[Today I Learn]
- Python codekata
- 통계학 기초
- 통계학 세션
[Python codekata]
- 문제 1.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120910
2. 정답 코드
def solution(n, t):
return n*(2**t)
- 문제 2.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120847
2. 정답 코드
def solution(numbers):
max_num = max(numbers)
numbers.remove(max_num)
max_num2 = max(numbers)
return max_num * max_num2def solution(numbers):
numbers.sort()
return numbers[-2] * numbers[-1]def solution(numbers):
numbers.sort(reverse=True)
return numbers[0]*numbers[1]def solution(numbers):
numbers.sort()
num1 = numbers.pop()
num2 = numbers.pop()
return num1 * num2
- 문제 3.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120585
2. 정답 코드
def solution(array, height):
array.append(height)
array.sort(reverse=True) # inplace 메서드
a = array.index(height)
return adef solution(array, height):
array2 = [i for i in array if i > height]
return len(array2)def solution(array, height):
array.append(height)
array.sort(reverse=True)
return array.index(height)- 여기서 array.append(height).sort(reverse=True)로는 못 쓰는 이유
- array.append(height)는 inplace 메서드이기 때문에 메서드 실행이 끝나면 None값을 반환하므로
- None.sort() 불가능 (존재하지 않는 객체에 메서드를 실행하겠다? 당연히 불가능)
[통계학 기초]
- 데이터 분석에 있어서 통계가 중요한 이유
데이터 기반의 의사결정을 내릴 수 있음!
- 데이터를 분석하고 이를 바탕으로 결정을 내릴 수 있음
- 우리가 분석을 할 데이터는 양이 방대할 것인데, 이를 요약하고 패턴을 발견하는데 통계가 필요함
- 추론을 통해 결론을 도출하는 과정에 통계가 필요함
- 즉, 데이터 기반의 의사결정을 내릴 수 있음
- 기업의 입장에서는 수익을 창출하기 위해 필요함. (보다 원활한 결정을 내리고...)
통계를 활용한 데이터 분석은 필수!!!
- 실제로 통계가 어떻게 사용되어지나요?
- ex) 비율 계산:
- 전체 데이터 중에서 각각의 항목이 얼마만큼의 비율을 가지고 있는지...
- 쉽게 데이터에 대해서 요약을 할 수 있고 해석을 할 수 있을 것
- 고객 유형별 세그먼트
- 고객 유형별 특징을 파악하고 그에 맞춰서 상품을 추천할 수 있을 것
- ex) 비율 계산:


- 기술통계와 추론통계
- 기술통계
- 데이터를 요약하고 설명하는 통계 방법
- 평균, 중앙값, 분산, 표준편차 등 사용
- 즉, 데이터를 특정 대표값으로 요약 (간단)
- 데이터에선 항상 '예외'라는 것이 존재
- 예외는 '대푯값'만으로는 설명이 불가능...
- 이럴 땐 따로 확인해볼 필요 있음
- 평균
- 모든 데이터를 더한 후 데이터의 개수로 나누는..
- 데이터의 일반적인 경향을 파악하는데 유용함
- 중앙값
- 데이터셋을 크기 순서대로 정렬했을 때 중앙에 위치한 값
- 이상치에 영향을 덜 받기 때문에 (평균을 구할 땐 이상치의 영향을 많이 받음)
- 데이터의 중심 경향을 나타내는 또다른 방식
- 분산
- 데이터 값들이 평균으로부터 얼마나 떨어져있는지를 나타내는 척도
- 데이터의 흩어짐 정도를 측정
- 분산이 크면 데이터가 넓게 퍼져있고, 작으면 데이터가 평균에 가깝게 모여있음을 의미
- 분산을 구하는 방법
- 각 데이터 값에서 평균을 뺀 값을 제곱한 후,
- 이를 모두 더하고 데이터의 개수로 나누는 것
- but, 분산은 직관적으로 와닿지 않음
- 데이터에서 사용되는 단위에 맞는 흩어진 정도를 알고싶다면
- 표준편차를 사용
- ex) 평균 점수가 80점인데 분산이 125면 어느정도로 흩어진건지 감이 잘 안옴...
- 표준편차
- 분산은 데이터 값에서 평균에서 얼마나 떨어져있는지를 나타내는 척도로
- 분산의 제곱근을 취하여 계산
- 분산보다 더 직관적으로 이해할 수 있음
- 원래 데이터 값과 동일한 단위로 변환함 -> 직관적!
