[Today I Learn]
- Python codekata
- 오전 통계학 실습 세션
- 오후 통계학 이론 세션
[Python codekata]
- 문제 1.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120841?language=python3
2. 정답 코드
def solution(dot):
if dot[0] < 0:
if dot[1] < 0:
return 3
else:
return 2
else:
if dot[1] < 0:
return 4
else:
return 1def solution(dot):
x,y = dot
if x*y>0:
return 1 if x>0 else 3
else:
return 4 if x>0 else 2
- 문제 2.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120903?language=python3
2. 정답 코드
def solution(s1, s2):
cnt = 0
for s in s2:
for a in s1:
if s == a:
cnt += 1
return cntdef solution(s1, s2):
cnt = 0
for w in s1:
if w in s2:
cnt+=1
return cnt
def solution(s1, s2):
return len(set(s1)&set(s2));[ 오전 통계학 실습 세션 ]
- 왜 표본분산은 N이 아니라 N-1로 나눌까? (베셀 보정)

- 모평균 뮤는 전체 모집단의 중심이므로 표본 데이터들과 더 멀 수 있음
- -> 표본평균으로 분산을 구하면 모평균으로 구한 분산보다 더 작아짐




- 변동계수 (CV) - 산대적 산포
- 변동계수는 표준편차를 평균으로 나눈 값으로, 데이터의 상대적인 퍼짐 정도를 나타냄



print("\n" + "="*60)
print("Part 5.1: 변동계수 (CV) - 상대적 산포")
print("="*60)
# (1) 변동계수 계산 함수
def cv(data):
"""변동계수(%) 계산"""
return data.std() / data.mean() * 100
# (2) 문제 1: 단위가 다른 변수 비교 - Iris 데이터 활용
print("\n[1. 단위가 다른 변수 비교]")
print("Iris 데이터: 꽃잎 길이(cm) vs 꽃잎 너비(cm)")
print("(단위는 같지만 스케일이 다른 경우)")
petal_length = iris_df['petal length (cm)']
petal_width = iris_df['petal width (cm)']
compared_df = pd.DataFrame({
'변수':['꽃잎 길이', '꽃잎 너비'],
'평균':[petal_length.mean(), petal_width.mean()],
'표준편차':[petal_length.std(), petal_width.std()],
'CV(%)':[cv(petal_length), cv(petal_width)]
})
display(compared_df)
# (3) 문제 2: 스케일이 다른 그룹 비교 - Wine 데이터 활용
print("\n" + "-"*60)
print("[2. 스케일이 다른 변수 비교]")
print("Wine 데이터: alcohol vs malic_acid vs magnesium")
alcohol = wine_df['alcohol']
malic_acid = wine_df['malic_acid']
magnesium = wine_df['magnesium']
compared_df2 = pd.DataFrame({
'변수':['alcohol', 'malic_acid', 'magnesium'],
'평균':[alcohol.mean(), malic_acid.mean(), magnesium.mean()],
'표준편차':[alcohol.std(), malic_acid.std(), magnesium.std()],
'CV(%)':[cv(alcohol), cv(malic_acid), cv(magnesium)]
})
display(compared_df2)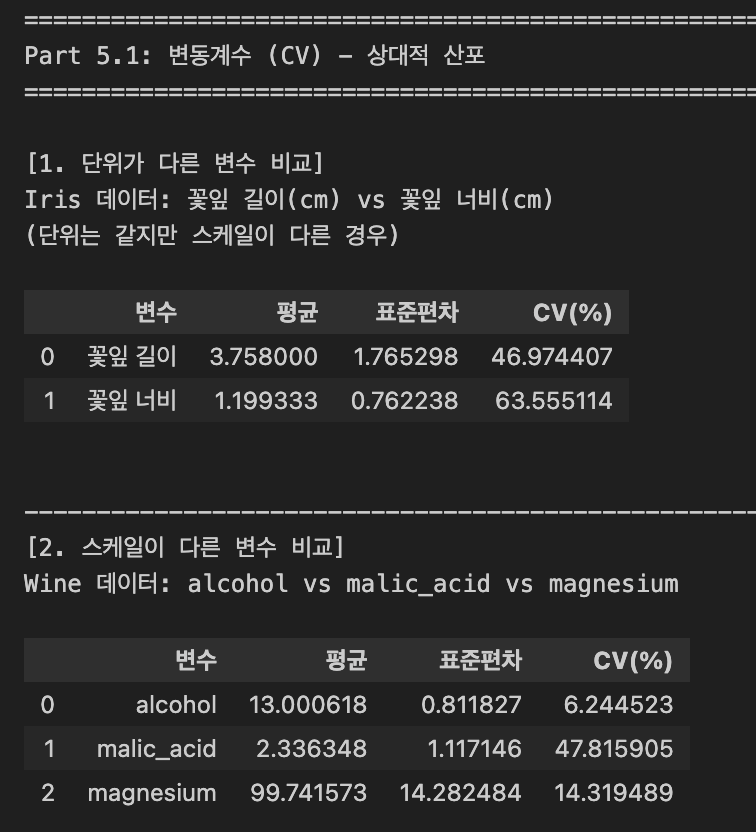
print("\n" + "="*60)
print("Part 6: 기술통계 - 데이터 분포 탐색")
print("="*60)
# Iris 꽃잎 길이를 4가지 그래프로 그리기
data = iris_df['petal length (cm)']
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# (1) 박스플롯
sns.boxplot(y=data, ax=axes[0, 0], color='lightblue', width=0.4)
axes[0, 0].set_ylabel('Petal Length (cm)')
axes[0, 0].set_title('1. 박스플롯: 5가지 요약을 한눈에', fontweight='bold')
# (2) 히스토그램
sns.histplot(data, bins=20, kde=False, color='skyblue', edgecolor='black', ax=axes[0, 1])
axes[0, 1].axvline(data.mean(), color='red', linestyle='--', linewidth=2, label=f'평균: {data.mean():.2f}')
axes[0, 1].axvline(data.median(), color='green', linestyle='--', linewidth=2, label=f'중앙값: {data.median():.2f}')
axes[0, 1].set_xlabel('Petal Length (cm)')
axes[0, 1].set_ylabel('빈도')
axes[0, 1].set_title('2. 히스토그램: 구간별 데이터 개수', fontweight='bold')
axes[0, 1].legend()
# (3) 밀도그림 (KDE)
sns.kdeplot(data, fill=True, color='steelblue', ax=axes[1, 0])
axes[1, 0].set_xlabel('Petal Length (cm)')
axes[1, 0].set_ylabel('밀도')
axes[1, 0].set_title('3. 밀도그림(KDE): 히스토그램의 부드러운 버전', fontweight='bold')
# (4) 바이올린 도표
sns.violinplot(y=data, ax=axes[1, 1], color='lightblue', inner='quartile')
axes[1, 1].set_ylabel('Petal Length (cm)')
axes[1, 1].set_title('4. 바이올린: 박스플롯 + 밀도그림 합체', fontweight='bold')
plt.suptitle('같은 데이터, 4가지 시각화', fontsize=14, fontweight='bold', y=1.02)
plt.tight_layout()
plt.show()
# 종별 분포 비교 - 그룹 간 차이를 한눈에!
print("\n" + "-"*40)
print("종별 분포 비교: 붓꽃 3종의 꽃잎 길이가 얼마나 다를까?")
