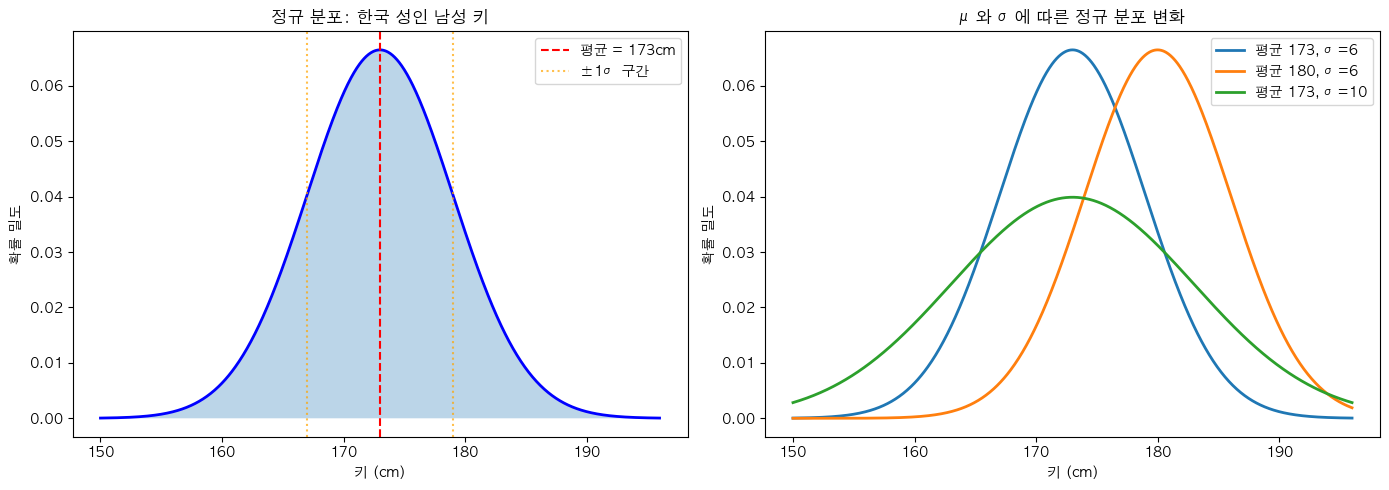
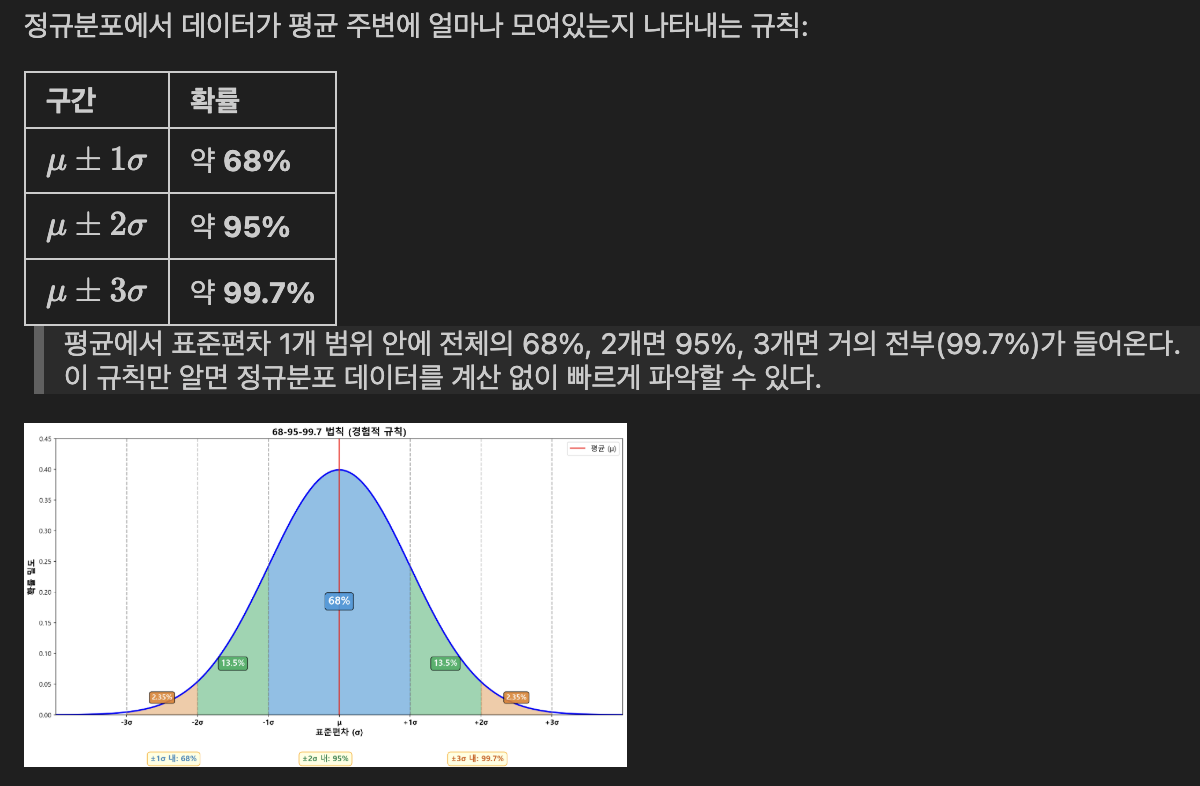
- 정규분포 심화
- 68-95-99.7 법칙 (경험적 규칙)
print("\n" + "="*60)
print("Part 6: 정규분포 심화")
print("="*60)
# 68-95-99.7 법칙 검증
print("\n[68-95-99.7 법칙 검증]")
standard_normal = stats.norm(0, 1)
# 각 구간의 확률 계산
p_1sigma = standard_normal.cdf(1) - standard_normal.cdf(-1)
p_2sigma = standard_normal.cdf(2) - standard_normal.cdf(-2)
p_3sigma = standard_normal.cdf(3) - standard_normal.cdf(-3)
print(f"±1σ 구간 확률: {p_1sigma:.4f} = {p_1sigma*100:.2f}% (≈ 68%)")
print(f"±2σ 구간 확률: {p_2sigma:.4f} = {p_2sigma*100:.2f}% (≈ 95%)")
print(f"±3σ 구간 확률: {p_3sigma:.4f} = {p_3sigma*100:.2f}% (≈ 99.7%)")
- 표준화와 z-score

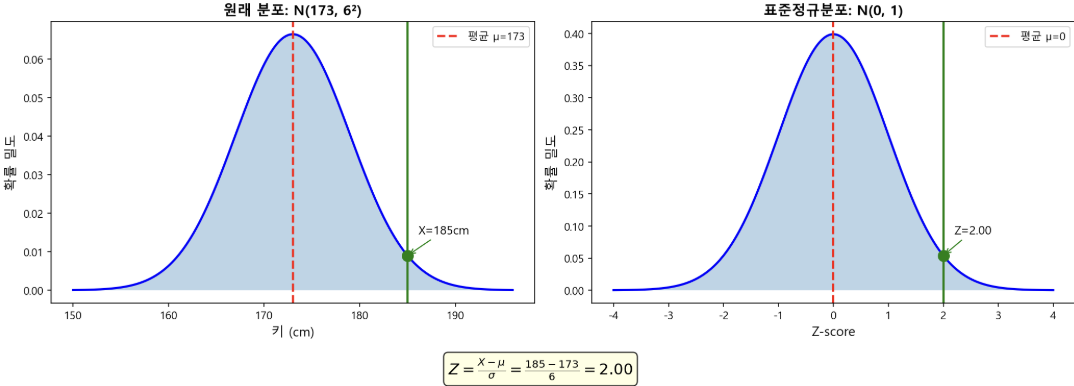
mu = 70
sigma = 10
my_score = 85
# (1) Z-score 계산
z_score = (my_score - mu) / sigma
print(f"z-score : {z_score}")
# (2) 상위 몇 %인지 계산
top_percentile = stats.norm.sf(z_score) # P(Z > z_score)
print("상위 %:", top_percentile)
# (3) 상위 10%가 되려면 몇 점 필요?
z_top10_score = stats.norm.ppf(0.9) # 상위 10% 점수 (역함수 ppf 활용)
print("상위 10% : ",z_top10_score)
# 실습: 두 과목 점수 비교
print("\n[실습] 두 과목 점수 비교")
print("국어: 80점 (평균 75, 표준편차 5)")
print("수학: 85점 (평균 70, 표준편차 15)")
print("어느 과목이 상대적으로 더 잘 본 걸까?")
# 국어 Z-score
korean_z = (80-75)/5
print(korean_z)
# 수학 Z-score
math_z = (85-70)/15
print(math_z)
# 결론
# 국어와 수학 모두 z-score가 1.0으로
# 평균으로부터 똑같이 1 시그마만큼 떨어져있는 것이므로
# 똑같은 정도로 잘 본 것이다
- 품질 관리와 six sigma