- ex) 평균 점수가 80점일 때 표준편차는 약 11.18 -> 약 10 언저리정도 값이 벌어져있음!!
- 분산은 데이터 값에서 평균에서 얼마나 떨어져있는지를 나타내는 척도로
- 데이터를 요약하고 설명하는 통계 방법
- 추론통계
- 무에서 유를 창조하는 느낌으로, 추론(inference)를 해야함
- 신뢰구간, 가설검정 등을 사용
- 데이터의 일부를 가지고 데이터 전체를 추정하는 것이 핵심
- ex) 새로운 사람의 인생 전체를 다 본 것은 아니지만 대화를 진행하는 일부 시간 동안 얻어낸 정보로 그 사람이 어떤 사람일지 알아가는 과정과 같음
- 신뢰구간
- 모집단과 표본의 평균이 어느정도 다를 수 밖에 없는데,
- 표본의 평균을 이용해서 모집단의 평균이 어느정도의 구간에 해당할 것이다!라고 추측할 수 있음
- ex) 설문조사에서 평균 만족도가 75점이고 신뢰구간이 70점에서 80점이라면
- 우리는 95% 확률로 실제 평균 만족도가 이 범위 내에 있다고 말할 수 있음
- 가설검정
- 모집단에 대한 가설을 검증하기 위해 사용함
- 귀무가설
- 검증하고자 하는 가설이 틀렸음을 나타내는 기본 가설
- 대립가설
- 우리가 주장하는 바를 나타내는 가설
- p-value를 통해 귀무가설을 기각할지 여부를 결정함
- ex) 새로운 교육 프로그램이 학생들의 성적에 영향을 미치는지 알고싶다면
- 귀무가설은 '프로그램이 성적에 영향을 미치지 않는다'
- 대립가설은 '프로그램이 성적에 영향을 미친다'
기술 통계: 회사의 매출 데이터를 요약하기 위해 평균 매출, 매출의 표준편차 등을 계산
추론 통계: 일부 고객의 설문조사를 통해 전체 고객의 만족도를 추정
- 다양한 분석 방법
- 위치추정
- 데이터의 중심을 확인하는 방법, 데이터들이 서로 얼마나 다른지 확인하는 방법
- ex) 평균, 중앙값
- 변이추정
- ex) 분산, 표준편차, 범위 등
- 범위
- 데이터셋에서 가장 큰 값과 가장 작은 값의 차이를 나타내는 간단한 분포의 측도
- 범위(R) = 최대값 - 최솟값
- 데이터 분포 탐색
- 데이터의 값들이 어떻게 이루어져 있는지 확인하기
- ex) 히스토그램과 박스플랏
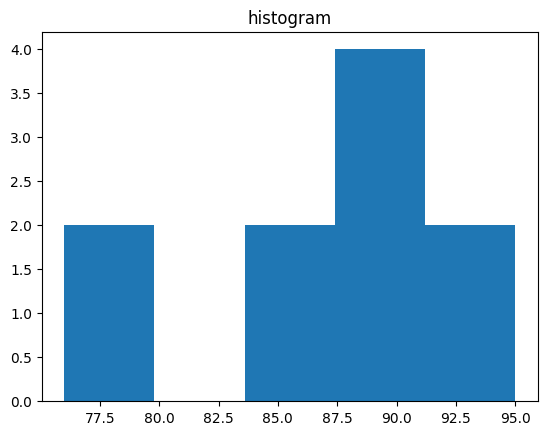
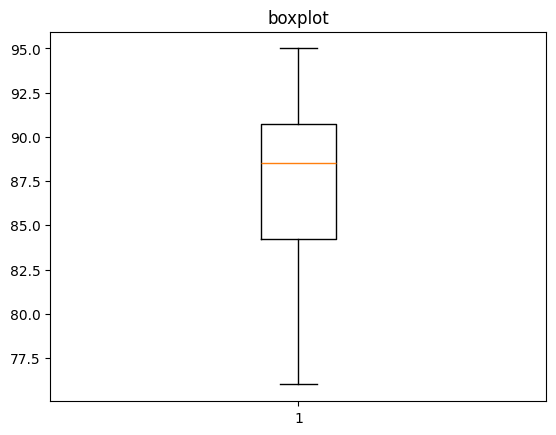

- 이진 데이터와 범주 데이터 탐색
- 데이터들이 서로 얼마나 다른지 확인하는 방법