print("-"*40)
fig, axes = plt.subplots(1, 3, figsize=(16, 5))
# (1) 종별 히스토그램
sns.histplot(data=iris_df, x='petal length (cm)', hue='species_name',
bins=12, alpha=0.5, edgecolor='black', ax=axes[0])
axes[0].set_xlabel('Petal Length (cm)')
axes[0].set_ylabel('빈도')
axes[0].set_title('히스토그램', fontweight='bold')
# (2) 종별 박스플롯
sns.boxplot(data=iris_df, x='species_name', y='petal length (cm)',
palette=['lightblue', 'lightgreen', 'lightcoral'], ax=axes[1])
axes[1].set_xlabel('Species')
axes[1].set_ylabel('Petal Length (cm)')
axes[1].set_title('박스플롯: 상자 위치와 크기 비교', fontweight='bold')
# (3) 종별 바이올린
sns.violinplot(data=iris_df, x='species_name', y='petal length (cm)',
palette=['lightblue', 'lightgreen', 'lightcoral'], inner='quartile', ax=axes[2])
axes[2].set_xlabel('Species')
axes[2].set_ylabel('Petal Length (cm)')
axes[2].set_title('바이올린: 분포 형태까지 한눈에', fontweight='bold')
plt.tight_layout()
plt.show()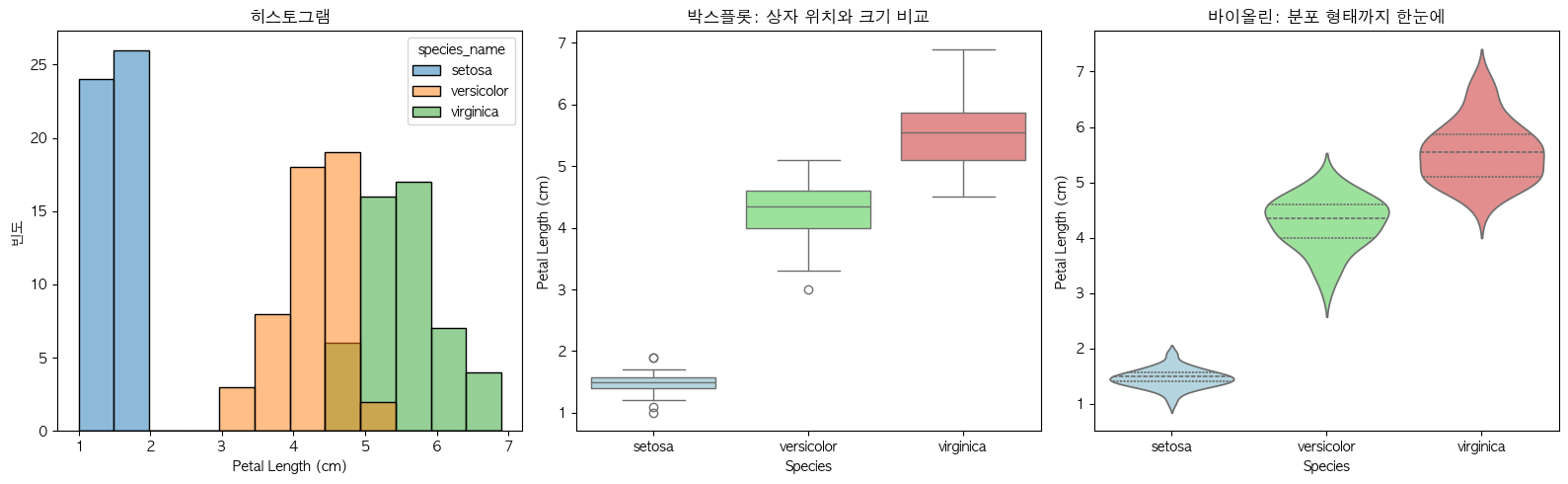
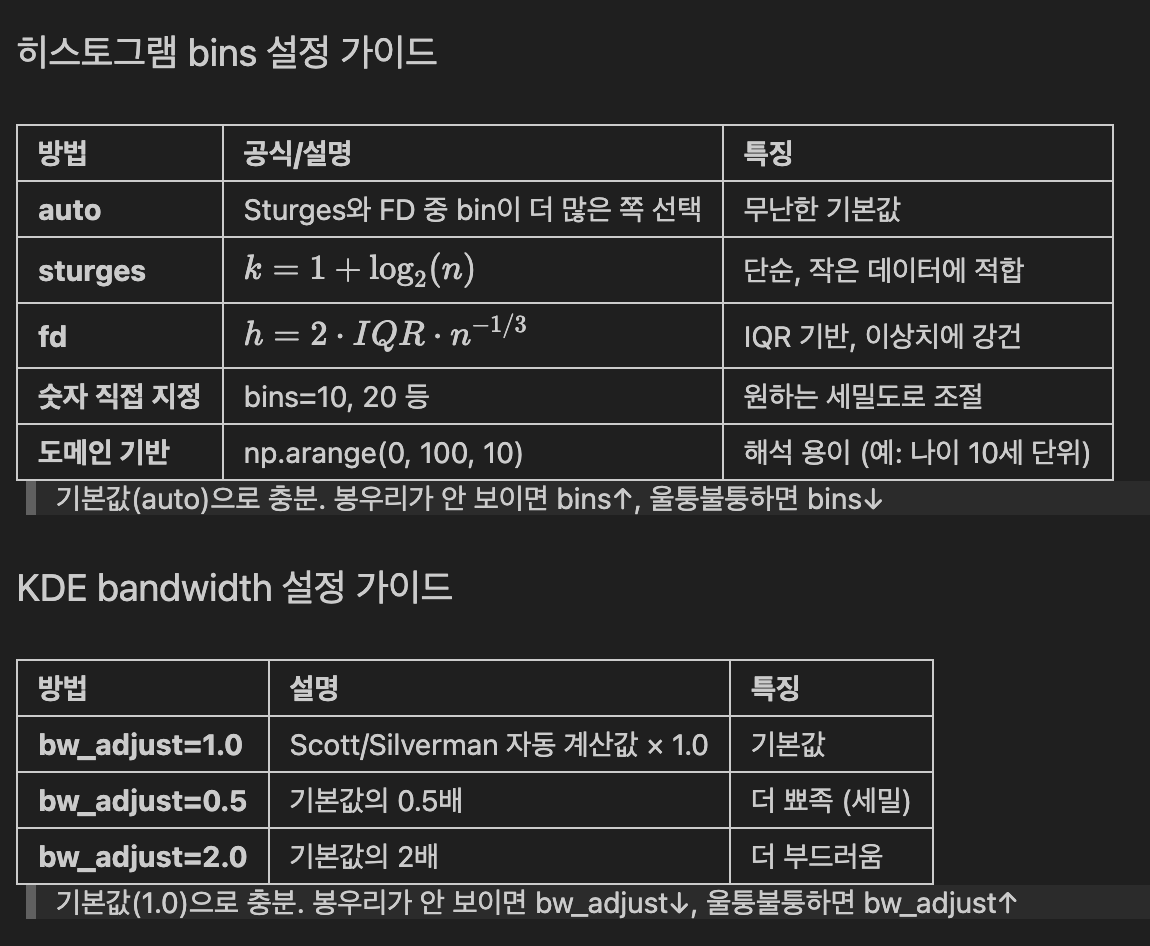
# bins 설정 방법 비교
data = iris_df['petal length (cm)']
fig, axes = plt.subplots(2, 3, figsize=(15, 8))
# (1) 자동 (기본값)
sns.histplot(data, bins='auto', ax=axes[0, 0], color='steelblue')
axes[0, 0].set_title("bins='auto' (Sturges vs FD 중 많은 쪽)", fontweight='bold')
# (2) Sturges
sns.histplot(data, bins='sturges', ax=axes[0, 1], color='steelblue')
axes[0, 1].set_title("bins='sturges'", fontweight='bold')
# (3) Freedman-Diaconis
sns.histplot(data, bins='fd', ax=axes[0, 2], color='steelblue')
