[ 오후 통계학 이론 세션 ]
- 신뢰구간

- 신뢰구간 CI = 표본평균 +- (신뢰계수 * s/(n**2)
- 표본수가 많아질수록 신뢰구간은 점점 더 좁고 정교해짐 -> 더 정확하게 예측할 수 있음

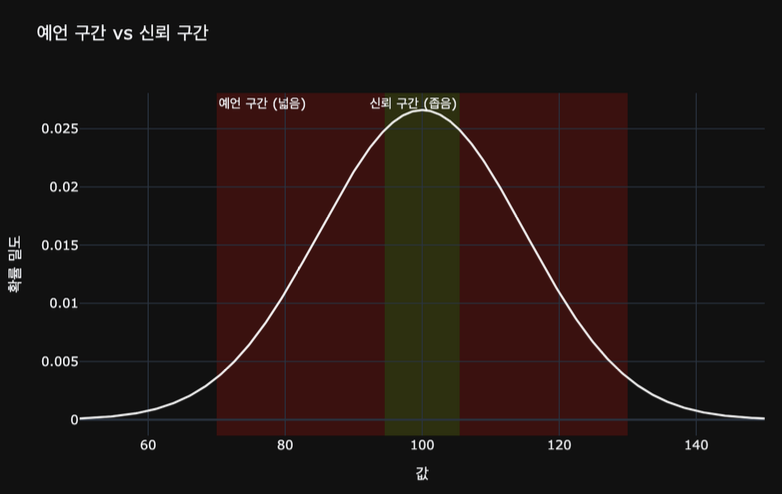
- 예언구간 vs 신뢰구간
- 예언 구간
- 다음 값 하나를 예측하는 범위
- ex) 내일 들어올 손님 한 명의 결제 금액
- 값 하나는 들쭉날쭉 --> 구간이 넓음
- 신뢰 구간
- 모집단 평균을 추정하는 범위
- ex) 고객 전체 평균 결제금액
- 평균은 안정적 --> 구간이 좁음
- 판정규칙
- p<=alpha -> H0 기각
- 효과없음 세계에서는 드문 결과 --> 유의미
- p>alpha -> H0 기각 못함 (보류)
- 효과없음 세계에서도 흔히 발생
- H0를 증명한게 아님, 단지 버릴 근거 부족
- 실무 연결
- A/B 테스트
- H0: 두 버튼 클릭률 같음
- 데이터: 차이=3%, p=0.018<0.05 --> H0 기각 ( 두 버튼 클릭률 차이 있음)
- 품질 관리
- H0: 신공정 불량률이 기존과 같음
- 데이터: 차이 큼, p=0.001<0.05 --> H0 기각 (공정이 달라졌다고 판단)
- A/B 테스트
- 표본 개수에 따른 p-value 크기 비교

