[Today I Learn]
- SQL codekata
- Python codekata
- 오전 통계학 실습 세션
- 통계학 pdf 공부
[SQL codekata]
- 문제 1.
1. 문제 링크: https://www.hackerrank.com/challenges/weather-observation-station-9/problem
2. 정답 코드
select distinct city
from station
where city not regexp '^a|^e|^i|^o|^u'
- 문제 2.
1. 문제 링크: https://www.hackerrank.com/challenges/weather-observation-station-10/problem
2. 정답 코드
select distinct city
from station
where city not regexp 'a$|e$|i$|o$|u$'
- 문제 3.
1. 문제 링크: https://www.hackerrank.com/challenges/weather-observation-station-11/problem
2. 정답 코드
select distinct city
from station
where city not regexp '^a|^e|^i|^o|^u'
or city not regexp 'a$|e$|i$|o$|u$'[Python codekata]
- 문제 1.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120908?language=python3
2. 정답 코드
def solution(str1, str2):
if str2 in str1:
return 1
else:
return 2def solution(str1, str2):
return 1 if str2 in str1 else 2def solution(str1, str2):
answer = str1.split(str2)
if len(answer) == 1:
return 2
else:
return 1
- 문제 2.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120825
2. 정답 코드
def solution(my_string, n):
letters = []
for letter in my_string:
letters.append(letter*n)
answer = "".join(letters)
return answerdef solution(my_string, n):
return ''.join(i*n for i in my_string)def solution(my_string, n):
answer = ''
for m in my_string:
answer += (m * n)
return answer
[ 통계학 기초 vod ]
- 이항분포

- 결과가 두개가 나오는 상황일 때 사용하는 분포
- 이항분포는 연속된 값을 가지지 않고, 특정한 정수값만을 가질 수 있음
- e.g.) 동전을 10번 던질 때 앞면이 나오는 횟수는 0,1,2,...,10과 같은 정수임 따라서 이항분포가 연속적으로 그려지지 않음
- 이런 이항분포처럼 연속된 값을 가지지 않는 분포를 이산형 분포라고 지칭하기도 함
- 성공/실패와 같은 두가지 결과를 가지는 실험을 여러번 반복했을 때 성공 횟수의 분포임
- 독립적인 시행이 n번 반복되고, 각 시행에서 성공과 실패중 하나의 결과만 가능한 경우를 모델링하는 분포
- 성공확률을 p라고 할 때, 성공의 횟수를 확률적으로 나타냄
- 실험 횟수 n와 성공 확률 p 로 정의됨
# 이항분포 생성 (예: 동전 던지기 10번 중 앞면이 나오는 횟수)
binom_dist = np.random.binomial(n=10, p=0.5, size=1000)
# 히스토그램으로 시각화
plt.hist(binom_dist, bins=10, density=True, alpha=0.6, color='y')
plt.title('binomial distribution histogram')
plt.show()
- 푸아송 분포
- 희귀한 사건이 발생할 때 사용하는 분포
- 람다가 작을수록 사건이 희귀하다는 뜻! -> 왼쪽에 분포할 확률이 높음!
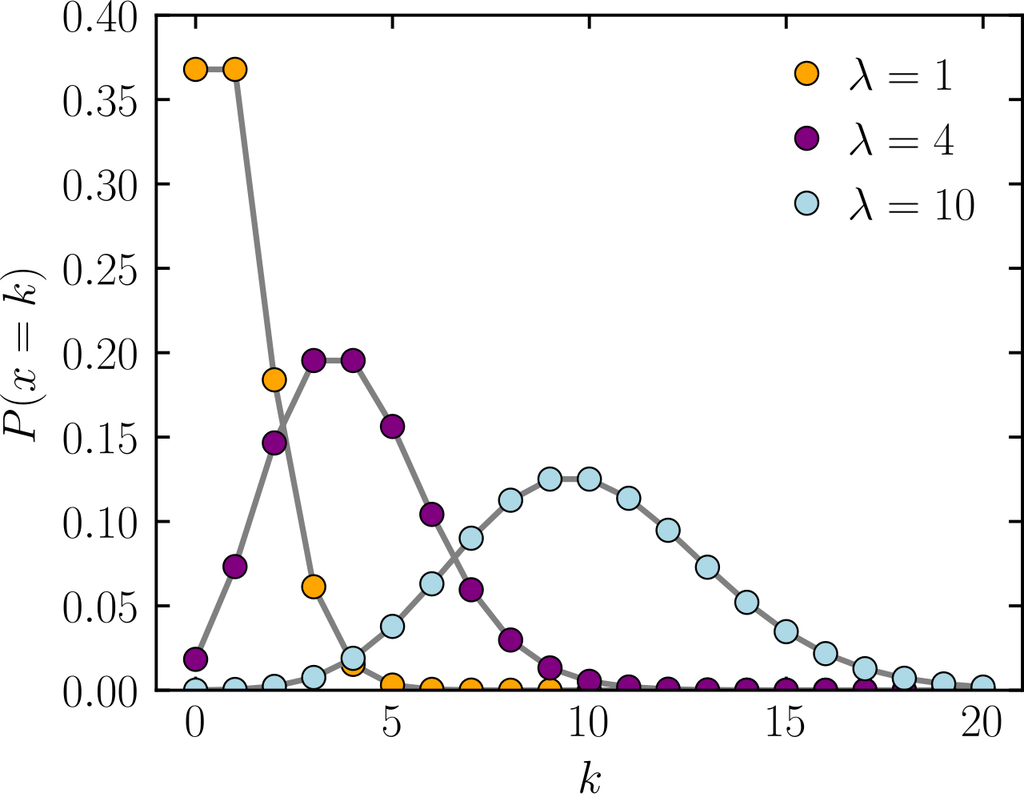
- 이항 분포처럼 연속된 값을 가지지 않기 때문에 이 분포도 역시 이산형 분포에 해당됨
- 평균 발생률 람다가 충분히 크다면 정규분포에 근사
- 평균 발생률이란 주어진 시간이나 공간에서 사건이 몇번 발생했는지?