axes[0, 2].set_title("bins='fd' (이상치에 강건)", fontweight='bold')
# (4) 숫자 직접 지정 - 적음
sns.histplot(data, bins=5, ax=axes[1, 0], color='steelblue')
axes[1, 0].set_title("bins=5 (너무 뭉개짐)", fontweight='bold')
# (5) 숫자 직접 지정 - 많음
sns.histplot(data, bins=30, ax=axes[1, 1], color='steelblue')
axes[1, 1].set_title("bins=30 (너무 세밀)", fontweight='bold')
# (6) 도메인 기반 - 0.5cm 단위
sns.histplot(data, bins=np.arange(0, 8, 0.5), ax=axes[1, 2], color='steelblue')
axes[1, 2].set_title("도메인 기반 (0.5cm 단위)", fontweight='bold')
plt.suptitle('bins 설정에 따른 히스토그램 변화', fontsize=14, fontweight='bold', y=1.02)
plt.tight_layout()
plt.show()
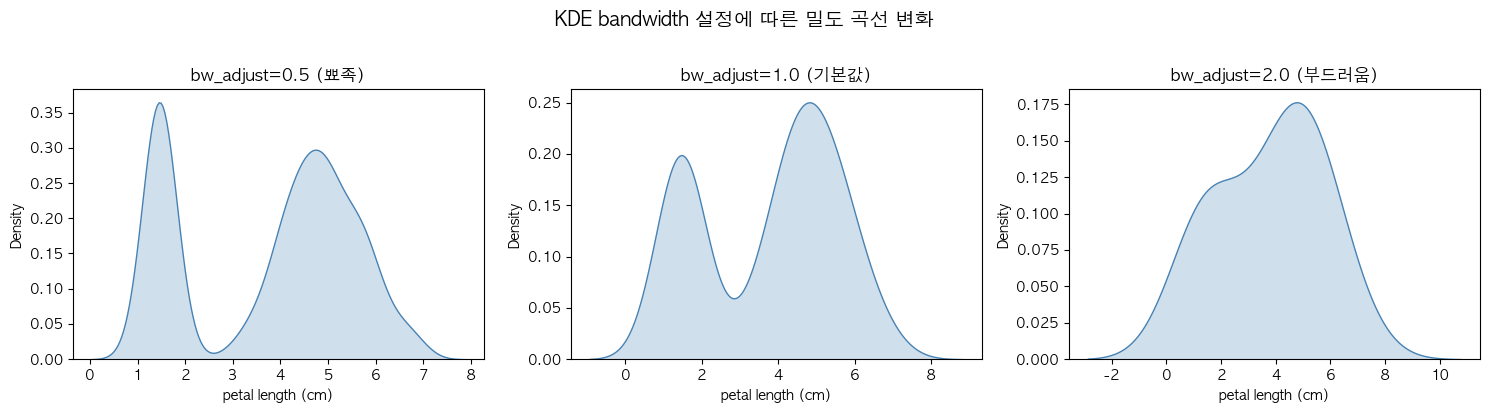
# KDE bandwidth 설정 방법 비교
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
sns.kdeplot(data, bw_adjust=0.5, ax=axes[0], fill=True, color='steelblue')
axes[0].set_title('bw_adjust=0.5 (뾰족)', fontweight='bold')
sns.kdeplot(data, bw_adjust=1.0, ax=axes[1], fill=True, color='steelblue')
axes[1].set_title('bw_adjust=1.0 (기본값)', fontweight='bold')
sns.kdeplot(data, bw_adjust=2.0, ax=axes[2], fill=True, color='steelblue')
axes[2].set_title('bw_adjust=2.0 (부드러움)', fontweight='bold')
plt.suptitle('KDE bandwidth 설정에 따른 밀도 곡선 변화', fontsize=14, fontweight='bold', y=1.02)
plt.tight_layout()
plt.show()
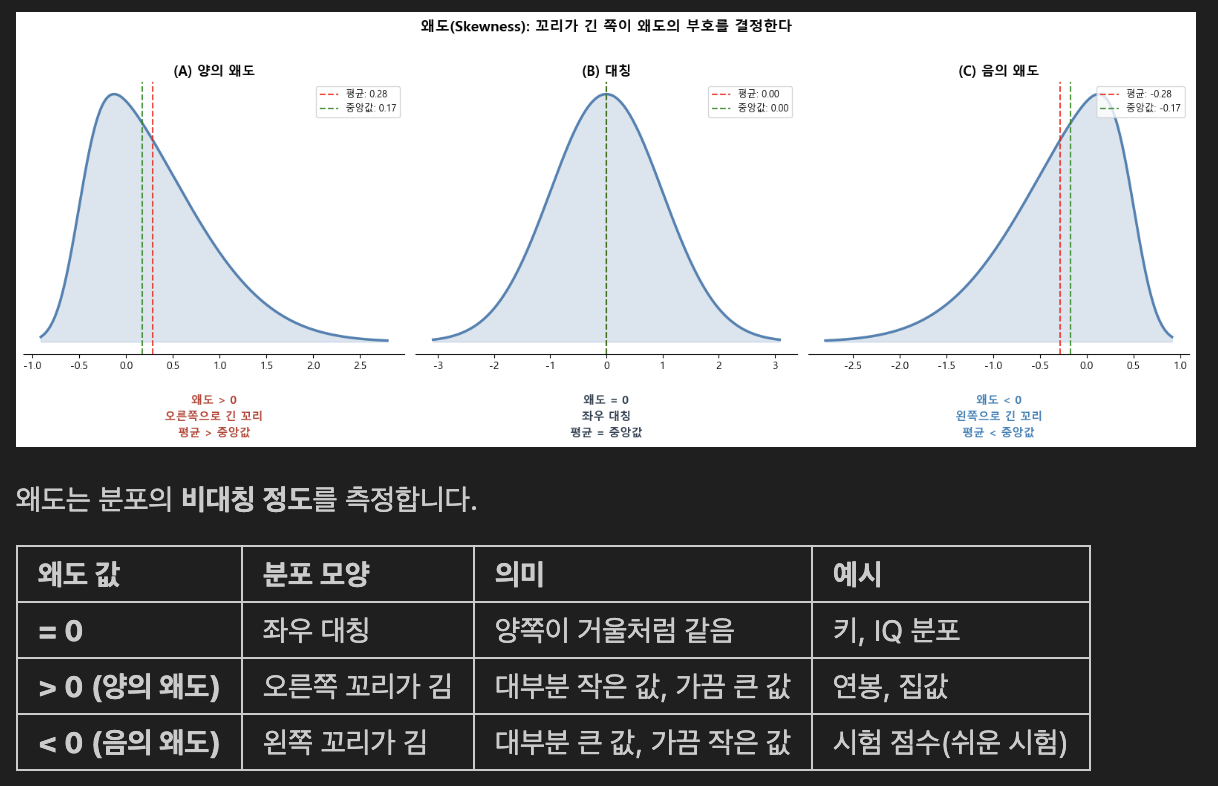
- 왜도(Skewness)와 첨도(Kurtosis)
- 왜도 - 데이터가 어느 쪽으로 치우쳐 있나?
- 첨도 - 극단적인 일이 얼마나 자주 일어나나?
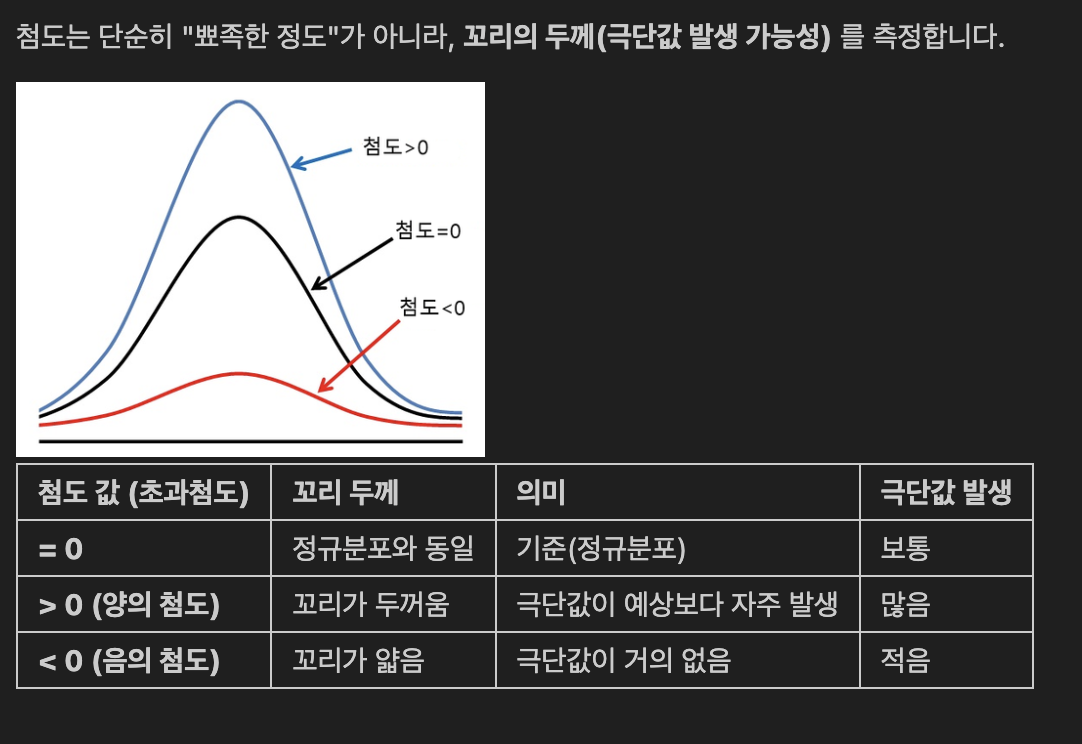

- 첨도는 평범하지 않은 일이 일어날 가능성을 측정하는 지표.