- 수치가 아니라 문자가 들어간 데이터... (두 항목일 때 이진, 세 항목 이상일 때 범주)
- 최빈값(개수가 제일 많은 값)을 주로 사용함
- 파이그림과 막대 그래프는 이진 데이터와 범주 데이터의 분포를 표현하는 대표적 방법
- 히스토그램은 수치형 데이터의 분포를 표현하는데 사용 (범위를 나누어야함)

- 상관관계
- 데이터들끼리 서로 관련이 있는지 확인하는 방법
- 두 변수 간의 관계 측정
- -1이나 1에 가까워지면 강력한 상관관계를 가짐
- -0.5나 0.5를 가지면 중간정도의 상관관계를 가짐
- 0에 가까울 수록 상관관계가 없음


- correalation을 보면 2x2 배열이 나오는데 오른쪽 아래방향으로 내려가는 대각선이 자기 자신과의 상관관계를 의미하므로
- (0,1)이나 (1,0) 중 하나에서 상관관계를 가져오면 됨
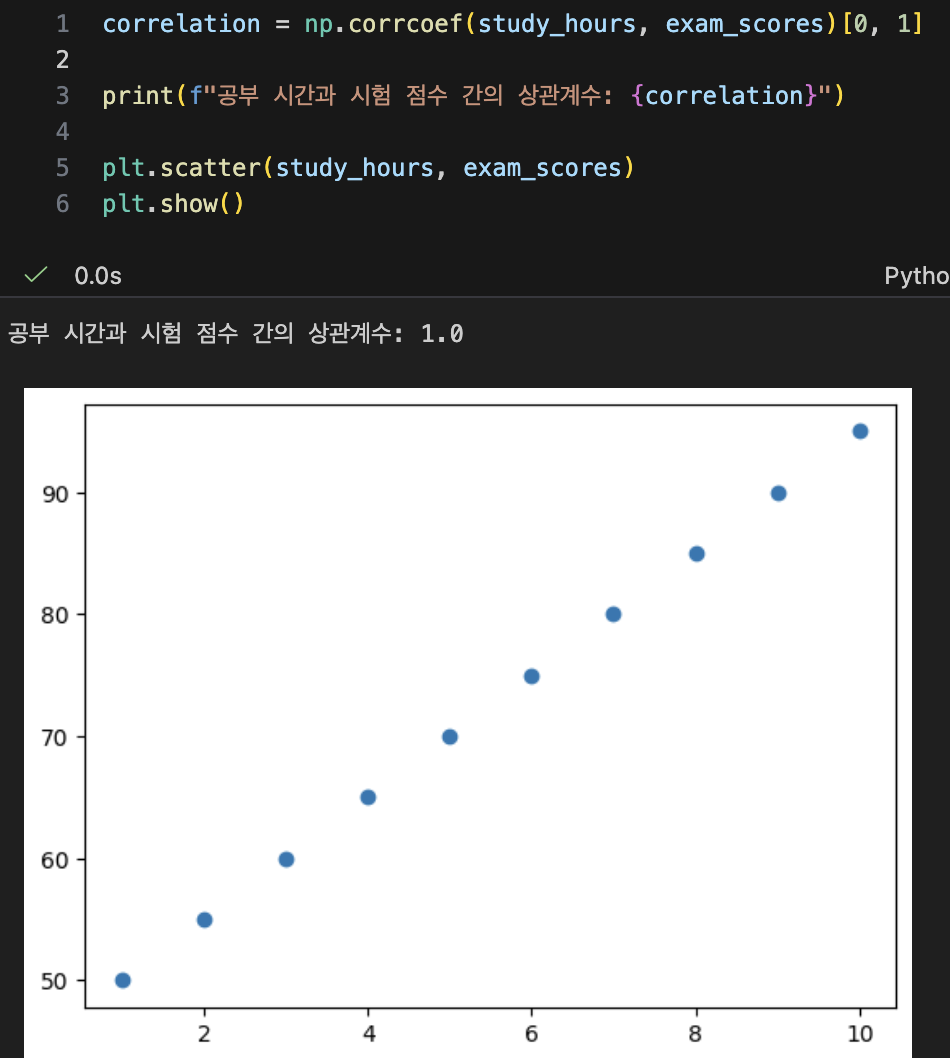
- 인과관계
- 인과관계는 상관관계와는 다르게 원인, 결과가 분명해야함
- 다변량 분석
- 여러 변수 간의 관계를 분석하는 방법
- ex) 여러 마케팅 채널의 광고비와 매출 간의 관계 분석
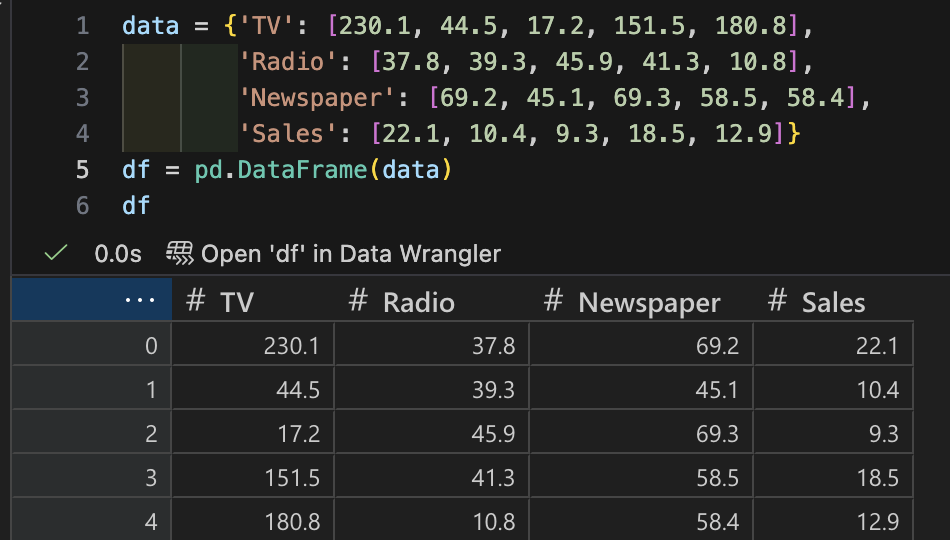


- corr() 메세드를 실행하면 오른쪽아래방향으로의 대각선은 자기 자신과의 상관관계를 의미하므로 아무 의미가 없음
- 비워두기엔 애매하니 히스토그램을 채워넣은것!


- 모집단과 표본
- 왜 표본을 사용하는 걸까?
- 현실적인 제약(비용과 시간, 접근성)
- 대표성(표본의 대표성) :
- 표본에서 얻은 결과를 모집단 전체에 일반화할 수 있음
- 무작위로 표본을 추출하면 편향을 최소화하고 모집단의 다양한 특성을 포함할 수 있음
- 데이터 관리
- 데이터 처리의 용이성
- 데이터 품질 관리
- 모델 검증 용이
- 모델 적합도 테스트
- 전수조사: 모집단 전체를 조사하는 방법
- 표본조사: 표본만을 조사하는 방법. 표본이 대표성을 가져야 함
import numpy as np
import matplotlib.pyplot as plt
# 모집단 생성 (예: 국가의 모든 성인의 키 데이터)
population = np.random.normal(170, 10, 1000) # 키, 표준편차, 모집단 개수
# 표본 추출
sample = np.random.choice(population, 100) # 표본 개수