- ex) 한 시간동안 콜센터에 전화오는 건수가 10건이면 람다는 10
- 단위시간 또는 단위 면적당 발생하는 사건의 수를 모델링 할 떄 사용하는 분포
- 푸아송 분포는 평균 발생률 람다를 가진 사건이 주어진 시간 또는 공간 내에서 몇 번 발생했는지를 나타냄
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import poisson
# 푸아송 분포 파라미터 설정
lambda_value = 4 # 평균 발생률
x = np.arange(0, 15) # 사건 발생 횟수 범위
# 푸아송 분포 확률 질량 함수 계산
poisson_pmf = poisson.pmf(x, lambda_value)
# 그래프 그리기
plt.figure(figsize=(10,6))
plt.bar(x, poisson_pmf, alpha=0.6, color='b', label=f'Poisson PMF (lambda={lambda_value})')
plt.xlabel('Number of Events')
plt.ylabel('Probability')
plt.title('Poisson Distribution')
plt.legend()
plt.grid(True)
plt.show()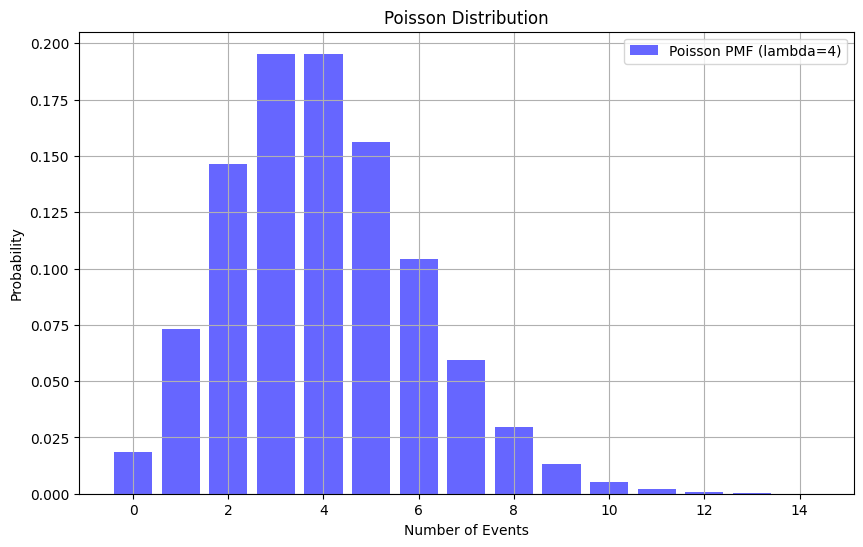
-분포 정리하기
- 데이터 수가 충분하다 -> (무조건) 정규분포에 근사
- 데이터 수가 작다 -> 스튜던트 t 분포
- 일부 데이터가 전체적으로 큰 영향을 미친다 -> 롱테일 분포 (파레토 분포)
- 범주형 데이터의 독립성 검정이나 적합도 검정 -> 카이제곱분포
- 결과가 두 개(성공 or 실패)만 나오는 상황 -> 이항 분포
- 특정 시간, 공간에서 발생하는 사건 -> 푸아송 분포
[ 오전 통계학 실습 세션 ]
- 주요 용어 정리
- 모수검정 Parametric Test : 모집단이 특정 분포(정규분포)를 따른다는 가정 하에 수행하는 검정
- 비모수검정 Nonparametric Test : 모집단 분포에 대한 가정 없이 수행하는 통계 검정
- Q-Q Plot Quantile-Quantile Plot : 데이터 분위수와 이론적 분위수를 비교하여 분포를 시각적으로 확인
- 카이제곱검정 Chi-square Test : 카이제곱 분포를 이용하여 범주형 데이터를 분석하는 검정 (적합도/독립성 등)
- 분산분석 Analysis of Variance (ANOVA) : 3개 이상 집단의 평균 차이를 검정하는 방법
- 사후검정 Post-hoc Test : ANOVA에서 유의한 결과가 나온 후 어떤 집단 쌍이 다른지 확인
- 사후분석 Post-hoc Analysis : 카이제곱 검정에서 유의한 결과가 나온 후 어떤 셀이 기대와 다른지 확인 (잔차 분석)


- 검정통계량 (t-statistic)
- 표본 데이터가 귀무가설(차이가 없다, 0이다)로부터 얼마나 벗어나있는지를 표준화된 단위로 변환한 값

- t 값은 데이터의 흩어짐(불확실성)을 고려했을 때, 평균 차이가 우연이라기엔 얼마나 큰가?를 나타내는 지표
- 정규성 검정
- Shapiro-Wilk 검정 (수치적 판단)
- 가장 널리 사용되는 정규성 검정.
