[Today I Learn]
- Python codekata
- 오전 통계학 실습 세션
- 오후 통계학 이론 세션
- 아티클 스터디
[Python codekata]
- 문제 1.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120889
2. 정답 코드
def solution(sides):
max_side = max(sides)
sides.remove(max_side)
if max_side < sum(sides):
return 1
else:
return 2def solution(sides):
sides.sort()
if sides[2] < sides[0]+sides[1]:
return 1
else:
return 2def solution(sides):
if max(sides) < sum(sides)-max(sides):
return 1
else:
return 2def solution(sides):
return 1 if max(sides) < sum(sides)-max(sides) else 2
- 문제 2.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120833?language=python3
2. 정답 코드
def solution(numbers, num1, num2):
return numbers[num1:num2+1]def solution(numbers, num1, num2):
answer=[]
for i in range (num1, num2+1):
answer.append(numbers[i])
return answer
- 문제 3.
1. 문제 링크: http://school.programmers.co.kr/learn/courses/30/lessons/120816
2. 정답 코드
import math
def solution(slice, n):
return math.ceil(n/slice)def solution(slice, n):
return ((n - 1) // slice) + 1
[ 오전 통계학 실습 세션 ]
- 데이터 유형 & 측정 척도
- 명목척도(nominal scale)
- 범주 구분. 순서나 크기 의미 x
- ex) 혈액형 정보
- -> 평균 구하면 안됨! (혈액형 평균은 의미없음)
- 서열척도, 순서척도 (ordinal scal)
- 범주형, 순서 측정
- ex) 학점 정보 (순서 정보는 있지만 구체적인 점수 간격 정보는 x)
- -> 원칙적으로 평균 부적절 (간격이 동일하다는 보장 없음)
- 단, 설문점수(만족도 1~5점)는 실무에서 등간으로 간주하고 평균을 구하는 것이 관행
- 등간척도 (interval scale)
- 수치형, 상대적 크기 차이 비교 가능
- ex) 섭씨온도의 경우 1도, 2도, 3도가 같은 간격으로 나누어져 속성 간의 상대적 차이를 가감하는 것이 가능
- but, 절대 0점, 절대0도는 정의할 수 없기 때문에 곱하기나 나누기를 할 수는 없음
- 즉, 영상 20도가 10도의 두배라고 할 수 없음
- 섭씨온도에서 0도가 있어 기준점이 있다고 할 수 있지만 사실상 0도는 수많은 물질 중 물의 어는점의 기준일 뿐 절대적인 0이라고 할 수 없음
- -> 평균은 OK, 하지만 "2배"라는 표현은 틀림
- 비율척도 (ratio scale)
- 순서에 관한 정보, 상대적 크기 정보, 절대적 기준을 통한 비율 정보까지 포함
- ex) 몸무게는 100kg이 50kg의 두배라고 할 수 있음 (절대 기준인 0kg이 존재함)
- but, 절대온도의 0은 비율척도임! (그렇게 정함)
- -> 모든 연산 가능
- 데이터 유형별 시각화 가이드 (단변량 분석)
- 수치형(연속)