# 품질 관리 실습
print("\n[품질 관리 실습]")
print("규격: 부품 길이 50mm ± 0.1mm (허용 오차)")
print("공정 능력: 평균 50mm, 표준편차 0.03mm")
target = 50
tolerance = 0.1
sigma_process = 0.03
# 규격 상한/하한
USL = target + tolerance # Upper Spec Limit
LSL = target - tolerance # Lower Spec Limit
# (1) 규격 내 합격률 계산 (규격내 제품의 비율)
norm_dist = stats.norm(loc=target, scale=sigma_process) #현재 공장의 생산되는 제품의 분포
pass_rate = norm_dist.cdf(USL) - norm_dist.cdf(LSL)
print(f"pass_rate : {pass_rate:.6f}")
# (2) 백만 개당 불량품 수 (DPMO)
dpmo = (1-pass_rate) * 1000000
print("백만개당 불량 (DPMO): ", dpmo) # 858.12
# (3) 이 공정은 몇 시그마 수준?
sigma_level = (USL-target) / sigma_process # USL의 Z표준화 점수
print("이 공정의 시그마 수준: ", sigma_level) # 3.333
# 6시그마로 공정을 설계하면 4.5시그마 수준이 현실적인 수치
# 현재 공정이 3.3 시그마 수준이다.
- 확률분포 핵심 함수 정리
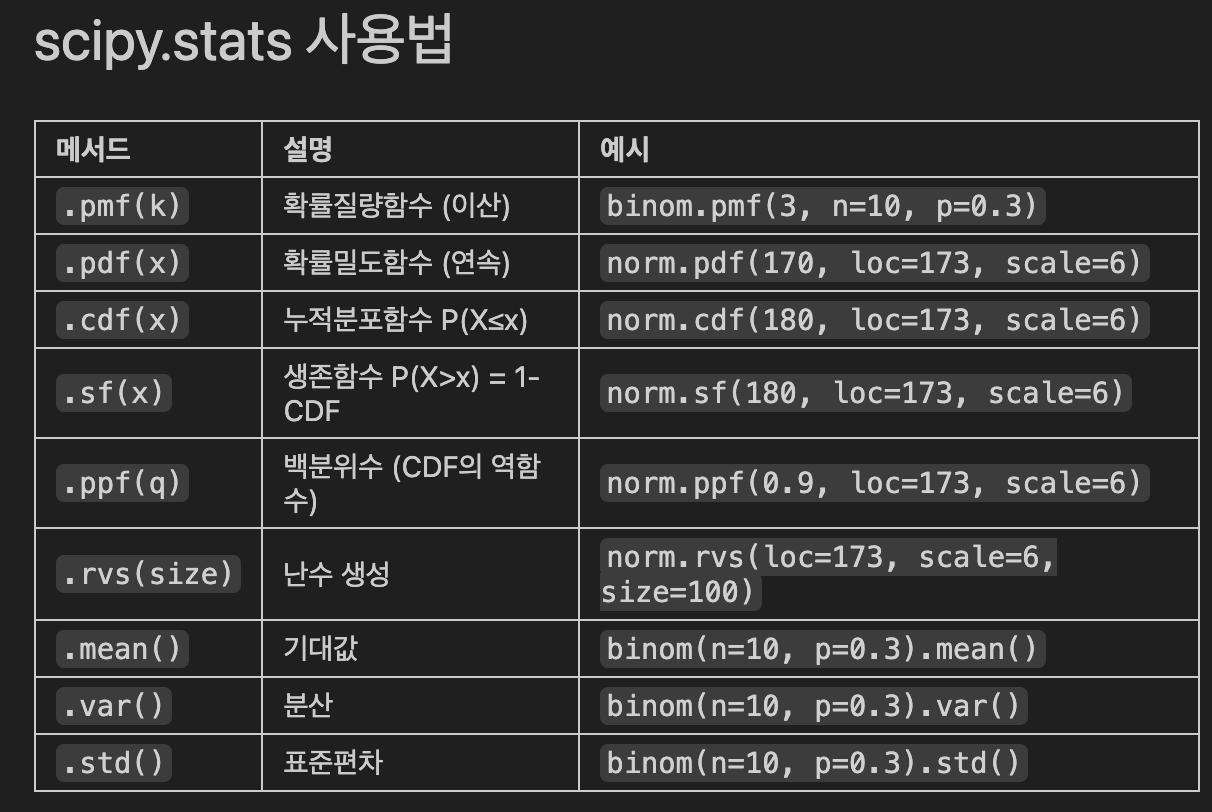


- 주요 용어 정리
- 표본분포
- 통계량(표본평균)이 따르는 확률분포
- 표준오차
- 통계량의 표준편차 - 추정의 정밀도를 나타냄
- 표본분포
# 시각화: 표본크기별 표본평균의 분포 (CLT 검증)
fig, axes = plt.subplots(1, 3, figsize=(20, 10))
fig.suptitle('표본크기(n)에 따른 표본평균의 분포 변화', fontsize=14, fontweight='bold')
np.random.seed(42)
for i, n in enumerate([5, 30, 100]):
sample_means = [np.mean(np.random.choice(population, size=n)) for _ in range(2000)]
axes[i].hist(sample_means, bins=40, density=True, color='steelblue',
alpha=0.7, edgecolor='white')
x = np.linspace(min(sample_means), max(sample_means), 200)
axes[i].plot(x, stats.norm.pdf(x, np.mean(sample_means), np.std(sample_means)),
'r-', linewidth=2, label='정규분포 근사')
axes[i].axvline(pop_mean, color='red', linestyle='--', linewidth=1.5,
label=f'μ = {pop_mean:.2f}') # 모평균
axes[i].set_title(f'n = {n}\nSE = {pop_std/np.sqrt(n):.2f}', fontsize=12, fontweight='bold')
axes[i].set_xlabel('표본평균')
axes[i].legend(fontsize=9)
if i == 0:
axes[i].set_ylabel('밀도')
- 중심극한정리 (CLT, Central Limit Theorem)
- 모집단이 어떤 분포든 상관없이, 표본크기 n이 충분히 크면 (보통 n>=30), 표본평균의 분포는 정규분포에 가까워짐
- CLT에 대한 흔한 오해
- 개별 데이터가 정규분포를 따른다 -> 개별데이터는 그대로임. 평균의 분포만 정규분포가 됨
- 많이 반복하면 정규분포가 된다 -> 표본크기가 클수록 정규분포에 가까워짐. 반복횟수는 분포 모양과 무관함
- 모든 통계량이 정규분포를 따른다 -> 평균(또는 합계)에만 적용됨. 중앙값이나 최댓값 등은 해당되지 않음
- n>=30이면 무조건 충분하다 -> 30은 경험적 기준일 뿐임. 모집단의 원래 분포에 따라 다름
- 표본오차 vs 표준오차
| 구분 | 표본오차 | 표준오차 |
| 정의 | 특정 표본의 통계량과 모수 간의 실제 차이 | 표본 통계량(주로 표본평균)들의 표준편차 |
| 예시 | 모평균 170, 표본평균 171.3 -> 오차 = 1.3 | 100명씩 반복 추출한 표본평균들의 표준편차 = 0.6 |
| 값 | 표본마다 다름 | 표본 크기가 같으면 고정 |
| 계산 | 모수를 알아야 계산 가능 (현실적으로 불가) | 표본만으로 추정 가능 SE = s/√n |
| 활용 | 실제 통계에서 거의 활용 안 됨 | 신뢰구간, 가설검정 등에 핵심적 활용 |