- W 통계량이 1에 가까울수록 정규분포에 가까움
- p>0.05 : 정규성을 기각하지 못함 -> 모수 검정 사용 고려
- p<=0.05 : 정규성 기각 -> 비모수 검정 또는 변환 고려
- 주의: p>0.05는 '정규분포가 맞다'는 뜻이 아니라 '정규분포를 기각할 근거가 부족하다'는 뜻
- 한계: 표본이 크면(n>50) 사소한 편차에도 유의하게 나옴. 표본이 작으면(n<20) 상당히 비정규적이어도 기각하지 못할 수 있음 -> 따라서 Q-Q Plot 함께 판단하는 것이 중요함
- Q-Q Plot 해석 (시각적 판단)
- 데이터의 분위수를 이론적 정규분포의 분위수와 비교하는 그래프
- 점들이 대각선 위에 놓이면 정규분포를 따르고, 벗어나는 방향과 패턴으로 분포 특성을 파악함

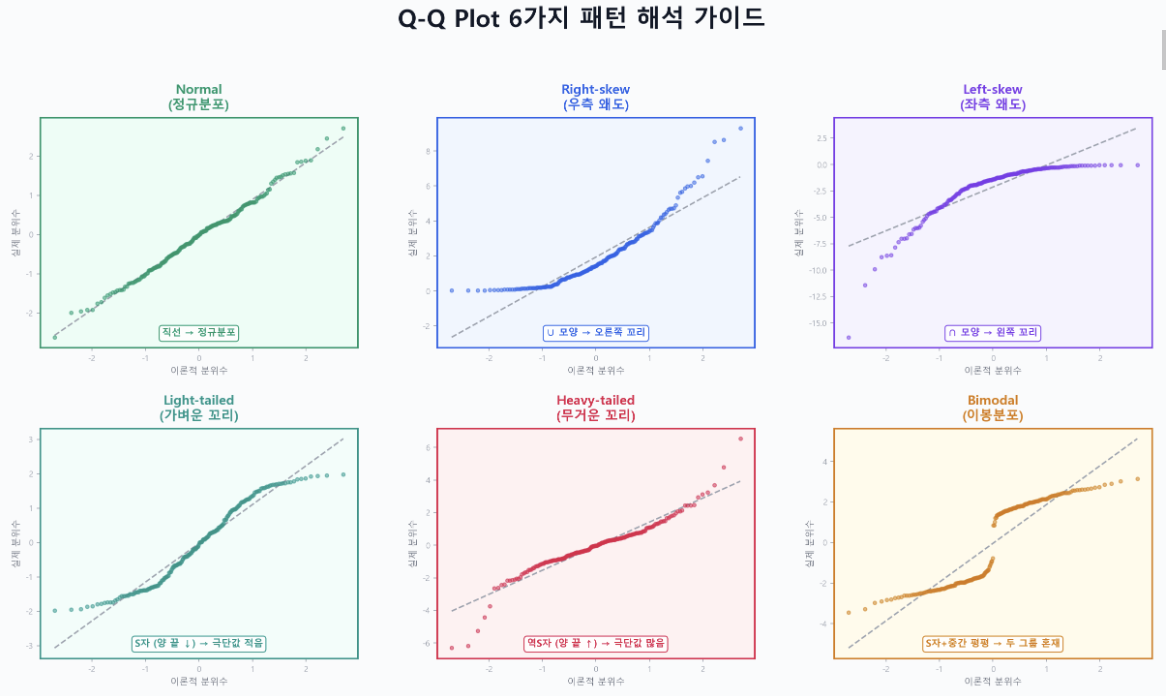
- 효과크기(Effect Size) 정리
- 효과크기는 p-value와 별개로, 차이나 관계의 실질적 크기를 나타냄
- p-value는 표본 크기에 크게 좌우되지만, 효과크기는 상대적으로 안정적이므로 반드시 함께 보고해야함

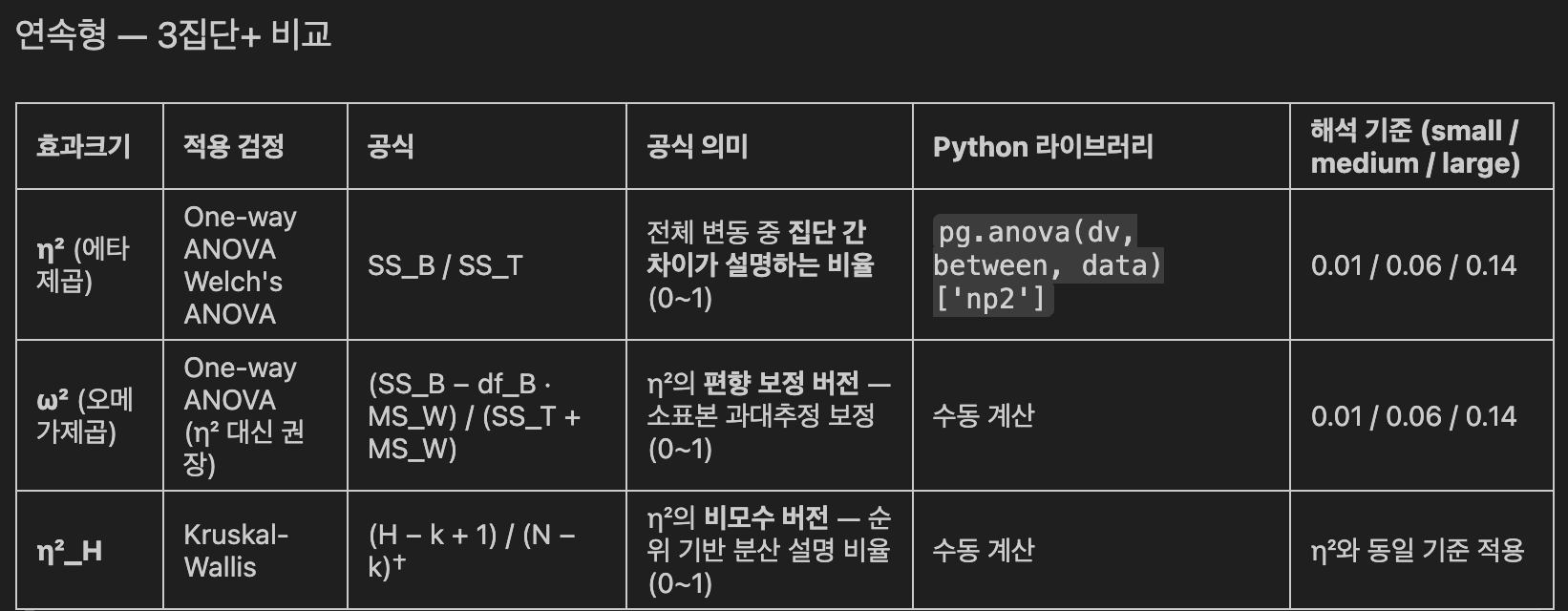

- 가정 검정 실습
# ── 시나리오 1: 단일표본 가정 검정 — 카페 대기 시간 ──
print("[시나리오 1] 단일표본 가정 검정 — 카페 대기 시간")
print("=" * 60)
# 표본 추출
np.random.seed(100)
wait_time = np.round(np.random.exponential(scale=5, size=25) + 2, 1)
mu0 = 5.0 # 전국 평균 대기 시간(분)
print(f" 표본 크기: {len(wait_time)}명")
print(f" 전국 평균(μ₀): {mu0}분")
print(f" 표본 평균: {wait_time.mean():.1f}분")
print(f" 표본 중앙값: {np.median(wait_time):.1f}분")
# ── Shapiro-Wilk 정규성 검정 ──
stats_sw1, p_sw1 = stats.shapiro(wait_time)
print(p_sw1) # 0.0006 < 0.05 : 정규성 기각- 정규성 기각
# ── 시나리오 1: 히스토그램 + Q-Q Plot ──
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