1. 표본이 많을수록 (n ↑ → SE ↓):
- 분모인 불확실성(SE)이 작아짐
- 똑같은 차이라도 분모가 작아지니 전체값인 t(검정통계량)는 커짐
- t값이 커지면 분포의 꼬리쪽으로 멀리 밀려나므로, 그 바깥 면적인 p-value는 매우 작아짐
- 결과적으로 작은 차이도 실제 효과일 가능성이 높다고 판정(유의함)하게 됨
2. 표본이 적을수록 (n ↓ → SE ↑):
- 분모인 불확실성이 커져서 t값이 작아짐
- t값이 중심에 가까워지면 p-value는 커짐
- 결론적으로 이 정도 차이는 우연히 발생할 수 있는 오차범위 내에 있다고 보수적으로 판단(유의하지 않음)하게 됨
3. 생활 비유
- 운동 경기
- A팀 80점, B팀 78점
- 점수 들쭉날쭉 (SE큼) -> 2점 차이, 우연일 수도?
- 점수 안정적 (SE작음) -> 2점 차이도 의미있음
- 시험 점수
- 반 A 평균 85, 반 B 평균 80
- 표본 적어서 점수 들쭉날쭉 -> 5점 차이, 우연일 수도?
- 표본 많아서 점수 안정적 -> 5점 차이도 의미있음
- 분산이 크면 차이가 불확실
- 분산이 작으면 같은 차이도 더 신뢰
4. 실무 연결
- A/B 테스트
- 클릭률 5.1% vs 4.8%
- n=수천 -> SE 작음 -> 0.3% 차이도 유의미
- n=수십 -> SE 큼 -> 0.3% 차이 우연일 수도
- 신약 임상시험
- 혈압 감소: 신약 -10 vs 위약 -2
- n이 많으면 유의미, n이 적으면 애매
- 신뢰구간과 가설검정의 관계
- 두 집단 평균차(µA-µB)의 95% 신뢰구간이 0을 포함하지 않으면 -> 귀무가설 기각 (p<0.05 (양측)와 동치)
1. 생활 비유
- 신뢰구간 = 지도
- 우리집이 이 동네 어디쯤 있다라고 영역을 그려줌
- 가설검정 = GPS 경보
- 만약 집이 이 좌표(0)라면, 내가 지금 있는 곳은 너무 멀리 벗어났다 (p<0.05) 라고 알려주는 것
2. 실무 연결
- A/B 테스트 중간 보고
- 신뢰구간: 전환율 차이 1%p~3%p, 0 포함 안됨
- 검정: p=0.012 -> 귀무가설 기각
- 임상시험
- 신뢰구간: 혈압 감소 효과 5~12mmHg (0 포함 안 됨)
- 검정: p=0.004 -> 유의
- -> 같은 결론을 다른 언어로 표현
- 검정 방법 정하기
1. 변수 유형 (데이터 종류)
- 수치형 변수(양적) : 점수, 키, 몸무게, 매출액
- 평균/분산으로 비교
- 범주형 변수(질적) : 남/여, 광고 클릭/비클릭, 제품 A/B/C
- 개수/비율로 비교
2. 표본 수 (집단 몇 개?)
- 1표본: 한 집단 vs 기준값
- 우리반 평균 키 = 170cm?
- 2표본
- 독립: 남 vs 여
- 대응: 같은 사람 전/후 비교 (다이어트 전/후 체중)
- 3집단 이상: A/B/C 조건 비교
- 비료 종류에 따른 성장 차이?
3. 분포 성질 (수치형일때만)
- 정규성? -> 종 모양인가? (Q-Q plot, histogram, K-S test, Shapiro-Wilk)
- 등분산성? -> 집단 간 퍼짐이 비슷한가? (Levene test, Bartlett test)
- 이상치/비대칭? -> 불리하다면 비모수 검정 고려
- 상황별 비모수검정 방법

- 비모수는 "평균 차이"가 아니라 위치(중앙값)/순위 차이를 본다
- 비모수 = 단순한 버전 아님!!!!
- -> 평균 대신 순위/위치 비교 (질문 자체가 다름)
- 정규성 p>=0.05면 무조건 t검정 아님!!!!
- -> 이상치나 치우침 있으면 비모수가 안전

- ANOVA
- F분포
- F값: ANOVA에서 사용하는 검정통계량
- 집단 간 분산 / 집단 내 분산 -> 이 비율이 클수록 집단 간 차이가 크다
- 이렇게 계산된 F값은 F분포라는 확률분포를 따름
- F분포: 두개의 독립적인 카이제곱 분포의 비율로 만들어지는 분포
- ANOVA 외에도 회귀분석, 분산비교 등 다양한 검정에서 사용됨
- ANOVA는 3개 이상 집단의 평균 차이를 한번에 검정할 수 있는 방법이며 분산 구조를 분석함으로써 평균 차이를 판단!
- F값: ANOVA에서 사용하는 검정통계량
- F 분포와 기각역
- F 분포 오른쪽 꼬리 영역이 기각역
- 관측된 F값이 임계값 (F critical) 을 넘으면 -> p<0.05 -> H0 기각
- 넘지 못하면 -> H0 기각 못함