- 점추정 (Point Estimation)
- 모수를 하나의 값으로 추정
- 모수: 모집단의 특성값 - 고정된 값이지만 알 수 없음
- ddof=1
- 편향을 제거하기 위한 수학적 장치
- 평균의 경우 표본 50개를 다 더해서 50으로 나누는 것이 수학적으로 모평균에 가장 가까운 '불편추정량'임이 증명되어 있음. 따라서 보정할 필요가 없음
- 분산의 경우 평균으로부터의 거리를 계산하는데, 우리는 모평균을 모르기 때문에 대신 표본평균을 사용함
- 표본들은 자기들끼리의 평균에 더 가깝게 뭉쳐있기 때문에, n으로 나누면 모분산보다 작게 측정되는 경향이 있음
- 이를 보완하기 위해 분모를 n-1로 줄여 전체 분산 값을 살짝 키워주는 것
# 점추정 실습
print("\n[실습] 점추정 체험")
print("=" * 50)
# 모집단: 평균 170, 표준편차 8인 정규분포 (예: 키)
np.random.seed(42)
true_mu = 170
true_sigma = 8
# 표본 추출
sample = np.random.normal(true_mu, true_sigma, size=50)
print(f"모집단: μ = {true_mu}, σ = {true_sigma}")
print(f"표본 크기: n = {len(sample)}")
# TODO: 점추정 결과 출력 (표본평균, 표본분산, 표본표준편차)
print(f"모평균의 추정: {np.mean(sample):.2f}")
print(f"모분산의 추정: {np.var(sample, ddof=1):.2f}")
# numpy의 경우 ddof = 0 이 디폴트, pandas의 ddof의 기본값은 1이 디폴트
print(f"모표준편차의 추정: {np.std(sample, ddof=1):.2f}")
- 구간추정과 신뢰구간
- 구간추정: 모수가 포함될 것으로 기대하는 범위 제시
- 신뢰구간 = 점추정값 +- 오차한계
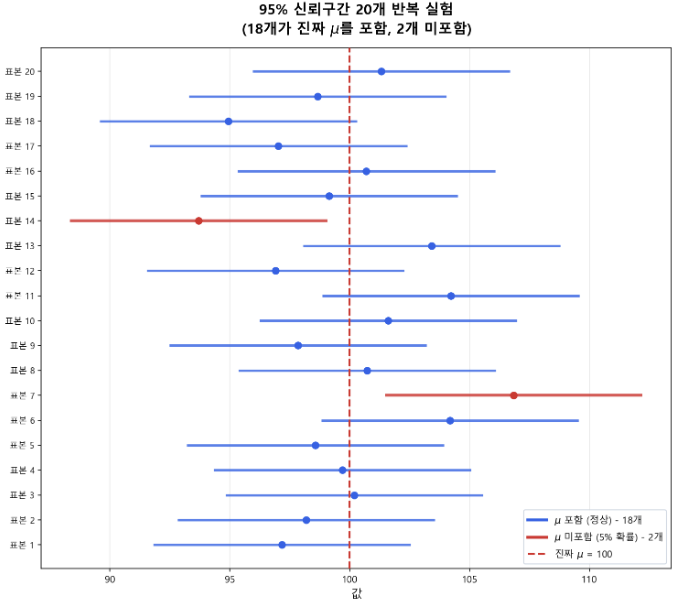
- 신뢰구간의 올바른 해석
- 95% 신뢰구간의 의미
- 올바른 해석: 이 방법으로 구간을 100번 만들면, 약 95번은 진짜 모평균을 포함한다
- 틀린 해석: 모평균이 이 구간에 있을 확률이 95%다 (모평균은 고정값이므로 확률 개념 적용 불가)
- 실무적 해석 (의사결정용)
- 양측: 95% 신뢰수준으로 실제 평균이 a와 b 사이에 있다고 볼 수 있습니다.
- 하한 단측: 95% 신뢰수준으로 실제 평균이 a보다 크다고 볼 수 있습니다.
- 상한 단측: 95% 신뢰수준으로 실제 평균이 b보다 작다고 볼 수 있습니다.

# 신뢰구간 계산 실습
print("\n[실습] 신뢰구간 계산")
print("=" * 50)
np.random.seed(42)
# 시나리오: 은행창구 대기시간 조사 (50명 표본)
wait_times = np.random.normal(loc=8.5, scale=2.0, size=50)
n = len(wait_times)
xbar = np.mean(wait_times)
s = np.std(wait_times, ddof=1)
se = s / np.sqrt(n) # 표준오차
print(f"은행창구 대기시간 조사 (n = {n})")
print(f" 표본평균 x̄ = {xbar:.2f}분")
print(f" 표본표준편차 s = {s:.2f}분")
print(f" 표준오차 SE = s/√n = {se:.3f}분")
# ─────────────────────────────────────────────
# 방법 1: 수동 계산 (t 분포 사용)
# ─────────────────────────────────────────────
print("\n[방법 1] 수동 계산 (t 분포)")
print("-" * 50)
for confidence in [0.90, 0.95, 0.99]:
alpha = 1 - confidence
# TODO: t 임계값 계산 (stats.t.ppf(1 - alpha/2, df=n-1))
t_crit = stats.t.ppf(1-alpha/2, df=n-1)
# TODO: 오차한계 계산 (t_crit * se)
margin = t_crit * se
# TODO: 신뢰구간 하한, 상한 계산
ci_low = xbar - margin
ci_high = xbar + margin
# TODO: 결과 출력
print(f"신뢰수준 {confidence*100:.0f} CI: [{ci_low:.2f}, {ci_high:.2f}]")
# 신뢰수준 90 CI: [7.61, 8.49]
# 신뢰수준 95 CI: [7.52, 8.58]
# 신뢰수준 99 CI: [7.34, 8.76] # 신뢰수준이 높을수록 신뢰구간이 넓어짐
# ─────────────────────────────────────────────
# 방법 2: scipy.stats 활용
# ─────────────────────────────────────────────
print("\n[방법 2] scipy.stats 활용")
print("-" * 50)
# TODO: stats.t.interval(신뢰수준, df, loc, scale)로 90%, 95%, 99% CI 계산
ci_90 = stats.t.interval(0.90, df=n-1, loc=xbar, scale=se) # 튜플 형태로 저장
ci_95 = stats.t.interval(0.95, df=n-1, loc=xbar, scale=se)
ci_99 = stats.t.interval(0.99, df=n-1, loc=xbar, scale=se)
print(f"신뢰수준 {0.90} CI: [{ci_90[0]:.2f}, {ci_90[1]:.2f}]")
print(f"신뢰수준 {0.95} CI: [{ci_95[0]:.2f}, {ci_95[1]:.2f}]")
print(f"신뢰수준 {0.99} CI: [{ci_99[0]:.2f}, {ci_99[1]:.2f}]")
print(ci_90) # 튜플 형태
- 단측 신뢰구간
- 양측: 얼마와 얼마 사이인가?
- 상한 단측: 최대 얼마 이하인가?
- 하한 단측: 최소 얼마 이상인가?

# 단측 신뢰구간 실습
print("\n[실습] 양측 vs 단측 신뢰구간 비교")
print("=" * 50)
np.random.seed(99)
# 시나리오 1: 양측 CI
# 신제품 배터리의 평균 수명이 대략 어느 범위인지 파악하고 싶습니다
battery_hours = np.random.normal(loc=503, scale=6, size=10)
n_bat = len(battery_hours) # 샘플 개수
mean_bat = np.mean(battery_hours) # 표본 평균
se_bat = stats.sem(battery_hours) # 표준 오차
print(f"[시나리오] 신제품 배터리 수명 테스트 (n = {n_bat})")
print(f" 표본평균: {mean_bat:.1f}시간, 표준오차: {se_bat:.2f}시간")
# TODO: 양측 95% CI 계산
ci_low, ci_high = stats.t.interval(0.95, df=n_bat-1, loc=mean_bat, scale=se_bat)
# TODO: 결과 출력
print(f"신뢰수준 {0.95} CI: [{ci_low:.2f}, {ci_high:.2f}]")
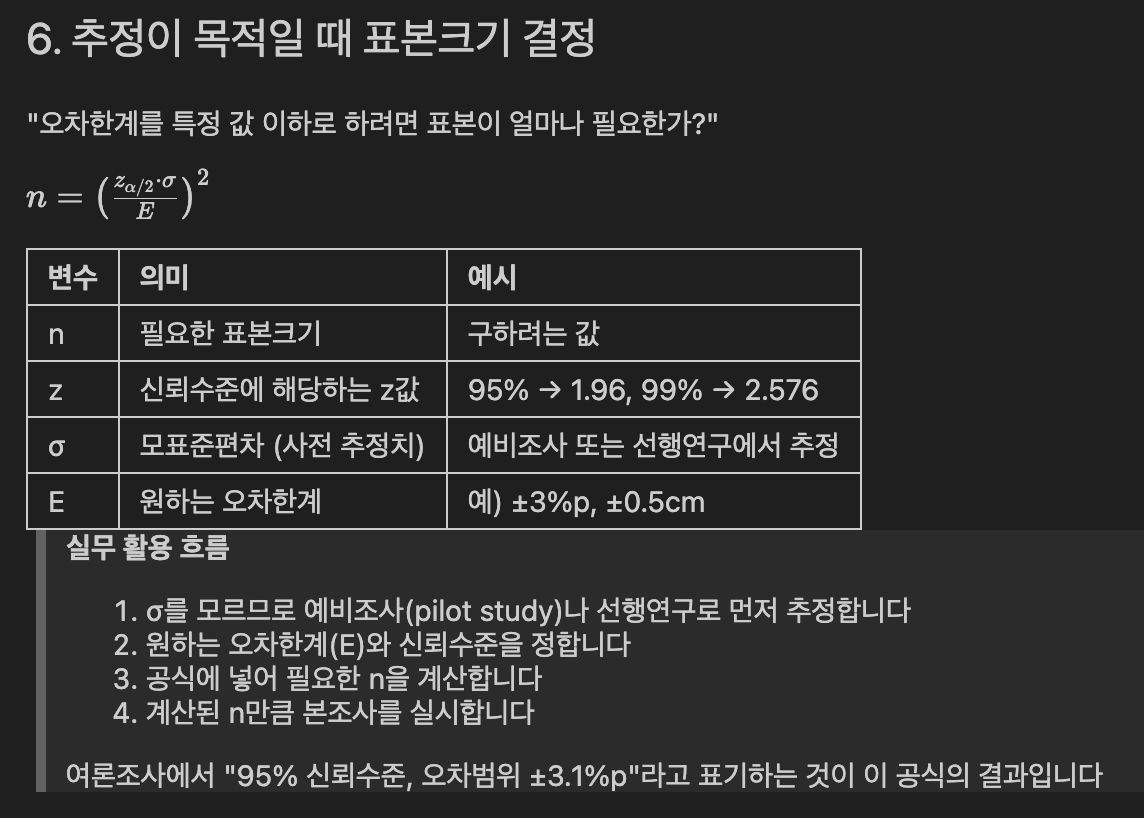
# 표본크기 결정 실습
print("\n[실습] 표본크기 결정")
print("=" * 50)
print("시나리오: 커피숍 평균 대기시간을 조사하려고 합니다.")
print("사전 조사에서 표준편차 약 2분으로 추정되었습니다.")
print("95% 신뢰수준에서 오차한계를 0.5분 이내로 하고 싶다면?")
sigma_est = 2.0 # 추정 표준편차
z_95 = 1.96 # 95% 신뢰수준 z값
E = 0.5 # 원하는 오차한계
# TODO: 필요 표본크기 계산
n_required = (z_95 * sigma_est / E) ** 2
# TODO: 결과 출력
print(np.ceil(n_required))
# 오차한계별 필요 표본크기 비교
print("\n[오차한계별 필요 표본크기]")
print("-" * 40)
for E in [1.0, 0.5, 0.3, 0.1]:
# TODO: 각 오차한계에 대한 필요 표본크기 계산 및 출력
n_required = (z_95 * sigma_est / E) ** 2
print(f" 오차한계 +- {E}분 = {int(np.ceil(n_required))}명") # 올림으로 최대 표본개수를 구한다
- 가설검정
- 모집단에 대한 주장(가설)을 표본 데이터를 이용해 검증하는 통계적 절차
'효과가 없다'고 가정하고 -> 데이터를 확인하고 -> "이런 결과가 우연히 나올 수 있을까?" 판단한다