fig.suptitle("시나리오 1: 카페 대기 시간 분포 확인", fontsize=14, fontweight="bold")
# 히스토그램
axes[0].hist(wait_time, bins=10, color="#6366F1", alpha=0.7, edgecolor="white")
axes[0].axvline(mu0, color="#EF4444", linestyle="--", linewidth=2,
label=f"전국 평균(μ₀={mu0:.0f}분)")
axes[0].axvline(wait_time.mean(), color="#F59E0B", linestyle="-.", linewidth=2,
label=f"표본 평균={wait_time.mean():.1f}분")
axes[0].set_title("대기 시간 분포", fontsize=12, fontweight="bold")
axes[0].set_xlabel("대기 시간 (분)")
axes[0].set_ylabel("빈도")
axes[0].legend(fontsize=9)
axes[0].grid(alpha=0.3)
# Q-Q Plot
stats.probplot(wait_time, dist='norm', plot=axes[1]) # 2반쩨 얄에 그림
axes[1].set_title("Q-Q Plot", fontsize=12, fontweight="bold")
axes[1].set_xlabel("정규분포의 분위수")
axes[1].set_ylabel("표본의 분위수")
axes[1].legend(fontsize=9)
axes[1].grid(alpha=0.3)
plt.tight_layout()
plt.show()
# U : 모양에 가까움 --> 양의 왜도 (로그변환, 루트변환 고려)

- 시나리오1: 단일표본검정 - 카페 대기시간
- 카페 체인의 전국 평균 대기 시간은 5분, 한 지점에서 25명의 대기 시간을 조사하여, 이 지점의 대기시간이 전국 평균과 다른지 검정
# ── 시나리오 1: 검정 방법 선택 + 효과크기 ──
# 정규분포를 안따름
# 어떤 검정 방법? 비모수검정 --> Wilcoxon 부호 순위 검정
w_stats, p_val = stats.wilcoxon(wait_time - mu0)