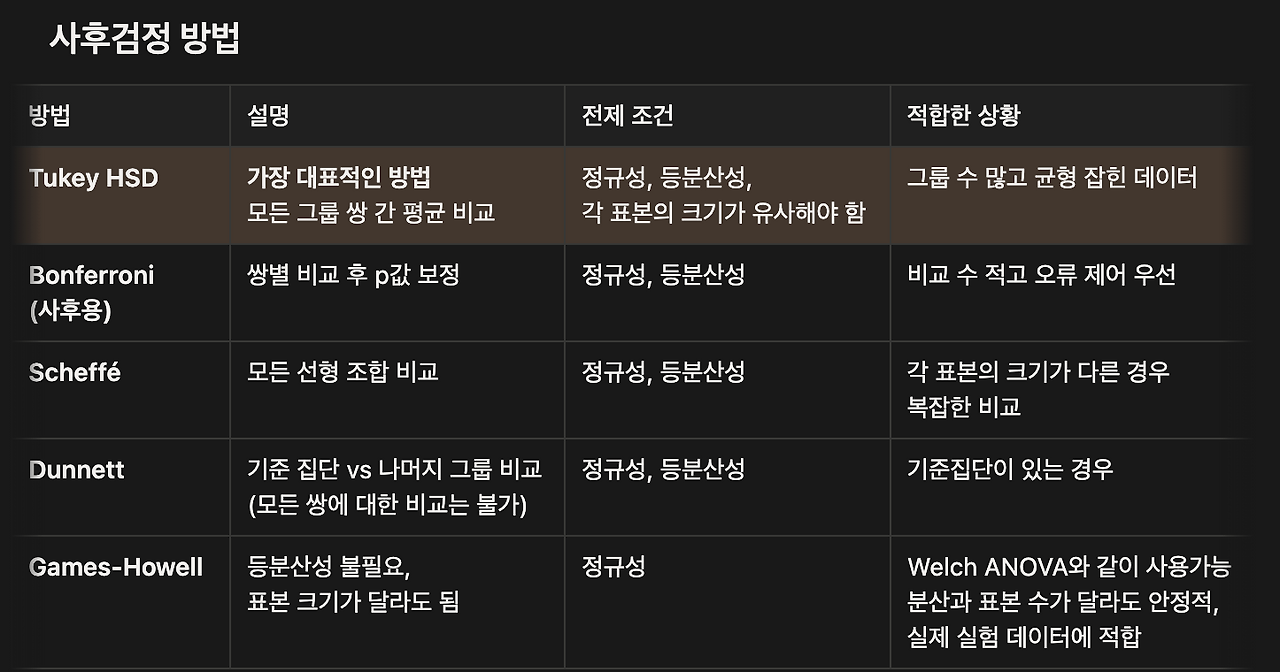
- 사후 검정 필요성
- ANOVA 유의 (p<0.05) -> 적어도 한 쌍이 다르다
- 하지만 어느 쌍이 다른지는 알려주지 않음
- 따라서 사후 검정 필요
- Tukey HSD: 모든 쌍 비교
- Dunnett: 대조군 vs 여러 실험군
- Williams: 용량-반응 패턴에서 유리

- 비율/범주형 - 평균 대신 확률 비교
- 범주형 데이터는 평균이 아니라 확률이 주인공
- 이항검정: 한 범주 비율이 기준과 같은가?
- 적합도검정: 전체 분포가 기준 분포와 같은가?
- 독립성검정: 두 범주형 변수가 서로 연관 있는가?
- 정규성
- Shapiro-Wilk
- H0 = 정규분포, p>=0.05 -> 정규 아님이라 말할 근거 부족
- Q-Q plot
- 데이터 분위수와 정규분포 분위수를 짝지어 점으로 그림
- 점들이 대각선 직선 근처면 정규에 가까움
- Shapiro-Wilk
- 등분산성
- Levene / Bartlett
- 위배시 대안
- 2집단: Welch t
- 3집단 이상: Welch ANOVA
- 문제 5.


'통계학 공부' 카테고리의 다른 글
| ANOVA, 카이제곱 검정과 상관분석 실습 (0) | 2026.02.18 |
|---|---|
| 통계학 세션 이론 5일차 (상관관계와 인과관계, A/B Test) (0) | 2026.02.18 |
| 통계학 세션 이론 3일차 (예언구간 vs 신뢰구간, 가설검정) (0) | 2026.02.18 |
| 통계학 세션 이론 2일차 (확률분포, 정규분포) (0) | 2026.02.18 |
| 통계학 세션 이론 1일차 (데이터 유형, 기술통계, 추론통계) (0) | 2026.02.18 |