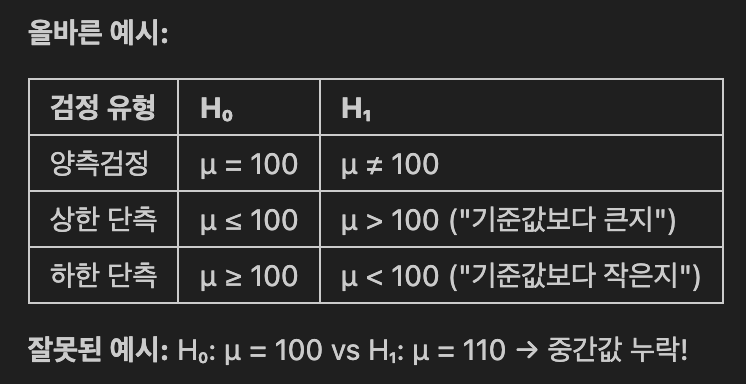
- 귀무가설과 대립가설

- 가설 설정의 원칙: 상호배타적 + 전체포함
- 상호배타적: H0와 H1이 정반대 (동시에 참일 수 없음)
- 전체 포함: 모든 가능한 경우를 빠짐없이 포함

- p-value와 유의수준
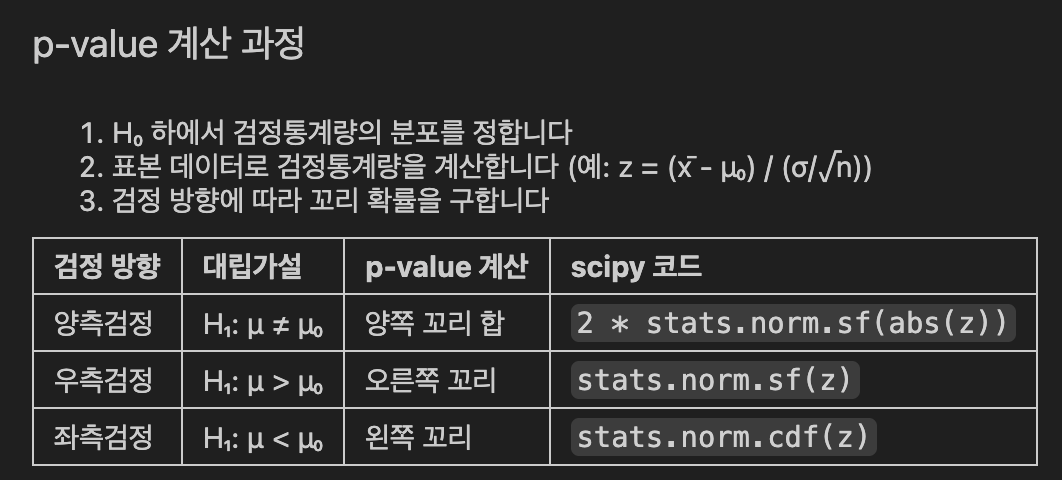
- p-value : 귀무가설이 참이라고 가정했을 때, 현재 관찰한 결과보다 같거나 더 극단적인 결과가 나올 확률
- H0가 맞다면, 이런 결과가 나올 확률이 얼마나 되나?
- 유의수준 (알파) : H0를 잘못 기각할 위험을 이 정도까지 감수하겠다는 사전 기준 (보통 알파 = 0.05 (5%))