- 리스크 측정에서 첨도를 무시하면 극단적 손실을 과소평가하게 됨
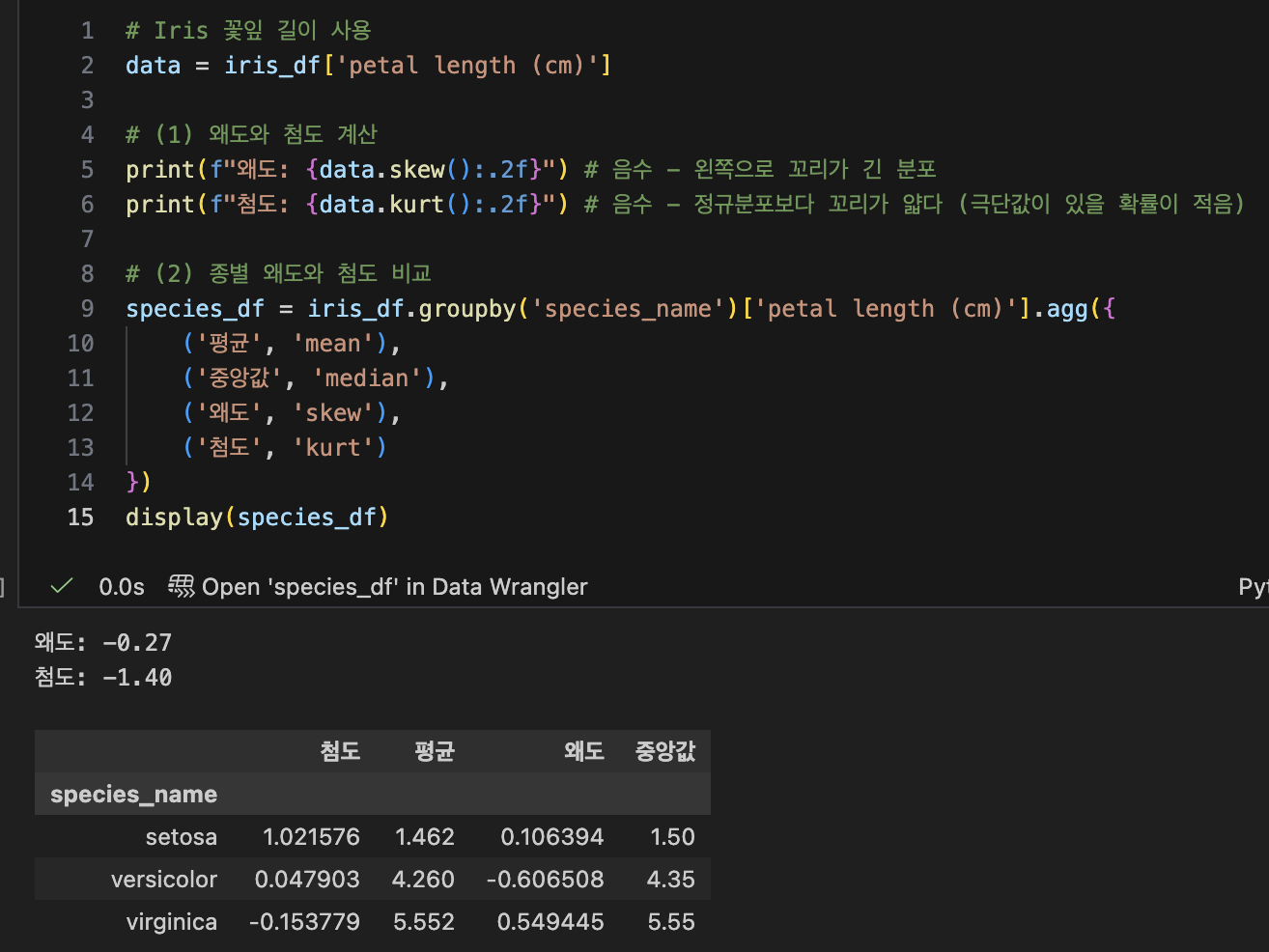


- 확률변수와 기대값
- 확률변수
- 이산확률변수: 가능한 값이 셀 수 있음
- 연속확률변수: 가능한 값이 구간 내 모든 실수
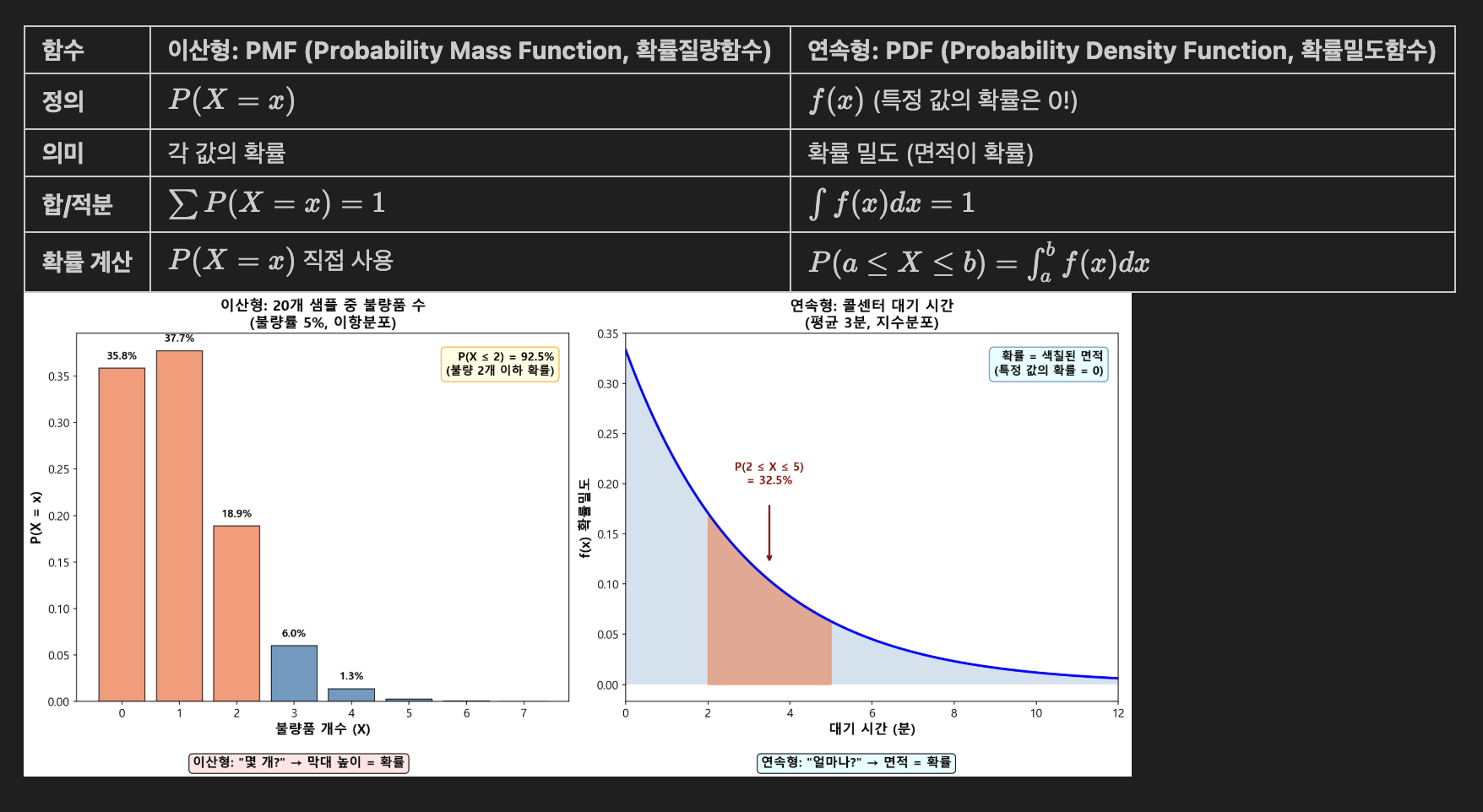
- 확률분포 함수
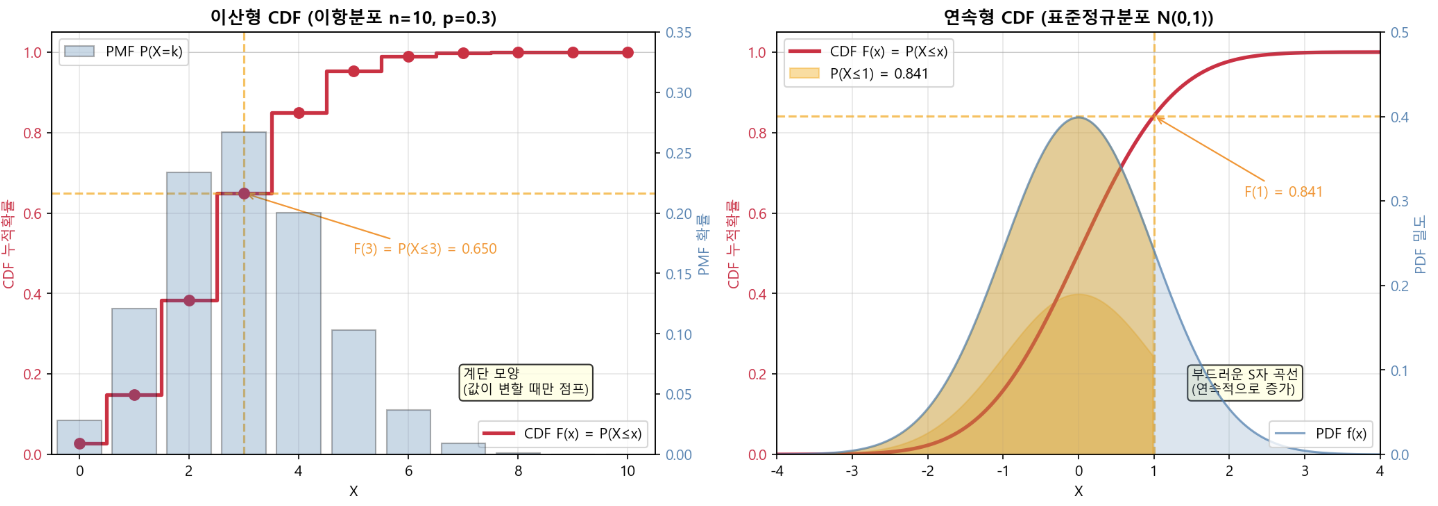
- 누적분포함수 (CDF: Cumulative Distribution Function)
- CDF의 핵심 성질
- 범위: 0<=F(x)<=1 (확률이므로 항상 0과 1 사이)
- 단조 증가: x가 커지면 F(x)도 커지거나 같음 (절대 감소하지 않음)
- 극한값:
- 마이너스 무한으로 가는 극한값 F(x) = 0
- 플러스 무한으로 가는 극한값 F(x) = 1
- CDF를 활용한 확률 계산
- CDF가 중요한 이유
- PMF/PDF는 '정확히 이 값'의 확률만 알려주지만,
- 현실에서는 '몇 개 이하', '몇 점 이상' 같은 구간 확률이 더 자주 필요함
- CDF는 이런 구간 확률을 쉽게 계산하게 해줌
- CDF가 중요한 이유
- CDF의 핵심 성질

- 기대값
- 평균적으로 기대하는 값 = 확률을 가중치로 한 가중평균
- 기대값의 성질
- E[c] = c (상수의 기대값은 상수)
- E[aX+b] = aE[X] + b (선형성)
- E[X+Y] = E[X] + E[Y] (합의 기대값)
- 분산

- 언제 쓸까?
- 기대값이 같더라도 결과가 얼마나 들쭉날쭉한지(리스크)를 비교할 때 사용
- ex) 두 주식 A, B의 기대 수익률이 둘 다 연 5%라고 하자. A는 4~6% 사이에서 움직이고, B는 -20%~+30%로 크게 흔들린다. 분산이 작은 A가 더 안정적이므로, 위험을 줄이고 싶은 투자자는 A를 선택할 수 있다.
- CDF 실습
# CDF 실습: 누적분포함수 활용
print("\n[CDF 실습] 누적분포함수 활용")
print("=" * 50)
# ─────────────────────────────────────────────
# 예제 1: 이산형 CDF (주사위)
# ─────────────────────────────────────────────
print("\n[예제 1] 주사위 CDF")
print("공정한 주사위를 던질 때, 각 눈의 확률은 1/6")
# 주사위 눈 1~6, 각각 확률 1/6
x_dice = np.arange(1, 7)
pmf_dice = np.ones(6) / 6 # [1/6, 1/6, 1/6, 1/6, 1/6, 1/6]
# CDF 계산: F(x) = P(X ≤ x) = PMF의 누적합
cdf_dice = np.cumsum(pmf_dice)
# 각 주사위 눈 별로 1~6까지의 누적 분포 확률 값을 포현
for x, p, c in zip(x_dice, pmf_dice, cdf_dice):
print(f"X={x}, PMF={p:.2f}, CDF={c:.2f}")
# ─────────────────────────────────────────────
# 예제 2: 연속형 CDF (정규분포)
# ─────────────────────────────────────────────
print("\n[예제 2] 정규분포 CDF")
print("시험 점수: 평균 70점, 표준편차 10점")
mu, sigma = 70, 10
norm_dist = stats.norm(loc=mu, scale=sigma) # 정규 분포의 확률 밀도 함수