print(p_val) # 0.3672 --> 귀무가설 지지
# 비모수 효과 크기 : rank-bserial r
import pingouin as pg
result_w = pg.wilcoxon(wait_time, np.full(len(wait_time), mu0))
r_effect = result_w['RBC'].values[0]
print(result_w)
print(r_effect) # 0.206
# 해석 |r| < 0.1 무시, 0.1~0.3 작은, 0.3~0.5 중간, 0.5보다 크면 큼!
# 효과 크기가 작다
# 최종 결론 --> 현재 지점의 대기시간이 전국평균과 같을 것이다!! (귀무가설)
# 만약 효과크기가 크다고 나온다면 샘플 개수를 보고 샘플을 늘려서 다시 실행을 해보는 것을 추천
# 효과크기는 p-val가 없다. 얼마나 차이가 큰지만 보는거라서 수치일 뿐 (RBC)- 시나리오 2: 대응표본 검정 - 수면 앱 효과
- 새로운 수면 앱의 효과를 검증하기 위해 20명의 사용 전후 수면 시간을 비교하려고 함
- 대응표본 t-검정을 사용하려면 차이값(전후 차이)의 정규성을 먼저 확인해야함
# ── 시나리오 2: 대응표본 가정 검정 ──
print("[시나리오 2] 대응표본 가정 검정 — 수면 앱 효과 검증")
print("=" * 60)
# 표본 추출
np.random.seed(200)
before_sleep = np.round(np.random.normal(6.0, 1.2, 20), 1)
after_sleep = before_sleep + np.round(np.random.normal(0.8, 0.6, 20), 1) # 평균 0.8시간 증가
diff_sleep = after_sleep - before_sleep
print(f" 참가자 수: {len(before_sleep)}명")
print(f" 사용 전 평균 수면: {before_sleep.mean():.1f}시간")
print(f" 사용 후 평균 수면: {after_sleep.mean():.1f}시간")
print(f" 평균 차이: {diff_sleep.mean():.2f}시간")
# ── 1) Shapiro-Wilk 정규성 검정 (차이값) ──
stats_sw, p_sw = stats.shapiro(diff_sleep)