- 왜 p-value가 유의수준보다 작으면 귀무가설을 기각하나요?
- p-value가 작다 = 귀무가설이 맞다는 가정에서 이런 결과가 나올 가능성이 매우 낮음
- ex) p-value = 0.01(1%) -> 100번 중 1번만 발생하는 드문 결과 -> 귀무가설을 의심해야함
- 따라서 '이 결과는 우연이 아니다'라고 판단하고 -> 귀무가설을 기각함
- 기각 실패와 채택은 다름!
- 올바른 표현 : 귀무가설 기각 실패, 대립가설 증거 불충분
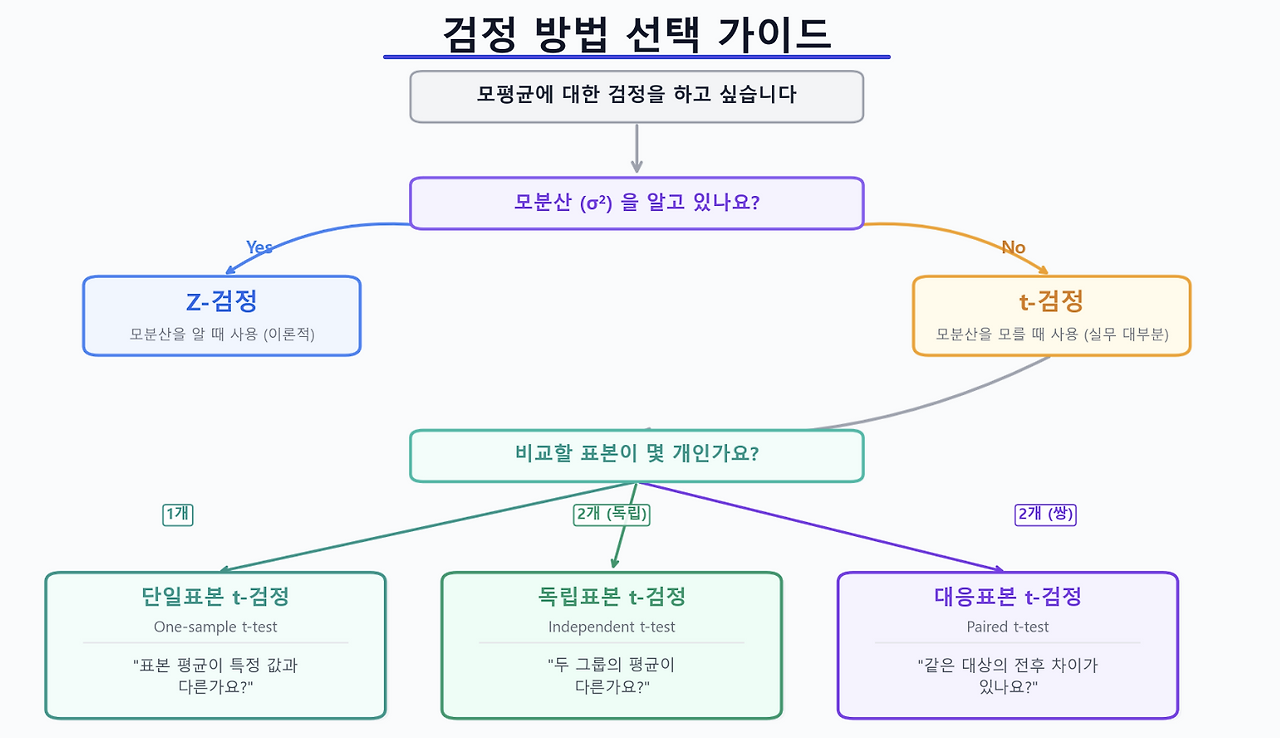
- 검정 방법 선택 가이드
| 조건 | 검정 방법 | scipy.stats 함수 |
| 모분산을 아는 경우 (안씀) | z-검정 | statsmodels.stats.weightstats |
| 1개 표본, 모분산 모름 | 단일표본 t-검정 | stats.ttest_1samp(data, mu0) |
| 2개 독립 표본, 모분산 모름 | 독립표본 t-검정 | stats.ttest_ind(a, b) |
| 2개 짝지은(전후) 표본 | 대응표본 t-검정 | stats.ttest_rel(before, after) |
- z-검정 (Z-test)
- 모분산을 아는 경우 모평균을 검정하는 방법 (실무에서는 매우 드묾)
# z-검정 실습 (수동 구현)
print("\n" + "=" * 60)
print("Part 5.1: z-검정")
print("=" * 60)
print("\n[시나리오]")
print("전구 수명이 평균 1000시간이라고 알려져 있습니다. (σ = 50시간)")
print("새 공정으로 생산한 전구 36개의 평균 수명이 1015시간이었습니다.")
print("새 공정이 수명을 늘렸나요?")
mu_0 = 1000 # 귀무가설 하의 모평균
sigma = 50 # 알려진 모표준편차
n = 36
xbar = 1015
print(f"\nH0: μ = {mu_0}") # 귀무가설 : 모집단의 평균이 1000시간 (현상유지)
print(f"H1: μ > {mu_0} (우측검정)") # 대립가설 : 모집단의 평균이 1000시간 이상이다
# TODO: z 검정통계량 계산 (xbar - mu_0) / (sigma / sqrt(n))
z_stats = (xbar - mu_0) / (sigma / np.sqrt(n))
# TODO: p-value 계산 (우측검정: stats.norm.sf(z_stat))
p_value = stats.norm.sf(z_stats)
# TODO: 결과 출력 및 판정 (α = 0.05)
a = 0.06
if p_value < a:
print(f"{p_value}, 귀무가설 기각") # 95% 신뢰수준 - 새로운 공정은 1000시간 이상이다
else:
print(f"{p_value}, 귀무가설 기각 실패")
# 시각화: z-검정 결과
z_stat = (xbar - mu_0) / (sigma / np.sqrt(n))
p_value = stats.norm.sf(z_stat)
fig, ax = plt.subplots(figsize=(10, 5))
x = np.linspace(-4, 5, 1000)
y = stats.norm.pdf(x)
ax.plot(x, y, 'k-', linewidth=1.5, label='H0 하에서의 분포')
ax.fill_between(x[x >= z_stat], y[x >= z_stat], alpha=0.4, color='#DC2626',
label=f'p-value = {p_value:.4f}')
ax.axvline(z_stat, color='#DC2626', linestyle='--', linewidth=2,
label=f'z = {z_stat:.2f}')
ax.axvline(1.645, color='#D97706', linestyle=':', linewidth=1.5,
label=f'기각역 (z = 1.645)')
ax.set_title('z-검정: 전구 수명 검정 (우측검정)', fontsize=14, fontweight='bold')
ax.set_xlabel('z 값', fontsize=12)
ax.set_ylabel('확률 밀도', fontsize=12)
ax.legend(fontsize=10)
ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()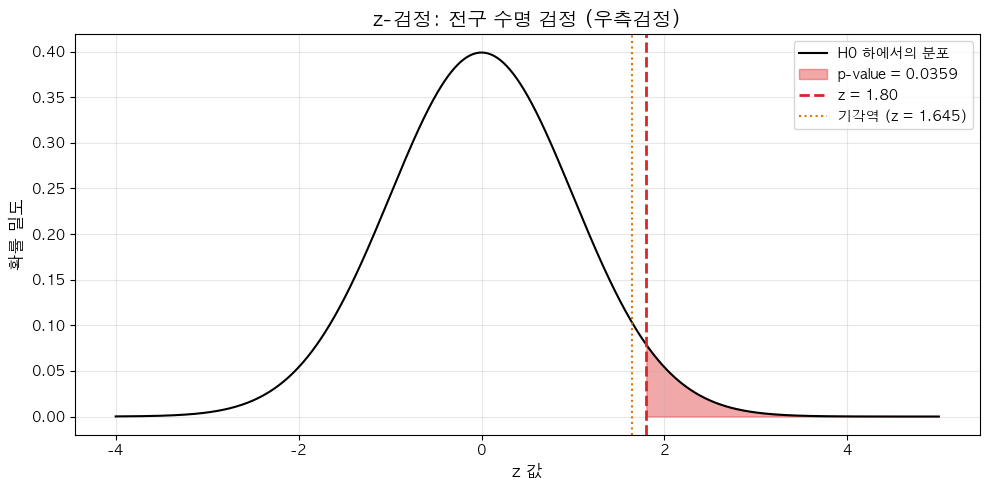
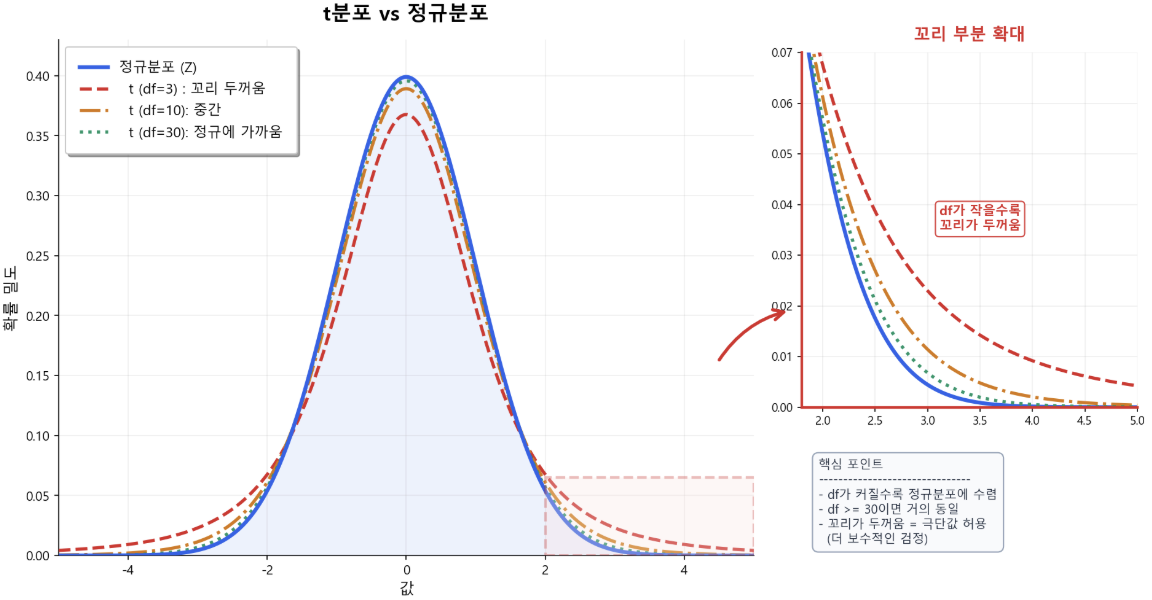
- t-검정 (t-test)
- 모분산을 모를 때 사용하는 검정 방법 - 실무에서 가장 많이 사용
- 정규분포와 비슷 (종 모양, 좌우 대칭)
- 꼬리가 더 두꺼움 (정규분포보다 극단값이 나올 확률이 높음 -> 더 보수적)
- 자유도(df)에 따라 변화 (df가 커질수록 정규분포에 가까워짐)
- df=n-1(단일표본) (표본크기에서 1을 빼서 자유도 결정)
- 단일표본 t-검정
- 하나의 표본 평균이 특정 값과 다른가?
- 사용 예시
- 제품 중량이 규격(500g)과 다른가?
- 학생 평균 점수가 전국 평균(70점)과 다른가?
print("\n" + "=" * 60)
print("Part 5.2.1: 단일표본 t-검정")
print("=" * 60)
print("\n[시나리오1] A 지역 성인 혈압 검정")
print("=" * 50)
print("A 지역은 건강 프로그램을 운영 중입니다.")
print("이 지역 성인 20명의 수축기 혈압을 측정하여")
print("전국 평균(130mmHg)보다 낮은지 검정합니다.")
np.random.seed(123)
bp_data = np.random.normal(loc=122, scale=12, size=20)
print(f"\n데이터: {np.round(bp_data, 1)}")
print(f"표본평균: {np.mean(bp_data):.2f} mmHg")
print(f"표준편차: {np.std(bp_data, ddof=1):.2f} mmHg")
print("\n[1단계] 가설 설정")
print(" H0: μ = 130 (전국 평균과 같다)")
print(" H1: μ < 130 (전국 평균보다 낮다) → 좌측검정")
alpha = 0.05
print(f"\n[2단계] 유의수준: α = {alpha}")
# ── 단일표본 t-검정 (one-sample t-test) ──
# 검정통계량: t = (x̄ - μ₀) / (s / √n)
# TODO: 표본크기 n, 귀무가설 모평균 mu_0 설정
n = len(bp_data)
mu_0 = 130
# TODO: 표본평균 x̄, 표본표준편차 s(ddof=1), 표준오차 SE 계산
xbar = np.mean(bp_data)
s = np.std(bp_data, ddof=1)
se = s / np.sqrt(n)
# TODO: 검정통계량 t 계산
t_stat = (xbar - mu_0) / se
# TODO: 자유도 df = n - 1
df = n-1
# TODO: p-value 계산
p_value = stats.t.cdf(t_stat, df)
# TODO: 결과 출력
print(p_value)
# TODO: p-value와 α 비교하여 결론 출력
# a = 0.05인 경우 귀무가설 기각
# ── scipy.stats로 검증 ──
# TODO: stats.ttest_1samp(bp_data, popmean=130) 으로 검증
# 주의: ttest_1samp은 양측 p-value를 반환합니다
# 좌측 변환: p_좌측 = p_양측/2 (t < 0일 때)
# TODO: 수동 계산 결과와 비교 출력
t_stat, p_value = stats.ttest_1samp(bp_data, popmean=130)
print(t_stat, p_value/2) # -1.9640757484281774 0.03216088466869512
print("\n[시나리오2] 커피 용량 품질 관리")
print("자판기 커피의 목표 용량: 200ml")
print("15잔을 측정했을 때, 규격에 맞는지 검정합니다")
np.random.seed(42)
coffee_ml = np.random.normal(loc=197, scale=5, size=15)
print(f"\n측정값: {np.round(coffee_ml, 1)}")
print(f"표본평균: {np.mean(coffee_ml):.2f}ml")
print(f"표본표준편차: {np.std(coffee_ml, ddof=1):.2f}ml")
# 가설
mu_0 = 200
print(f"\nH0: μ = {mu_0}ml (규격에 맞음)")
print(f"H1: μ ≠ {mu_0}ml (규격에 안 맞음) → 양측검정")