# CDF 활용 예제
score_80 = 80
score_60 = 60
score_90 = 90
# P(X <= 80) = CDF(80)
print(f"P(X <= 80) = cdf(80) = {norm_dist.cdf(score_80):.2f}")
print(f"P(X > 80) = sf(80) = {norm_dist.sf(score_80):.2f}")
print(f'P(X > 80) = (1 - cdf(80)) = {1 - norm_dist.cdf(score_80):.2f}')
print(f'P(60 <= X <= 90) = cdf(90)-cdf(60) = {norm_dist.cdf(score_90)-norm_dist.cdf(score_60):.2f}')
# PPF(누적분포함수의 역함수)
# 일반함수 y = f(x)
# 역함수 x = f^(-1)(y)
# 상위 10%의 점수를 알고싶다!
# cdf(x) = 0.9 인경우의 x값을 알고싶다!
# ppf(0.9) = x의 값을 알 수 있다!
print(f"상위 10%의 컷트라인 점수 : {norm_dist.ppf(0.9):.2f}") #상위 10%의 컷트라인 점수 : 82.82
print(f"하위 25%의 컷트라인 점수 : {norm_dist.ppf(0.25):.2f}") #하위 25%의 컷트라인 점수 : 63.26# 예제 1: 복권의 기대값 - 살까 말까?
print("\n[예제 1] 복권의 기대값")
print("1000원짜리 복권의 당첨금과 확률:")
print("- 1등 (1억원): 1/1,000,000")
print("- 2등 (100만원): 1/100,000")
print("- 3등 (1만원): 1/1,000")
print("- 꽝: 나머지")
# 당첨금 (원)
prizes = np.array([100000000, 1000000, 10000, 0])
# 확률
probs = np.array([1/1000000, 1/100000, 1/1000, 1 - 1/1000000 - 1/100000 - 1/1000])
# (1) 기대 당첨금
expected_prize = np.sum(prizes * probs)
print(expected_prize) # 120
# (2) 복권 가격 대비 기대값 (순이익)
expected_profit = expected_prize - 1000
print(expected_profit) # -880# 예제 2: 보험 상품 설계
print("\n[예제 2] 보험 상품 설계")
print("1년 자동차 보험 상품 설계")
print("- 사고 시 보험금: 1000만원")
print("- 사고 확률: 5%")
print("- 보험사 목표 이익률: 20%")
# 보험사 입장에서 얼마의 보험금을 책정해야할까??
# 보험사 입장에서 기대 지급금
insurance_payout = 1000 # 사고시 1000만원
accident_prob = 0.05
expected_payout = insurance_payout * accident_prob + 0 * (1-accident_prob)
print("지급금: ", expected_payout) # 50만원
# 목표 이익률을 고려한 보험료 책정
target_margin = 0.2 # 20% 이익률
# 보험료 = 지급금 + 이익
# 이익 = 이익률 * 보험료
# 보험료 = 지급금 / (1-이익률)
insurance_premium = expected_payout / (1-target_margin)
print(insurance_premium) # 62.5 # 62만 5천원으로 보험료를 설계하면 된다!