# stats_sw: 검정통계량. 데이터가 정규분포 모양과 얼마나 유사한지를 나타내는 점수 (0~1)
# --> 1에 가까울수록 데이터가 완벽한 정규분포에 가까움.
# p_sw: p-value, 유의확률. 이 데이터가 정규분포를 따른다는 귀무가설이 맞을 확률
# --> 0.05보다 크다면 정규분포라고 가정해도 무방하다 (귀무가설 기각 실패 -> 정규성 만족함)
# --> 0.05보다 작으면 정규분포라고 볼 수 없다 (귀무가설 기각 -> 정규성 만족 못함)
print(stats_sw, p_sw ) #0.9364002873872243 0.2048475 > 0.05
# 해석: 정규성을 기각하지 못한다!- 정규성 검정 귀무가설은 "데이터가 정규분포를 따른다(데이터가 정규성을 만족한다)"
- stats_sw (검정통계량)
- 데이터가 정규분포 모양과 얼마나 유사한지를 나타내는 점수 (0~1)
- 1에 가까울수록: 데이터가 완벽한 정규분포에 가까움
- 작을수록: 정규분포 모양에서 벗어남
- 결과: 0.936이 나왔으므로, 데이터(diff_sleep)가 정규분포 모양과 상당히 유사하다고 볼 수 있음
- p_sw (p-value, 유의확률)
- 이 데이터가 정규분포를 따른다는 귀무가설이 맞을 확률
- 유의수준 0.05보다 큰 경우: 정규분포라고 가정해도 무방하다 (귀무가설 기각 실패 -> 정규성 만족)
- 유의수준 0.05보다 작은 경우: 정규분포라고 볼 수 없다 (귀무가설 기각 -> 정규성 만족 못함)
- 결과: 0.204가 나왔으므로 이는 0.05보다 크기 때문에 diff_sleep는 정규분포를 따른다고 판단할 수 있음
# ── Q-Q Plot (차이값) ──
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
fig.suptitle("대응표본 가정 검정 — 수면 앱 효과", fontsize=14, fontweight="bold")
# 차이값 Q-Q Plot
stats.probplot(diff_sleep, dist="norm", plot=axes[0])
axes[0].set_title("차이값 Q-Q Plot", fontsize=12, fontweight="bold")
axes[0].get_lines()[0].set_color("#3B82F6")
axes[0].get_lines()[0].set_markersize(5)
axes[0].get_lines()[1].set_color("red")
axes[0].grid(alpha=0.3)
# 차이값 히스토그램
axes[1].hist(diff_sleep, bins=8, color="#3B82F6", alpha=0.7, edgecolor="white")
axes[1].axvline(diff_sleep.mean(), color="red", linestyle="--", label=f"평균={diff_sleep.mean():.2f}")
axes[1].axvline(0, color="gray", linestyle=":", alpha=0.5, label="차이=0 (효과 없음)")
axes[1].set_title("차이값 분포", fontsize=12, fontweight="bold")
axes[1].set_xlabel("수면 시간 변화 (시간)")
axes[1].legend()
axes[1].grid(alpha=0.3)
# ── 2) 검정 방법 선택 ──
# 모수 검정 : 대응표본 t검정
# 등분산성 검사? 안한다
t_stat, t_p = stats.ttest_rel(after_sleep, before_sleep, alternative='greater')
# 효과 크기 : cohen's d
d = diff_sleep.mean() / diff_sleep.std(ddof=1)
size_d = '작다' if abs(d) < 0.5 else '중간' if abs(d) < 0.8 else '크다'
print(t_p, d, size_d)
# 지수표기법
# 4e-3 = 4*10^-3 = 0.004
# 1e-2 = 10^-2 = 0.01
# 1e-1 = 10^-1 = 0.1
# 1e1 = 10
# 1e2 - 10^2 = 100
# 3e3 = 3^10^3 = 3000
# 크다
# 해석
# p 값이 작다 --> 귀무가설 기각한다
# 효과 크기가 크다!
# 수면 어플이 효과가 있다- 흔한 오해
- 표본이 크면 정규성 검정이 불필요하다?
- 중심극한정리 덕분에 평균기반검정(t-검정, ANOVA)은 대표본에서 정규성 위반에 강건함
- 그러나 이것이 정규성 확인을 생략해도 된다는 뜻은 아님
- 실무적 권장
- 항상 분포를 확인하되, 대표본에서는 Q-Q Plot(시각적 판단)을 우선함
- Shapiro-Wilk가 유의하더라도 Q-Q Plot에서 대략 직선이면 모수검정 사용 가능
- Q-Q Plot에서도 심하게 벗어나면(극단적 왜도/이상치) 비모수 검정으로 전환
- 정규성과 별개로 등분산성/독립성 등 다른 전제 조건은 반드시 점검해야함
- 시나리오 3 : 독립표본 검정
- 두 가지 마케팅 전략(A, B)의 매출효과를 비교함.
- 매출 데이터는 로그정규분포를 따르므로 정규성 가정이 위반됨
# ── 2단계-A: 정규성 검정 (Shapiro-Wilk) ──
# 독립표본 비교에서는 각 집단의 정규성을 따로 확인합니다
stat_a, p_a = stats.shapiro(strategy_a)
stat_b, p_b = stats.shapiro(strategy_b)
# 하나만 정규성을 만족하면 --> 모수 검정을 할 수 있다? 없다? 둘다 만족해야 모수 검정을 한다
print(p_a, p_b) # 0.0174 0.00429--> 정규성을 만족하지 않을 것이다# ── 2단계-B: Q-Q Plot 시각적 확인 ──
# Q-Q Plot: 점들이 빨간 직선 위에 놓이면 정규분포, 벗어나면 비정규
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
for ax, data, name, color in [
(axes[0], strategy_a, "전략 A", "#3B82F6"),
(axes[1], strategy_b, "전략 B", "#F59E0B")
]:
# Q-Q Plot 그리기
stats.probplot(data, dist="norm", plot=ax)
# 점 색상 설정
ax.get_lines()[0].set_markerfacecolor(color)
ax.get_lines()[0].set_markeredgecolor(color)
# 제목에 Shapiro p-value 표시
sw_p = stats.shapiro(data).pvalue
ax.set_title(f"{name} Q-Q Plot (Shapiro p={sw_p:.4f})", fontsize=12, fontweight="bold")
ax.grid(alpha=0.3)
fig.suptitle("2. 정규성 확인",
fontsize=13, fontweight="bold", y=1.02)
plt.tight_layout()
plt.show()