# TODO: scipy.stats로 단일표본 t-검정 (stats.ttest_1samp)
t_stat, p_value = stats.ttest_1samp(coffee_ml, popmean=200)
# TODO: 결과 출력 (t-통계량, 자유도, p-value)
# TODO: p-value와 α 비교하여 결론 출력
print(t_stat, p_value) # -2.2971353602418363 0.03755367064738339, 귀무가설 기각
# TODO: H0 기각 시 95% 신뢰구간도 계산하여 출력
ci = stats.t.interval(0.95, df=len(coffee_ml)-1, loc=np.mean(coffee_ml), scale=stats.sem(coffee_ml))
print(ci) # (np.float64(194.29901708052174), np.float64(199.80446816281156))- p-value=0.037 < 0.05여서 귀무가설을 기각할 수 있다.
- 규격이란 기준은 200ml이고 이는 신뢰구간 (194.30, 199.80) 밖에 존재함 따라서 이 자판기는 평균적으로 200ml를 배출하지 않는다는 주장은 통계적으로 타당함
- 하지만 상한선이 199.8임. 목표치와 단 0.2ml 차이이고, 이에 대한 해석으론
- 95%의 확신을 가지고 말하건대, 이 자판기는 아무리 많이 나와봐야 199.80ml 근처라는 뜻임
- 독립표본 t-검정
- 두 독립적인 그룹의 평균이 다른가?
- 사용 예시
- a반과 b반의 시험 점수 차이가 유의한가?
- 남녀의 평균 급여 차이가 있나요?
- 실험군과 대조군의 효과 차이
print("\n[시나리오] 두 학습법의 효과 비교")
print("A법(전통 강의)과 B법(플립 러닝)으로 각각 수업 후 시험 점수 비교")
np.random.seed(42)
group_a = np.random.normal(loc=72, scale=10, size=25) # A법
group_b = np.random.normal(loc=78, scale=12, size=30) # B법
print(f"\nA법 (전통 강의): n={len(group_a)}, 평균={np.mean(group_a):.2f}, "
f"SD={np.std(group_a, ddof=1):.2f}")
print(f"B법 (플립 러닝): n={len(group_b)}, 평균={np.mean(group_b):.2f}, "
f"SD={np.std(group_b, ddof=1):.2f}")
# 시각화: 두 그룹 비교
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# 히스토그램 비교
axes[0].hist(group_a, bins=12, alpha=0.6, color='#2563EB', edgecolor='white', label='A법 (전통)')
axes[0].hist(group_b, bins=12, alpha=0.6, color='#059669', edgecolor='white', label='B법 (플립)')
axes[0].axvline(np.mean(group_a), color='#2563EB', linestyle='--', linewidth=2)
axes[0].axvline(np.mean(group_b), color='#059669', linestyle='--', linewidth=2)
axes[0].set_xlabel('시험 점수')
axes[0].set_ylabel('빈도')
axes[0].set_title('두 그룹의 점수 분포', fontsize=12, fontweight='bold')
axes[0].legend(fontsize=10)
# 박스플롯
data_box = pd.DataFrame({'A법 (전통)': pd.Series(group_a), 'B법 (플립)': pd.Series(group_b)})
data_box.boxplot(ax=axes[1], patch_artist=True,
boxprops=dict(facecolor='lightblue'),
medianprops=dict(color='red', linewidth=2))
axes[1].set_ylabel('시험 점수')
axes[1].set_title('그룹별 점수 비교', fontsize=12, fontweight='bold')
plt.tight_layout()
plt.show()
# 가설
print(f"\nH0: μA = μB (두 학습법의 효과가 같다)")
print(f"H1: μA ≠ μB (두 학습법의 효과가 다르다)")
# 독립표본 t검정
# 1) 두 집단의 분산이 동일할 때: student's t검정
# 2) 두 집단의 분산이 다를 때: Welch's t-test검정
# 일반적으로 다르고, 같다하더라도 Welch's t-test검정으로 해도 큰 차이가 없음
# 현대 통계학에서는 무조건 Welch's t-test 검정을 한다!
# TODO: Welch's t-test 수행
t_stat, p_value = stats.ttest_ind(group_a, group_b, equal_var=False) # equal_var: 두 그룹의 분산이 같은지 유무
# 유의수준 a = 0.05
print(p_value)
# 결과 : 귀무가설 기각 실패
# ── 등분산 검정 ──
# H0: 두 그룹의 분산이 같다 (등분산)
# H1: 두 그룹의 분산이 다르다 (이분산)
# p-value가 크다 → H0을 기각하지 못한다 → "분산이 같다"를 유지 → 등분산
# - Levene 검정: 정규성 가정이 필요 없음 (더 안전, 일반적으로 권장)
# - Bartlett 검정: 정규성을 가정함 (데이터가 정규분포일 때 더 정확)
lev_stat, lev_p = stats.levene(group_a, group_b)
bar_stat, bar_p = stats.bartlett(group_a, group_b)
print("[등분산 검정]")
print(f" Levene: F = {lev_stat:.4f}, p-value = {lev_p:.4f}")
print(f" Bartlett: χ² = {bar_stat:.4f}, p-value = {bar_p:.4f}")
# H0: 두 그룹의 분산이 같다
# p > 0.05 → 등분산 가정 가능 → equal_var=True (Student's t-test)
# p ≤ 0.05 → 등분산 가정 불가 → equal_var=False (Welch's t-test)
if lev_p > 0.05:
print(" → 등분산 가정 가능 (Student's t-test)")
else:
print(" → 등분산 가정 불가 (Welch's t-test 사용)")
- 대응표본 t-검정
- 같은 대상의 전후 차이가 유의한가?
- 사용 예시
- 다이어트 전후 체중 변화
- 교육 프로그램 전후 점수 변화
- 약물 복용 전후 혈압 변화
독립표본 vs 대응표본: 같은 사람의 전후 비교 -> 대응표본, 서로 다른 사람 비교 -> 독립표본
print("\n" + "=" * 60)
print("Part 5.2.3: 대응표본 t-검정")
print("=" * 60)
print("\n[시나리오] 다이어트 프로그램 효과 검증")
print("12명이 8주간 다이어트 프로그램에 참여")
print("프로그램 전후 체중(kg)을 비교")
np.random.seed(42)
n_people = 12
before = np.random.normal(loc=80, scale=8, size=n_people)
weight_loss = np.random.normal(loc=2, scale=3, size=n_people)
after = before - weight_loss
print(f"\n{'대상':>6} {'전(kg)':>10} {'후(kg)':>10} {'차이(kg)':>10}")
print("-" * 40)
for i in range(n_people):
diff = after[i] - before[i]
print(f" {i+1:>3d} {before[i]:>8.1f} {after[i]:>8.1f} {diff:>8.1f}")
differences = after - before
print(f"\n차이(d = 후 - 전)의 평균: {np.mean(differences):.2f} kg")
print(f"차이의 표준편차: {np.std(differences, ddof=1):.2f} kg")
[ 오후 통계학 이론 세션 ]
https://myun0506.tistory.com/99
통계학 세션 이론 4일차 (가설검정 심화)
[ 오후 통계학 이론 세션 ] - 신뢰구간신뢰구간 CI = 표본평균 +- (신뢰계수 * s/(n**2)표본수가 많아질수록 신뢰구간은 점점 더 좁고 정교해짐 -> 더 정확하게 예측할 수 있음 - 예언구간 vs 신뢰구간
myun0506.tistory.com
- 신뢰구간