- 이산형 확률분포
- 베르누이 분포

print("\n" + "="*60)
print("Part 4.1: 베르누이 분포")
print("="*60)
# 예제: 광고 클릭률 분석
print("\n[예제] 온라인 광고 클릭률")
print("광고 클릭률(CTR)이 3%일 때, 한 사용자가 클릭할 확률")
p_click = 0.03 # 클릭 확률
# scipy.stats를 이용한 베르누이 분포
be_dist = stats.bernoulli(p=p_click)
# (1) 클릭할 확률 P(X=1)
p_clidk_yes = be_dist.pmf(1)
print(p_clidk_yes) # 0.03
# (2) 클릭하지 않을 확률 P(X=0)
p_clidk_no = be_dist.pmf(0)
print(p_clidk_no) # 0.97
# (3) 기대값과 분산
mean_be = be_dist.mean()
var_be = be_dist.var()
print(f"기댓값: {mean_be}")
print(f"분산: {var_be:.2f}")
# 시각화
fig, ax = plt.subplots(figsize=(8, 5))
x = [0, 1]
probs = [be_dist.pmf(0), be_dist.pmf(1)]
ax.bar(x, probs, color=['lightcoral', 'steelblue'], edgecolor='black')
ax.set_xticks([0, 1])
ax.set_xticklabels(['클릭 안함 (0)', '클릭 (1)'])
ax.set_ylabel('확률')
ax.set_title(f'베르누이 분포: 광고 클릭 (p={p_click})', fontweight='bold')
for i, prob in enumerate(probs):
ax.text(i, prob + 0.02, f'{prob:.3f}', ha='center', fontsize=12)
ax.set_ylim(0, 1.1)
plt.tight_layout()
plt.show()
- 이항 분포 (Binomial Distribution)
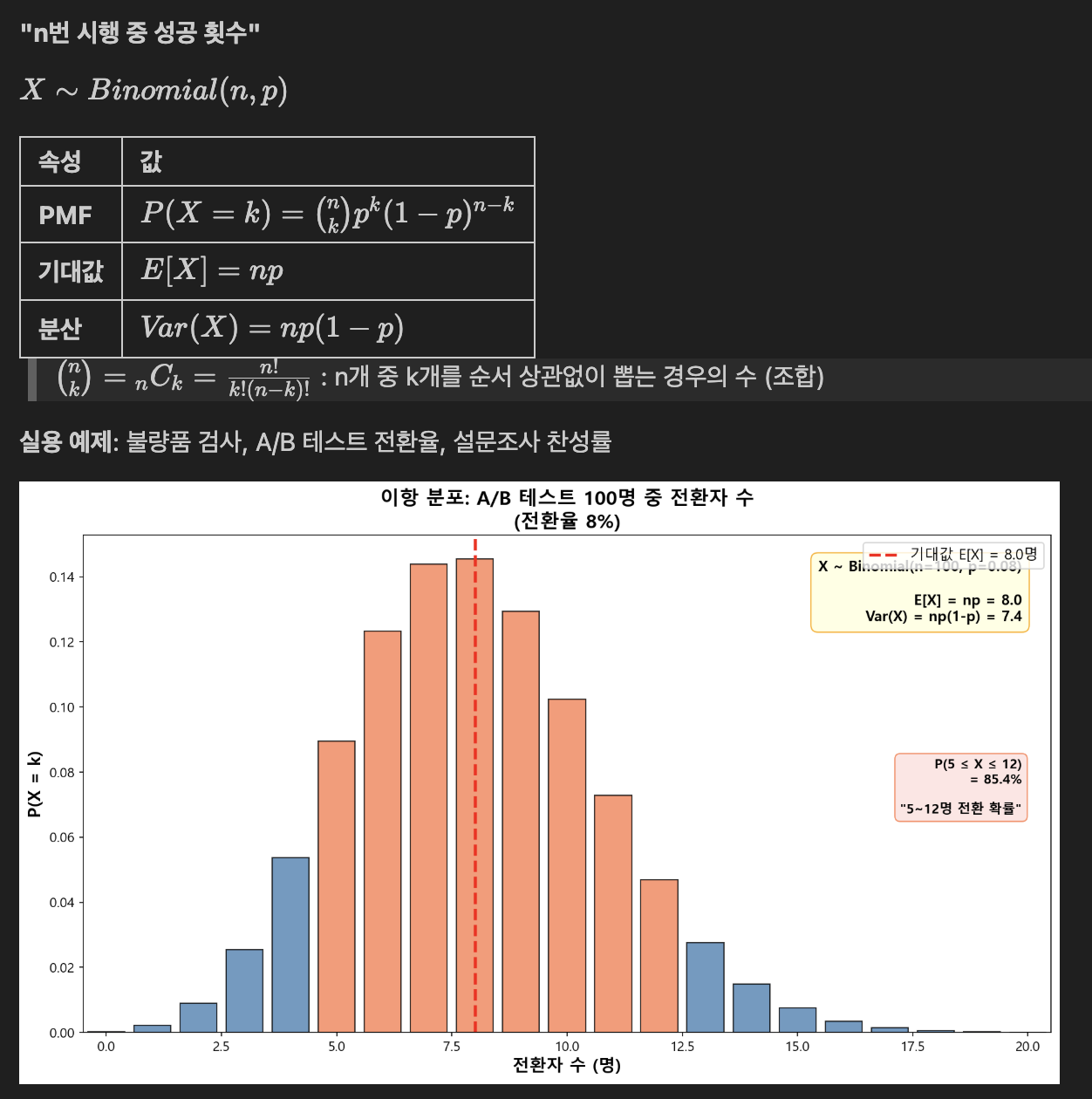
# 실습 1: 불량품 검사
print("\n[실습 1] 불량품 검사")
print("불량률 3%인 공장에서 100개 샘플을 검사할 때")
n_samples = 100
defect_rate = 0.03
# scipy.stats를 이용한 이항 분포
binom_dist = stats.binom(n=n_samples, p=defect_rate)
# (1) 불량품이 정확히 3개일 확률
print(f"불량품이 정확히 3개일 확률", binom_dist.pmf(3))
# (2) 불량품이 5개 이하일 확률 (CDF 사용)
print(f"불량품이 5개 이하일 확률", binom_dist.cdf(5))
# (3) 불량품이 10개 이상일 확률
# P(x=10) = 1 - cdf(9)
# cdf(10) 하면 안되는 이유
print(f"불량품이 10개 이상일 확률", 1 - binom_dist.cdf(9))
print(f"불량품이 10개 이상일 확률", binom_dist.sf(9))
# (4) 기대값과 표준편차
mean_binom = binom_dist.mean()
std_binom = binom_dist.std()
print('기댓값', mean_binom)
print('표준편차', std_binom)- 불량품이 10개 이상일 확률
- 1-binom_dist.cdf(9)
- 이산형 분포이기 때문에 10개 이상인 확률을 구하려면 1에서 9개까지의 누적 확률을 빼야하므로
- binom_dist.sf(9)
- 이산형 분포이기 때문에 10개 이상인 확률을 구하려면 9개 초과의 누적확률분포로 구할 수도 있기 때문에
- 1-binom_dist.cdf(9)
# 시각화: 불량품 개수 분포
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# PMF 그래프
k = np.arange(0, 15)
pmf = binom_dist.pmf(k)
axes[0].bar(k, pmf, color='steelblue', edgecolor='black', alpha=0.7)
axes[0].axvline(n_samples * defect_rate, color='red', linestyle='--',
label=f'기대값 = {n_samples * defect_rate:.1f}')
axes[0].set_xlabel('불량품 개수')
axes[0].set_ylabel('확률')
axes[0].set_title('이항 분포: 불량품 개수 (n=100, p=0.03)', fontweight='bold')
axes[0].legend()
# CDF 그래프
cdf = binom_dist.cdf(k)
axes[1].step(k, cdf, where='mid', color='steelblue', linewidth=2)
axes[1].axhline(0.95, color='red', linestyle='--', alpha=0.7, label='95% 수준')
axes[1].set_xlabel('불량품 개수')
axes[1].set_ylabel('누적 확률')
axes[1].set_title('누적 분포 함수 (CDF)', fontweight='bold')
axes[1].legend()
plt.tight_layout()
plt.show()
- 포아송 분포 (Poisson Distribution)
- 단위 시간/공간당 발생 횟수

# 시각화: 콜센터 통화량 분포
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# PMF
k = np.arange(0, 20)
pmf = poisson_dist.pmf(k)
axes[0].bar(k, pmf, color='steelblue', edgecolor='black', alpha=0.7)
axes[0].axvline(lambda_calls, color='red', linestyle='--', label=f'λ = {lambda_calls}')
axes[0].set_xlabel('통화 수')
axes[0].set_ylabel('확률')
axes[0].set_title(f'포아송 분포: 시간당 통화량 (λ={lambda_calls})', fontweight='bold')
axes[0].legend()
# 다양한 λ 비교
for lam in [2, 5, 10]:
pmf = stats.poisson.pmf(k, mu=lam)
axes[1].plot(k, pmf, 'o-', label=f'λ = {lam}', markersize=5)
axes[1].set_xlabel('발생 횟수')
axes[1].set_ylabel('확률')
axes[1].set_title('λ 값에 따른 포아송 분포 변화', fontweight='bold')
axes[1].legend()
plt.tight_layout()
plt.show()