plt.hist(population, bins=50, alpha=0.5, label='population', color='blue')
plt.hist(sample, bins=50, alpha=0.5, label='sample', color='red')
plt.legend()
plt.title('population and sample distribution')
plt.show()
numpy.random.normal(loc=0.0, scale=1.0, size=None)- numpy.random.normal
- 정규분포(가우시안 분포)를 따르는 난수 생성
- 정규분포는 평균과 표준편차를 중심으로 데이터가 대칭적으로 분포하는 분포
- loc (float): 정규분포의 평균 (기본값: 0.0)
- scale (float): 정규분포의 표준편차 (기본값: 1.0)
- size (int 또는 tuple of ints): 출력 배열의 크기 (기본값: None, 즉 스칼라 값 변환)
- 정규분포(가우시안 분포)를 따르는 난수 생성
numpy.random.choice(a, size=None, replace=True, p=None)- numpy.random.choice
- 주어진 배열에서 임의로 샘플링하여 요소 선택
- 지정된 배열에서 무작위로 선택된 요소를 반환하는 기능 제공
- a (1-D array-like or int): 샘플링할 원본 배열. 정수인 경우 np.arange(a)와 동일하게 간주
- size (int 또는 tuple of ints): 출력 배열의 크기 (기본값: None, 즉 단일 값 반환)
- replace (boolean): 복원 추출 여부를 나타냄. True면 동일한 요소가 여러번 선택될 수 있음 (기본값: True)
- p (1-D array-like, optional): 각 요소가 선택될 확률. 배열의 합은 1이어야 함
- plt.hist
- Matplotlib 라이브러리에서 히스토그램을 그리는 함수 (히스토그램은 데이터의 분포를 시각화하는 데 유용)
- bins
- 히스토그램의 빈의 개수 또는 경계
- bin: 데이터를 몇 개의 구간으로 나눌 것인지
- alpha: 히스토그램 막대의 투명도 (0-투명, 1-불투명)
- 표본오차와 신뢰구간
표본이 모집단 대비해서 얼마나 차이나는지, 신뢰할 수 있는지 파악가능!