- 신뢰구간 CI = 표본평균 +- (신뢰계수 * s/(n**2)
- 표본수가 많아질수록 신뢰구간은 점점 더 좁고 정교해짐 -> 더 정확하게 예측할 수 있음

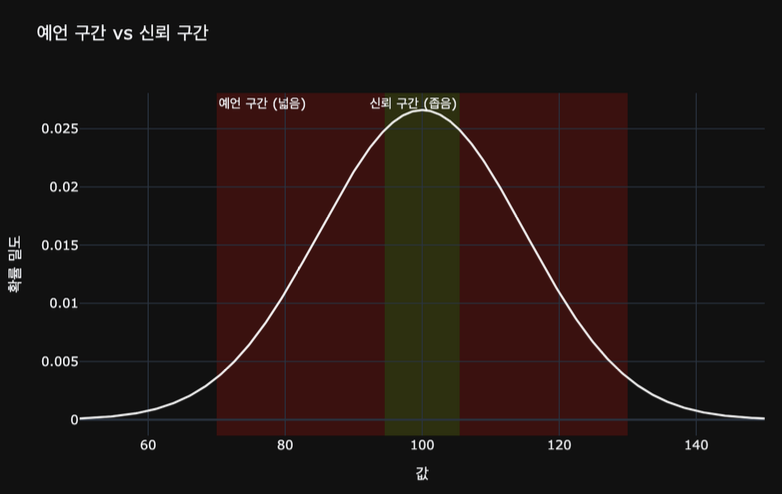
- 예언구간 vs 신뢰구간
- 예언 구간
- 다음 값 하나를 예측하는 범위
- ex) 내일 들어올 손님 한 명의 결제 금액
- 값 하나는 들쭉날쭉 --> 구간이 넓음
- 신뢰 구간
- 모집단 평균을 추정하는 범위
- ex) 고객 전체 평균 결제금액
- 평균은 안정적 --> 구간이 좁음
- 판정규칙
- p<=alpha -> H0 기각
- 효과없음 세계에서는 드문 결과 --> 유의미
- p>alpha -> H0 기각 못함 (보류)
- 효과없음 세계에서도 흔히 발생
- H0를 증명한게 아님, 단지 버릴 근거 부족
- 실무 연결
- A/B 테스트
- H0: 두 버튼 클릭률 같음
- 데이터: 차이=3%, p=0.018<0.05 --> H0 기각 ( 두 버튼 클릭률 차이 있음)
- 품질 관리
- H0: 신공정 불량률이 기존과 같음
- 데이터: 차이 큼, p=0.001<0.05 --> H0 기각 (공정이 달라졌다고 판단)
- A/B 테스트
- 표본 개수에 따른 p-value 크기 비교

1. 표본이 많을수록 (n ↑ → SE ↓):
- 분모인 불확실성(SE)이 작아짐
- 똑같은 차이라도 분모가 작아지니 전체값인 t(검정통계량)는 커짐
- t값이 커지면 분포의 꼬리쪽으로 멀리 밀려나므로, 그 바깥 면적인 p-value는 매우 작아짐
- 결과적으로 작은 차이도 실제 효과일 가능성이 높다고 판정(유의함)하게 됨
2. 표본이 적을수록 (n ↓ → SE ↑):
- 분모인 불확실성이 커져서 t값이 작아짐
- t값이 중심에 가까워지면 p-value는 커짐
- 결론적으로 이 정도 차이는 우연히 발생할 수 있는 오차범위 내에 있다고 보수적으로 판단(유의하지 않음)하게 됨
3. 생활 비유
- 운동 경기
- A팀 80점, B팀 78점
- 점수 들쭉날쭉 (SE큼) -> 2점 차이, 우연일 수도?
- 점수 안정적 (SE작음) -> 2점 차이도 의미있음
- 시험 점수
- 반 A 평균 85, 반 B 평균 80
- 표본 적어서 점수 들쭉날쭉 -> 5점 차이, 우연일 수도?
- 표본 많아서 점수 안정적 -> 5점 차이도 의미있음
- 분산이 크면 차이가 불확실
- 분산이 작으면 같은 차이도 더 신뢰
4. 실무 연결
- A/B 테스트
- 클릭률 5.1% vs 4.8%
- n=수천 -> SE 작음 -> 0.3% 차이도 유의미
- n=수십 -> SE 큼 -> 0.3% 차이 우연일 수도
- 신약 임상시험
- 혈압 감소: 신약 -10 vs 위약 -2
- n이 많으면 유의미, n이 적으면 애매
- 신뢰구간과 가설검정의 관계
- 두 집단 평균차(µA-µB)의 95% 신뢰구간이 0을 포함하지 않으면 -> 귀무가설 기각 (p<0.05 (양측)와 동치)
1. 생활 비유
- 신뢰구간 = 지도
- 우리집이 이 동네 어디쯤 있다라고 영역을 그려줌
- 가설검정 = GPS 경보
- 만약 집이 이 좌표(0)라면, 내가 지금 있는 곳은 너무 멀리 벗어났다 (p<0.05) 라고 알려주는 것
2. 실무 연결
- A/B 테스트 중간 보고
- 신뢰구간: 전환율 차이 1%p~3%p, 0 포함 안됨
- 검정: p=0.012 -> 귀무가설 기각
- 임상시험
- 신뢰구간: 혈압 감소 효과 5~12mmHg (0 포함 안 됨)
- 검정: p=0.004 -> 유의
- -> 같은 결론을 다른 언어로 표현
- 검정 방법 정하기
1. 변수 유형 (데이터 종류)
- 수치형 변수(양적) : 점수, 키, 몸무게, 매출액
- 평균/분산으로 비교
- 범주형 변수(질적) : 남/여, 광고 클릭/비클릭, 제품 A/B/C
- 개수/비율로 비교
2. 표본 수 (집단 몇 개?)
- 1표본: 한 집단 vs 기준값
- 우리반 평균 키 = 170cm?
- 2표본
- 독립: 남 vs 여
- 대응: 같은 사람 전/후 비교 (다이어트 전/후 체중)
- 3집단 이상: A/B/C 조건 비교
- 비료 종류에 따른 성장 차이?
3. 분포 성질 (수치형일때만)
- 정규성? -> 종 모양인가? (Q-Q plot, histogram, K-S test, Shapiro-Wilk)
- 등분산성? -> 집단 간 퍼짐이 비슷한가? (Levene test, Bartlett test)
- 이상치/비대칭? -> 불리하다면 비모수 검정 고려
- 상황별 비모수검정 방법

- 비모수는 "평균 차이"가 아니라 위치(중앙값)/순위 차이를 본다
- 비모수 = 단순한 버전 아님!!!!
- -> 평균 대신 순위/위치 비교 (질문 자체가 다름)
- 정규성 p>=0.05면 무조건 t검정 아님!!!!
- -> 이상치나 치우침 있으면 비모수가 안전

- ANOVA
- F분포
- F값: ANOVA에서 사용하는 검정통계량
- 집단 간 분산 / 집단 내 분산 -> 이 비율이 클수록 집단 간 차이가 크다
- 이렇게 계산된 F값은 F분포라는 확률분포를 따름
- F분포: 두개의 독립적인 카이제곱 분포의 비율로 만들어지는 분포
- ANOVA 외에도 회귀분석, 분산비교 등 다양한 검정에서 사용됨
- ANOVA는 3개 이상 집단의 평균 차이를 한번에 검정할 수 있는 방법이며 분산 구조를 분석함으로써 평균 차이를 판단!
- F값: ANOVA에서 사용하는 검정통계량
- F 분포와 기각역
- F 분포 오른쪽 꼬리 영역이 기각역
- 관측된 F값이 임계값 (F critical) 을 넘으면 -> p<0.05 -> H0 기각
- 넘지 못하면 -> H0 기각 못함

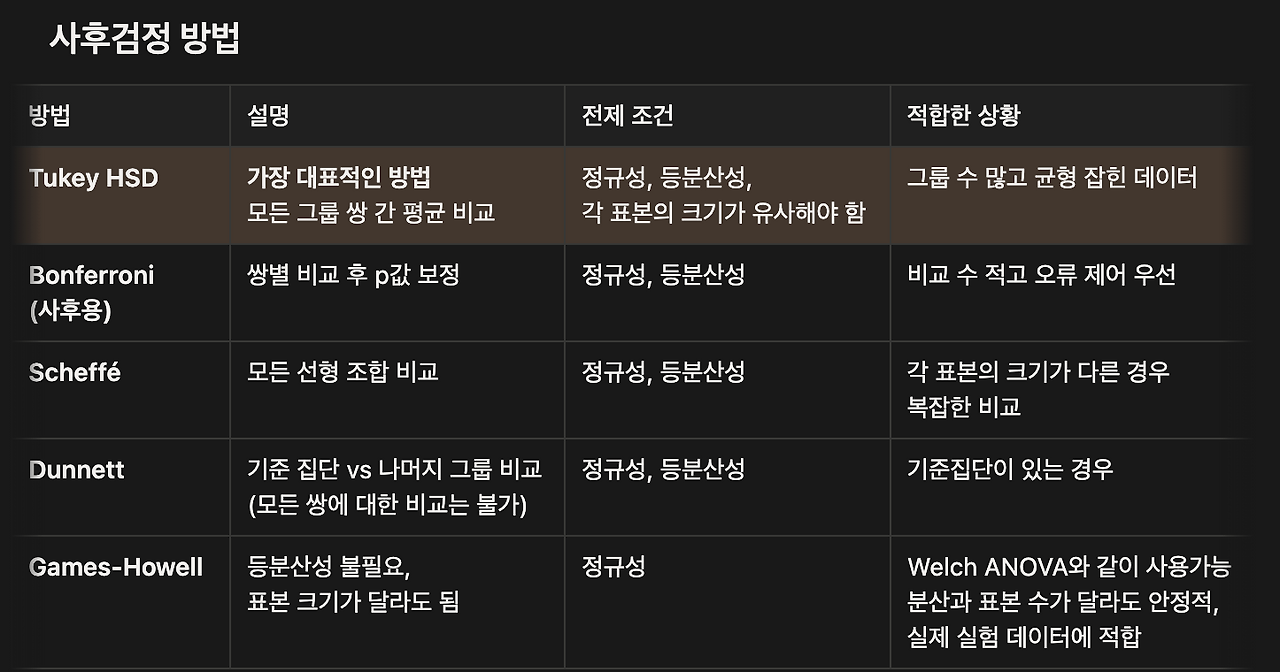
- 사후 검정 필요성
- ANOVA 유의 (p<0.05) -> 적어도 한 쌍이 다르다
- 하지만 어느 쌍이 다른지는 알려주지 않음
- 따라서 사후 검정 필요
- Tukey HSD: 모든 쌍 비교
- Dunnett: 대조군 vs 여러 실험군
- Williams: 용량-반응 패턴에서 유리