- 람다가 커질 수록 포아송 분포는 정규분포에 가까워진다
# 실습 2: 웹사이트 서버 용량 계획
# 시나리오: 우리 웹사이트에 분당 평균 100명이 방문한다.
# 서버가 동시에 처리할 수 있는 최대 용량(몇명을 기준으로)을 얼마로 설정해야 과부하 없이 안정적으로 운영할 수 있을까?
# 평균 100 명 --> 분당 200명?
print("\n[실습 2] 웹사이트 서버 용량 계획")
print("=" * 50)
# 포아송 분포의 핵심 파라미터: λ (lambda) = 단위 시간당 평균 발생 횟수
# 여기서는 "분당 평균 방문자 수"
lambda_visitors = 100
print(f"분당 평균 방문자 수 (λ): {lambda_visitors}명")
print(f"포아송 분포 특징: 기대값 = 분산 = λ = {lambda_visitors}")
print(f"표준편차: √λ = √{lambda_visitors} = {lambda_visitors**0.5:.2f}명")
# ─────────────────────────────────────────────
# 1단계: 특정 방문자 수가 나올 확률 확인
# ─────────────────────────────────────────────
print("\n[1단계] 특정 방문자 수가 나올 확률")
print("-" * 50)
# stats.poisson.pmf(k, mu) : 정확히 k명이 방문할 확률
# pmf = Probability Mass Function (확률질량함수)
for k in [80, 90, 100, 110, 120]:
prob = stats.poisson.pmf(k, mu=lambda_visitors)
print(f" 정확히 {k:>3d}명 방문할 확률: {prob:.4f} ({prob*100:.2f}%)")
# ─────────────────────────────────────────────
# 2단계: 누적 확률로 서버 용량 결정
# ─────────────────────────────────────────────
print("\n[2단계] 누적 확률로 서버 용량 결정")
print("-" * 50)
# stats.poisson.cdf(k, mu) : k명 이하가 방문할 확률 (누적)
# cdf = Cumulative Distribution Function (누적분포함수)
for k in [110, 115, 120, 125, 130]:
cum_prob = stats.poisson.cdf(k, mu=lambda_visitors)
print(f" {k:>3d}명 이하로 방문할 확률: {cum_prob:.4f} ({cum_prob*100:.2f}%)")
# ─────────────────────────────────────────────
# 3단계: 목표 안정성에 맞는 용량 역산 (핵심!)
# ─────────────────────────────────────────────
print("\n[3단계] 목표 안정성에 맞는 서버 용량 역산")
print("-" * 50)
# stats.poisson.ppf(확률, mu) : 해당 확률을 만족하는 최소 k값
# ppf = Percent Point Function (백분위 함수) = cdf의 역함수
# "이 용량이면 해당 확률만큼은 안전하다"는 의미
for confidence in [0.95, 0.99, 0.999]:
capacity = stats.poisson.ppf(confidence, mu=lambda_visitors)
overflow_prob = (1 - confidence) * 100
print(f" {confidence*100:.1f}% 안정성 → 서버 용량: {capacity:.0f}명"
f" (과부하 확률: {overflow_prob:.1f}%)")
# ─────────────────────────────────────────────
# 결론
# ─────────────────────────────────────────────
capacity_99 = stats.poisson.ppf(0.99, mu=lambda_visitors)
print("\n[결론]")
print("=" * 50)
print(f"분당 평균 {lambda_visitors}명 방문하는 서버에서")
print(f"99% 안정성을 원하면 → 서버 용량을 {capacity_99:.0f}명으로 설정")
print(f"즉, 분당 방문자가 {capacity_99:.0f}명을 초과할 확률은 1% 미만이다.")- 125명 이하로 방문할 확률이 0.9932
- 안정성을 99%로 잡는다면 분당 124명이 방문할 것을 가정하고 설계해야함
- 과부하 경우를 0.1%로 잡는다면 분당 130명이 방문할 것을 가정하면 됨
- 연속형 확률분포
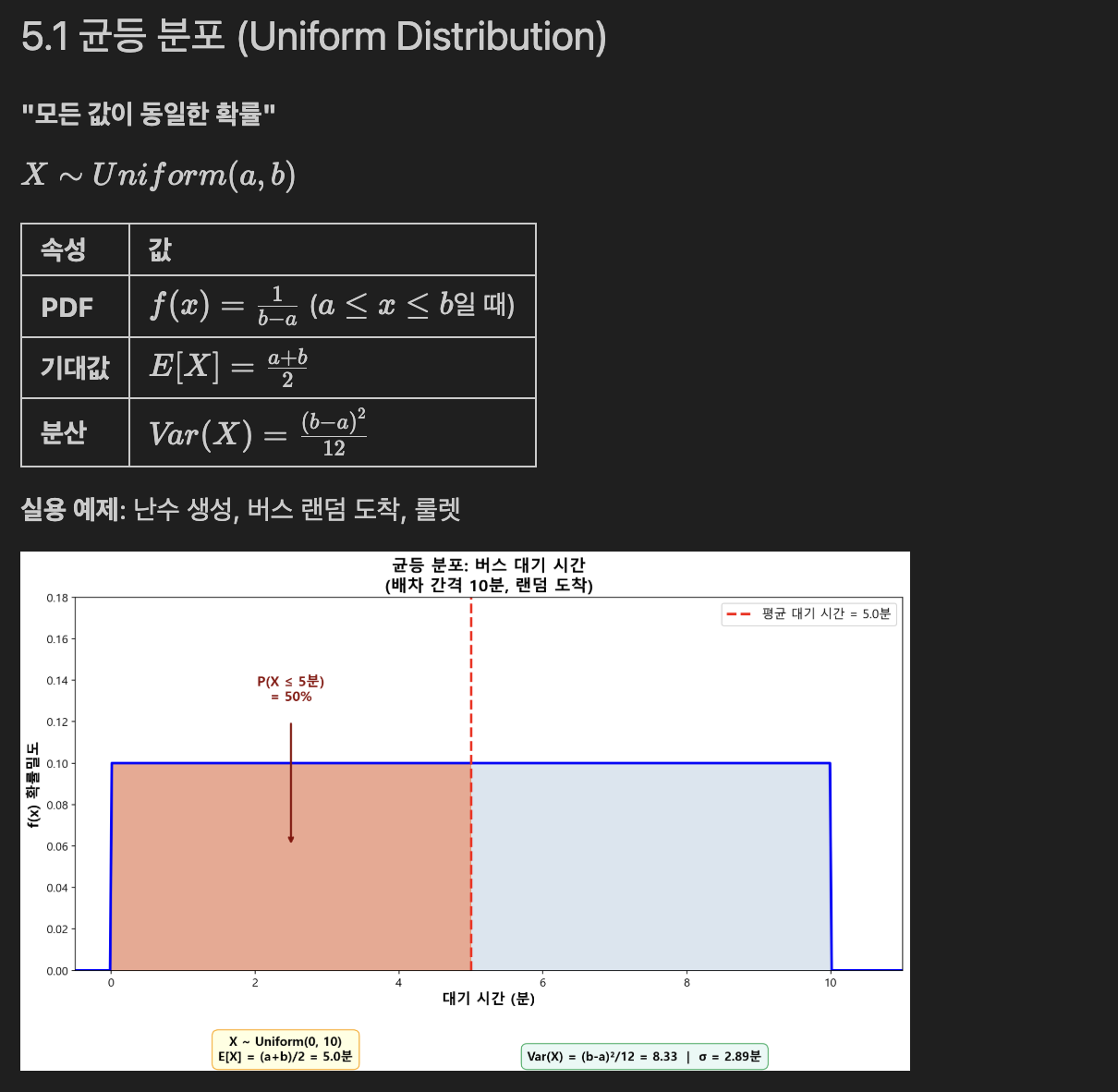
print("\n" + "=" * 60)
print("Part 5.1: 균등 분포")
print("=" * 60)
print("\n[실습] 버스 대기 시간")
print("버스 배차 간격: 10분")
print("승객이 랜덤한 시간에 도착할 때 대기 시간의 분포")
a, b = 0, 10 # 대기 시간 범위: 0분 ~ 10분
# scipy.stats로 균등 분포 생성
uni_dist = stats.uniform(loc=a, scale=b-a)
# (1) 5분 이내에 버스가 올 확률
print(uni_dist.cdf(5))
# (2) 7분 이상 기다릴 확률
print(uni_dist.sf(7))
print(1-uni_dist.cdf(7))
# (3) 평균 대기 시간 (기대값)
print(uni_dist.mean())
# (4) 대기 시간의 표준편차
print(uni_dist.std()) #2.8# 시각화
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