# ── 2단계-C: 등분산 검정 (Levene) + 종합 판단 ──
# 독립 2집단 비교에서는 등분산 가정도 확인합니다
# 정규성을 만족하지 않음이 확인
# 등분산성을 체크할 필요가 있을까? 없을까?
# --> 원칙적으로 할 필요 없다. 정규성을 만족하지 않으면 무조건 비모수 검정으로 간다
# --> 정규성을 만족하는데 등분산성을 만족하지 않는 경우 --> Welch's
lev_stat_mv, lev_p_mv = stats.levene(strategy_a, strategy_b)
print(lev_p_mv) # 0.55 > 0.05 : 등분산성 가정을 충족한다# ── 3단계: Mann-Whitney U 검정 ──
u_stat, u_p = stats.mannwhitneyu(strategy_a, strategy_b, alternative='two-sided')
t_stat, t_p = stats.ttest_ind(strategy_a, strategy_b, equal_var=True)
print(u_p, t_p) # 0.7812157 0.6474080 > 0.05
# 해석 : 두 전략이 동등할 것이다 (귀무가설)
# 비모수 효과크기 rank-biserial correlation
r_rb = pg.mwu(strategy_a, strategy_b)
print(r_rb)
# U-val alternative p-val RBC CLES
# MWU 170.0 two-sided 0.781216 -0.055556 0.472222
print(r_rb['RBC'].values[0]) # 효과크기가 작다!- 흔한 오해
- 비모수는 항상 모수보다 나쁘다?
- No. 가정 위반 시 비모수가 더 정확함
- 표본이 크면 비모수 불필요?
- No. 대표본에서도 극단적 이상치가 있으면 평균과 분산이 왜곡되므로, 순위기반 비모수 검정이 여전히 유용함
- 비모수 = 평균 비교?
- 순위 기반 '분포 위치 비교'이며, 동일 분포 형태 가정 하에서만 중앙값 비교로 해석할 수 있음
- 비모수는 항상 모수보다 나쁘다?
[ 통계학 실습 과제 ]
print("\n[문제 2-1] 가설검정 5단계")
print("-" * 40)
mu_0 = 200 # 제조사 주장
alpha = 0.05
# TODO (a): 가설 설정
print("[1단계] 가설 설정")
print(f" H0: mu = {mu_0} (주장대로 200ml)")
print(f" H1: mu < {mu_0} (실제로는 200ml에 미달한다) -> 좌측검정") # 방향을 결정하세요
print(f" 검정 유형: 단일표본 t-검정 (one-sample t-test)")
print(f"\n[2단계] 유의수준: alpha = {alpha}")
# TODO (b): 검정 실행
# t_stat: 가설검정 판단용 검정통계량 (vs t_critical: 신뢰구간 계산용 임계값)
t_stat = stats.ttest_1samp(coffee_ml, popmean=mu_0)[0] # 현재 표본 데이터가 200(귀무가설)으로부터 얼마나 떨어져있는지 나타내는 값
p_value_two = stats.ttest_1samp(coffee_ml, popmean=mu_0)[1] # stats.ttest_1samp 결과 (양측)
p_value = p_value_two/2 # 단측이라면 /2, 양측이라면 그대로
print(f"\n[3단계] 검정통계량")
print(f" t-통계량: {t_stat}")
print(f"\n[4단계] p-value")
print(f" p-value (양측): {p_value_two}")
print(f" p-value (사용할 값): {p_value}")
# TODO (c): 결론
print(f"\n[5단계] 결론")
# TODO (d): [참고] 95% 신뢰구간
ci_95 = stats.t.interval(0.95, df=len(coffee_ml)-1, loc=np.mean(coffee_ml), scale=stats.sem(coffee_ml))
print(f"\n[참고] 95% 신뢰구간: {ci_95}")
print("p-value가 유의수준보다 낮아 귀무가설을 기각할 것으로 예상했고")
print("95% 양측 신뢰구간을 구할 경우 우리가 설정한 가설 검정을 하기에 적합하지 않기에 95% 단측 신뢰구간을 구하는 방식인 90% 양측 신뢰구간의 상한값을 확인해봐야겠다")
# TODO (e): [참고] 90% 양측 신뢰구간 = 95% 단측 신뢰구간
ci_90 = stats.t.interval(0.90, df=len(coffee_ml)-1, loc=np.mean(coffee_ml), scale=stats.sem(coffee_ml))
print(f"\n[참고] 90% 신뢰구간: {ci_90}")
mean_coffee = np.mean(coffee_ml)
sem_coffee = stats.sem(coffee_ml)