- 비율/범주형 - 평균 대신 확률 비교
- 범주형 데이터는 평균이 아니라 확률이 주인공
- 이항검정: 한 범주 비율이 기준과 같은가?
- 적합도검정: 전체 분포가 기준 분포와 같은가?
- 독립성검정: 두 범주형 변수가 서로 연관 있는가?
- 정규성
- Shapiro-Wilk
- H0 = 정규분포, p>=0.05 -> 정규 아님이라 말할 근거 부족
- Q-Q plot
- 데이터 분위수와 정규분포 분위수를 짝지어 점으로 그림
- 점들이 대각선 직선 근처면 정규에 가까움
- Shapiro-Wilk
- 등분산성
- Levene / Bartlett
- 위배시 대안
- 2집단: Welch t
- 3집단 이상: Welch ANOVA
- 문제 5.


[ 통계학 기초 vod 강의 ]
- 중심극한정리
- 모집단의 분포 형태와 상관없이, 독립적인 확률 변수 n개의 표본 평균은 표본의 크기(n)가 충분히 커질수록(보통 n>=30) 정규분포에 근사하게 수렴한다는 통계학의 핵심 정리
- 정규분포
# 정규분포 생성
normal_dist = np.random.normal(170, 10, 1000)
# 히스토그램으로 시각화
plt.hist(normal_dist, bins=30, density=True, alpha=0.6, color='g')
# 정규분포 곡선 추가
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p = stats.norm.pdf(x, 170, 10) # 평균 170, 표준편차 10
plt.plot(x, p, 'k', linewidth=2)
plt.title('normal distribution histogram')
plt.show()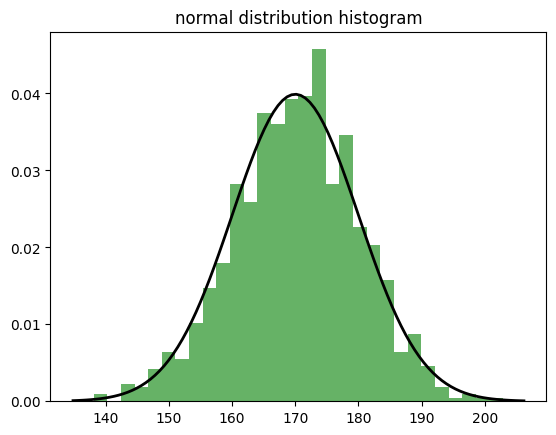
- 긴 꼬리 분포 Long Tail Distribution
- 대칭부터가 아님.
- 대부분의 분포가 한쪽 끝에 몰려있고, 반대쪽으로 긴 꼬리가 이어지는 형태의 분포
- 파레토 분포, 지프의 법칙, 멱함수를 포함.....
- 아무리 데이터가 많아져도 정규분포가 되지 않음!
# 긴 꼬리 분포 생성 (e.g. 소득 데이터)
long_tail = np.random.exponential(1, 1000)
# 히스토그램으로 시각화
plt.hist(long_tail, bins=30, density=True, alpha=0.6, color='b')
plt.title('long tail distribution histogram')
plt.show()
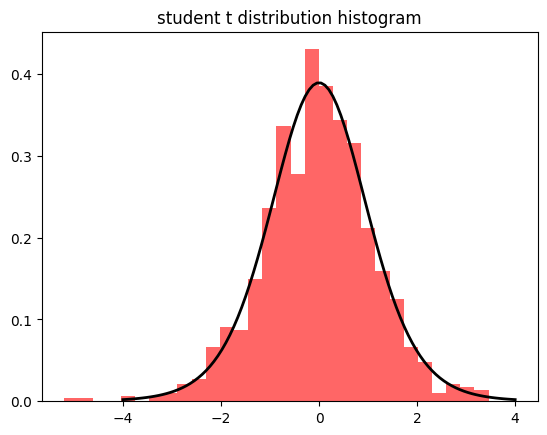
- 스튜던트 t 분포
- 일반적으로는 정규분포를 사용하는데, 데이터가 적을 경우 정규분포 대신 사용하는 분포
- 정규분포와 유사하지만 표본의 크기가 작을수록 꼬리가 두꺼워짐
- 아래 그래프에서 v(뉴)는 자유도를 나타내는 문자

# 스튜던트 t 분포 생성
t_dist = np.random.standard_t(df=10, size=1000)
# 히스토그램으로 시각화
plt.hist(t_dist, bins=30, density=True, alpha=0.6, color='r')
# 스튜던트 t 분포 곡선 추가
x = np.linspace(-4, 4, 100)
p = stats.t.pdf(x, df=10)
plt.plot(x, p, 'k', linewidth=2)
plt.title('student t distribution histogram')
plt.show()- df(Degree of Freedom): 분포의 모양을 결정하는 결정적인 파라미터. 꼬리가 얼마나 두꺼울지, 정규분포에 얼마나 가까울지를 결정하는 확률분포의 고유 성질
- size: 그 분포에서 몇개의 표본을 추출할 것인가에 대한 시행 횟수
- 카이제곱 분포

- 여기서 k 값은 자유도
- 카이제곱분포는 범주형 데이터의 독립성 검정이나 적합도 검정에 사용되는 분포
- 특징
- 자유도에 따라 모양이 달라짐
- 상관관계나 인과관계를 판별하고자 하는 원인의 독립변수가 '완벽하게 서로 다른 질적 자료'일 때 활용
- ex) 성별이나 나이에 따른 선거 후보 지지율
- 범주형 데이터 분석에 사용
- 실제 사용 사례
- 독립성 검정
- 두 범주형 변수 간의 관계가 있는지 확인할 때 사용됨
- ex) 성별과 직업 선택간의 독립성 검토
- 혹은, 성별이 후보 지지율에 영향을 끼치는지 검토
- 적합도 검정
- 관측한 값들이 특정 분포에 해당하는지 검정
- ex) 주사위의 각 면이 동일한 확률로 나오는지 검토
- 노란색 완두와 녹색완두가 3:1의 비율로 나와야하는데 실험적으로 측정한 데이터가 그렇게 나오는지 검토
- 독립성 검정
# 카이제곱분포 생성
chi2_dist = np.random.chisquare(df=2, size=1000)
# 히스토그램으로 시각화
plt.hist(chi2_dist, bins=30, density=True, alpha=0.6, color='m')
# 카이제곱분포 곡선 추가
x = np.linspace(0, 10, 100)
p = stats.chi2.pdf(x, df=2)
plt.plot(x, p, 'k', linewidth=2)
plt.title('chisquare distribution')
plt.show()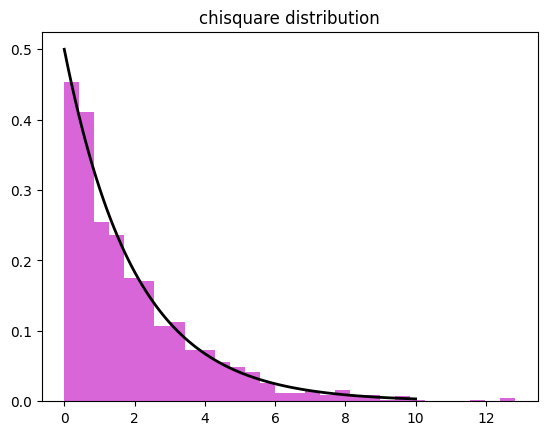
'[데이터분석] 부트캠프 TIL' 카테고리의 다른 글
| 20260211 TIL (0) | 2026.02.11 |
|---|---|
| 20260210 TIL (0) | 2026.02.10 |
| 20260206 TIL (0) | 2026.02.06 |
| 20260205 TIL (0) | 2026.02.05 |
| 20260204 TIL (0) | 2026.02.04 |