x = np.linspace(-1, 11, 1000)
# PDF
pdf = uni_dist.pdf(x)
axes[0].plot(x, pdf, 'b-', linewidth=2)
axes[0].fill_between(x, pdf, alpha=0.3)
axes[0].axvline(5, color='red', linestyle='--', label='평균 = 5분')
axes[0].set_xlabel('대기 시간 (분)')
axes[0].set_ylabel('확률 밀도')
axes[0].set_title('균등 분포: 버스 대기 시간 PDF', fontweight='bold')
axes[0].legend()
axes[0].set_xlim(-1, 11)
# CDF
cdf = uni_dist.cdf(x)
axes[1].plot(x, cdf, 'b-', linewidth=2)
axes[1].axhline(0.5, color='red', linestyle='--', alpha=0.5, label='50% 확률')
axes[1].set_xlabel('대기 시간 (분)')
axes[1].set_ylabel('누적 확률')
axes[1].set_title('균등 분포: 버스 대기 시간 CDF', fontweight='bold')
axes[1].legend()
axes[1].set_xlim(-1, 11)
plt.tight_layout()
plt.show()
print("\n" + "="*60)
print("Part 5.2: 지수 분포")
print("="*60)
# 실습: 기계 수명 분석
print("\n[실습] 기계 수명 분석")
print("기계의 평균 수명: 1000시간")
print("(즉, 시간당 고장률 scale = 1/1000 = 0.001)")
mean_lifetime = 1000 # 평균 수명 (시간)
lambda_rate = 1 / mean_lifetime
# scipy.stats를 이용한 지수 분포
# scipy에서는 scale = 1/lambda = 대기시간
exp_dist = stats.expon(scale=mean_lifetime)
# (1) 500시간 이내에 고장날 확률
print(exp_dist.cdf(500))
# (2) 1500시간 이상 작동할 확률
print(exp_dist.sf(1500)) #1 - (1500시간 내에 고장날 확률)
# (3) 기대값과 표준편차
print(exp_dist.mean())
print(exp_dist.std())
# (4) 중앙값 (50%가 고장나는 시점)
print(exp_dist.median()) #전체의 50%가 고장나는 시점# 시각화
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
x = np.linspace(0, 4000, 1000) #0이상, 4000이하, 1000등분해서 1000개의 데이터를 생성
# PDF
pdf = exp_dist.pdf(x)
axes[0].plot(x, pdf, 'b-', linewidth=2)
axes[0].fill_between(x, pdf, alpha=0.3)
axes[0].axvline(mean_lifetime, color='red', linestyle='--', label=f'평균 수명 = {mean_lifetime}시간')
axes[0].set_xlabel('시간')
axes[0].set_ylabel('확률 밀도')
axes[0].set_title('지수 분포: 기계 수명 PDF', fontweight='bold')
axes[0].legend()
# 생존 함수 (1 - CDF)
survival = 1 - exp_dist.cdf(x)
axes[1].plot(x, survival, 'b-', linewidth=2)
axes[1].axhline(0.5, color='red', linestyle='--', alpha=0.5)
axes[1].axvline(exp_dist.median(), color='green', linestyle=':', label=f'중앙값 = {exp_dist.median():.0f}시간')
axes[1].set_xlabel('시간')
axes[1].set_ylabel('생존 확률')
axes[1].set_title('지수 분포: 생존 함수', fontweight='bold')
axes[1].legend()
plt.tight_layout()
plt.show()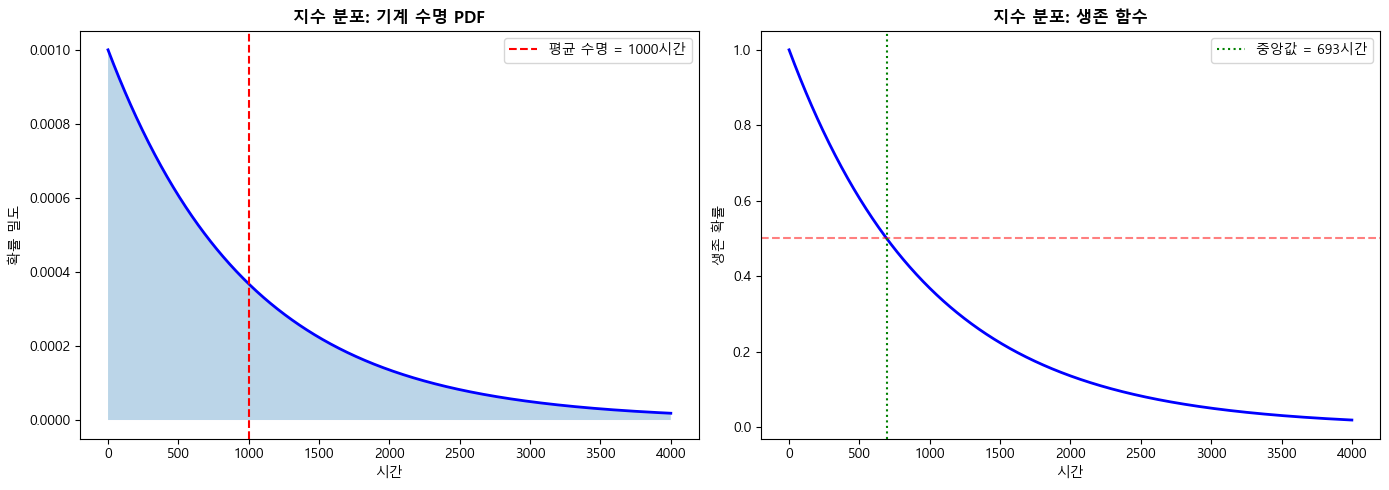
포아송 - 단위 시간 동안 몇 번 일어날까?
지수 - 한 번 일어날 때 얼마나 걸릴까?
포아송의 lambda -> 단위 시간당 평균 lambda번 발생
지수분포의 1/lambda -> 사건이 발생하기 까지 걸리는 평균 시간 (포아송의 람다를 알고있는경우 대기 시간 1/lambda)
[ 오후 통계학 이론 세션 ]
- 통계적 추론 (Statistical Inference)
- 예언구간 vs 신뢰구간
- 표본오차
- 신뢰구간
- 예언구간 vs 신뢰구간
- 가설검정 기초
http://myun0506.tistory.com/98
통계학 세션 이론 3일차 (예언구간 vs 신뢰구간, 가설검정)
[ 오후 통계학 이론 세션 ]- 통계적 추론 (Statistical Inference)표본으로 모집단 평균이 있을 법한 범위 = 신뢰구간을 추정정규분포 -> 범위로 예측 (예언구간)표본평균도 정규처럼 움직인다 (중심극한
myun0506.tistory.com
'[데이터분석] 부트캠프 TIL' 카테고리의 다른 글
| 20260210 TIL (0) | 2026.02.10 |
|---|---|
| 20260209 TIL (0) | 2026.02.09 |
| 20260205 TIL (0) | 2026.02.05 |
| 20260204 TIL (0) | 2026.02.04 |
| 20260203 TIL (0) | 2026.02.03 |