df = len(coffee_ml) - 1
# 2. t_critical (임계값): 95% 신뢰구간을 만들기 위한 t분포상의 기준값
# 단측 검정(H1 < 200)이므로, 상한선을 구하기 위해 왼쪽 꼬리가 아닌 오른쪽 꼬리 면적 등을 고려해야 함.
# 상한 경계선(Upper Bound)은 평균 + (t_critical * SE) 입니다.
# 95% 단측 신뢰구간의 t값은 90% 양측 신뢰구간의 t값과 같습니다.
t_critical = stats.t.ppf(1 - alpha, df=df) # 임계값
#상한 경계선
upper_bound = mean_coffee + t_critical * sem_coffee
print(f"자유도(df): {df}")
print(f"임계값(t_critical): {t_critical:.4f}")
print(f"95% 단측 신뢰구간 상한선: {upper_bound:.4f}")
print("신뢰구간 상한선이 199.59로 200 미만이므로 귀무가설을 기각하고 용량이 미달이라고 결론 지을 수 있다")
1. 문제 상황
- 시나리오: 자판기 커피 용량이 200ml 라는 제조사의 주장(H0)을 검증. 표본 20개를 측정했더니 평균이 약 196ml로 낮게 측정됨
- 검정 종류: 단일표본 t-검정 (One-sample t-test), 좌측검정 (H1 : µ < 200)
- 직면한 모순: p-value(0.03)는 0.05보다 작아 귀무가설을 기각해야 한다고 나왔으나, 일반적인 95% 양측 신뢰구간을 구했을 때 200이 포함되어 "기각할 수 없다"는 상반된 결과가 도출됨
2. 핵심 배움
A. 단측 검정과 신뢰구간의 매칭
- 개념: 가설검정의 방향(단측/양측)과 신뢰구간의 형태는 일치해야한다.
- 해걸: "200ml보다 작은가?"를 검정하는 좌측 검정(H1<200)에서는 단측 신뢰구간의 상한선을 확인해야한다
- 팁: 95% 단측 신뢰구간의 경계값은 90% 양측 신뢰구간의 경계값과 같다 (양쪽 5%씩 잘라낸 90% 신뢰구간의 한쪽 끝이 5% 단측 검정의 임계값과 일치함)
B. 검정통계량(t-test) vs 임계값(critical value)의 구분
- 혼동했던 점: 신뢰구간 상한선을 구할 때 t_stat (내 데이터의 t값) 을 사용하여 계산하려 했음
- 정정:
- t-stat(검정통계량): 내 데이터가 귀무가설(µ=200)로부터 표준오차의 몇 배만큼 떨어져 있는가? (가변적)
- t_critical(임계값): 유의수준(⍺=0.05)에서 기각역을 나누는 기준선은 어디인가? (고정적)
- 공식: 신뢰구간 상한선 = $\bar{X} + (t_{critical} \times SE)$
C. Python SciPy 함수 인자 주의 (Broadcasting Error)
- 에러 상황: stats.t.ppf를 사용할 때 결과값이 하나의 숫자가 아니라 20개의 리스트로 반환됨
- 원인: df(자유도) 인자 자리에 데이터 리스트(coffee_ml) 자체를 집어넣음. NumPy의 브로드캐스팅 기능이 작동하여 20개의 각기 다른 자유도에 대한 값을 모두 계산해버림
- 해결: 데이터 리스트가 아닌 정수형 자유도(len(coffee_ml) - 1)를 정확히 전달해야함
import numpy as np
from scipy import stats
# 1. 데이터 설정
coffee_ml = [...] # 측정 데이터
n = len(coffee_ml)
df = n - 1 # 자유도
alpha = 0.05 # 유의수준
# 2. 통계량 계산
mean_coffee = np.mean(coffee_ml)
sem_coffee = stats.sem(coffee_ml)
# 3. 임계값(Critical Value) 계산
# 주의: ppf 함수의 두 번째 인자는 데이터가 아니라 '자유도(df)'여야 함
# 단측 검정 95% 신뢰구간 = 양측 검정 90% 신뢰구간의 t값과 동일 논리
t_critical = stats.t.ppf(1 - alpha, df)
# 4. 상한 경계선(Upper Bound) 도출
upper_bound = mean_coffee + t_critical * sem_coffee
print(f"95% 단측 신뢰구간 상한선: {upper_bound:.4f}")
# 5. 결론 도출
if upper_bound < 200:
print("결론: 상한선이 200 미만이므로 귀무가설 기각 (용량 부족)")
else:
print("결론: 200이 포함되므로 귀무가설 기각 실패")
'[데이터분석] 부트캠프 TIL' 카테고리의 다른 글
| 20260213 TIL (0) | 2026.02.13 |
|---|---|
| 20260212 TIL (0) | 2026.02.12 |
| 20260210 TIL (0) | 2026.02.10 |
| 20260209 TIL (0) | 2026.02.09 |
| 20260206 TIL (0) | 2026.02.06 |