- 표본오차 (Sampling Error)
- 표본에서 계산된 통계량과 모집단의 진짜 값 간의 차이
- 표본 크기가 클수록 표본오차는 작아짐
- 이는 표본이 모집단을 완벽하게 대표하지 못하기 때문에 발생하며, 표본의 크기와 표본 추출 방법에 따라 달라질 수 있음
- 표본의 크기: 표본의 크기가 클수록 표본오차는 줄어듦. 더 많은 데이터를 수집할수록 모집단을 더 잘 대표함
- 표본 추출 방법: 무작위 추출방법을 사용하면 표본오차를 줄일 수 있음. 모든 모집단 요소가 선택될 동등한 기회를 가지게 해야함
- 신뢰구간 (Confidence Interval)
- 모집단의 특정 파라미터(평균, 비율)에 대해 추정된 값이 포함될 것으로 기대되는 범위
- 신뢰구간 = 표본평균 +- z * 표준오차
- z: 선택된 신뢰수준에 해당하는 z값. (95% 신뢰수준의 z값은 1.96)

- 모집단과 표본 분포 (왼쪽 그림)
- 붉은색 점선은 모집단의 평균, 파란색 점선은 표본의 평균
- 모집단의 분포는 넓고, 표본 평균의 분포는 좁아짐
- 표본 크기가 커질수록 표본 평균이 모집단 평균에 더 가까워지는 경향을 보임
- 신뢰구간 시각화 (오른쪽 그림)
- 오른쪽 그림은 표본의 분포와 95%의 신뢰구간을 보여줌
- 파란색 점선은 표본의 평균을 나타내고, 녹색 점선은 95% 신뢰구간의 상한과 하한을 나타냄
- 이 신뢰구간은 모집단의 평균을 포함할 것으로 예상되는 범위
import scipy.stats as stats
# 표본 평균과 표본 표준편차 계산
sample_mean = np.mean(sample)
sample_std = np.std(sample)
# 95% 신뢰구간 계산
conf_interval = stats.t.interval(0.95, len(sample)-1, loc=sample_mean, scale=sample_std/np.sqrt(len(sample)))
print(f"표본 평균: {sample_mean}")
print(f"95% 신뢰구간: {conf_interval}")
scipy.stats.t.interval(alpha, df, loc=0, scale=1)- scipy.stats.t.interval:
- 주어진 신뢰 수준에서 t-분포(밑에서 얘기하는 student t분포)를 사용하여 신뢰구간(confidence interval)을 계산하는데 사용됨
- alpha
- 신뢰수준을 의미함
- ex) 95% 신뢰구간을 원하면 alpha를 0.95로 설정
- df: 자유도. 일반적으로 표본 크기에서 1을 뺀 값
- loc: 위치. 일반적으로 표본 평균을 설정
- scale:
- 스케일
- 일반적으로 표본 표준 오차를 설정
- 표본 표준 오차는 표본 표준 편차를 표본 크기의 제곱근으로 나눈 값
- scale = sample_std / sqrt(n)
[ 통계학 세션 ]
- 데이터의 유형
- 기술통계
- 추론통계
https://myun0506.tistory.com/96
통계학 세션 이론 1일차 (데이터 유형, 기술통계, 추론통계)
[ 통계학 세션 ]- 데이터의 유형수치형 / 양적 데이터 (Numerical 수치형 / Quantitative 양적)이산형 (Discrete): 셀 수 있는 정수값 (고객 수, 불량품 개수, 클릭 횟수)연속형 (Continuous): 측정 가능한 실수값
myun0506.tistory.com
'[데이터분석] 부트캠프 TIL' 카테고리의 다른 글
| 20260206 TIL (0) | 2026.02.06 |
|---|---|
| 20260205 TIL (0) | 2026.02.05 |
| 20260203 TIL (0) | 2026.02.03 |
| 20260202 TIL (0) | 2026.02.02 |
| 20260129 TIL (0) | 2026.01.29 |