- 히스토그램: 데이터 분포를 처음 파악할 때
- KDE (밀도그림): 여러 그룹의 분포를 겹쳐 비교할 때
- 박스플롯: 중심/퍼짐/이상치를 한 눈에 파악할 때
- 바이올린도표: 박스플롯 + 밀도를 동시에 보고싶을 때
- 수치형(이산)
- 막대그래프: 값이 정수인 경우 (평점 1~5, 자녀 수 등)
- 범주형(명목)
- 막대그래프: 남/여, 혈액형 등 그룹 크기 비교
- 파이차트: 항목이 적고(5개 이하) 비율 강조할 때
- 도넛차트: 핵심 수치를 중앙에 강조할 때
- 트리맵: 항목이 많거나 계층 구조가 있을 때
- 와플차트: 파이차트 대안, 퍼센트 강조할 때
- 범주형(순서)
- 막대그래프(순서 유지): 학점, 만족도, 등급 등 순서가 있는 범ㅁ주
- 데이터 유형별 시각화 가이드 (이변량 분석)
- 수치x수치
- 산점도: 두 변수의 관계 확인
- 히트맵: 여러 변수 상관관계 한눈에
- 수치x범주
- 그룹별 박스플롯: 그룹간 분포 비교
- 그룹별 바이올린: 그룹간 분포 + 형태 비교
- 그룹별 히스토그램: 그룹 분포 겹쳐 비교
- 시간x수치
- 선 그래프: 시간에 따른 변화 추세
- 영역 그래프: 추세+누적 크기 강조
- 다중 축 차트: 스케일이 다른 변수를 겹쳐 비교
- 범주x범주
- 누적 막대그래프: 교차 빈도/비율
- 모자이크 플롯: 교차 비율(면적)
숫자만 보면 이상치, 분포 형태, 패턴 등을 놓치기 쉬움. 분석 시 수치만 확인하지 말고 항상 시각화 수행하기
- 기술통계 핵심 요약
- 중심지표(대표 선수)
- 평균 (이상치에 많이 흔들림)
- 중앙값 (이상치에 거의 안 흔들림)
- 절사평균 (조금 흔들림)
- 가중평균 (많이 흔들림)
- 산포도(얼마나 퍼져있나)
- 표준편차 (이상치에 ㅁ많이 흔들림)
- IQR (거의 안흔들림)
- 변동계수 (CV) (많이 흔들림)
- 분포 모양
- 왜도 (좌우 대칭인가, 한쪽으로 치우쳤나)
- 첨도 (꼬리가 두꺼운가, 얇은가 - 극단값 빈도)
- 데이터 유형 탐색
print("\n" + "="*60)
print("Part 2: 데이터 유형 탐색")
print("="*60)
# (1) Iris(붓꽃) 데이터 로드
# - 붓꽃 150송이의 꽃잎/꽃받침 크기를 측정한 유명한 데이터
iris = load_iris()
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_df['species'] = iris.target
iris_df['species_name'] = iris_df['species'].map({
0: 'setosa', 1: 'versicolor', 2: 'virginica'
})
# (2) 데이터 칼럼 및 타입 확인
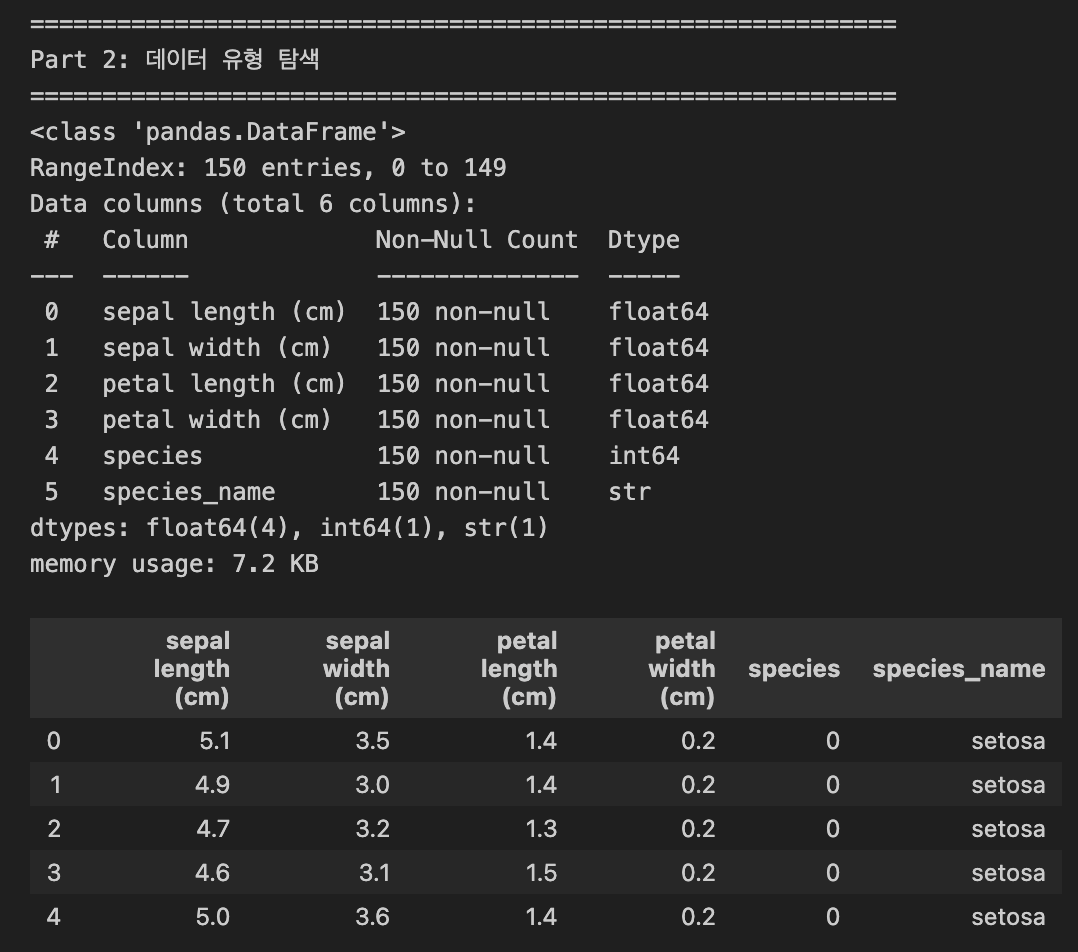
iris_df.info() # 수치형, 범주형 구분
display(iris_df.head()) # 샘플 데이터 확인- iris.target:
- iris 데이터셋의 정답지 (종속변수)
# (3) 수치형 데이터의 기술 통계를 한눈에 파악하기 위한 함수
display(iris_df.describe(include=['int','float']).round(2))
# (4) 범주형의 기술 통계를 한눈에 파악하기 위한 함수
display(iris_df.describe(include=['object','category']).round(2))
# (5) 범주형 데이터 빈도 확인
display(iris_df['species_name'].value_counts())
display(iris_df['species_name'].value_counts(normalize=True).round(2)) # 범주의 비율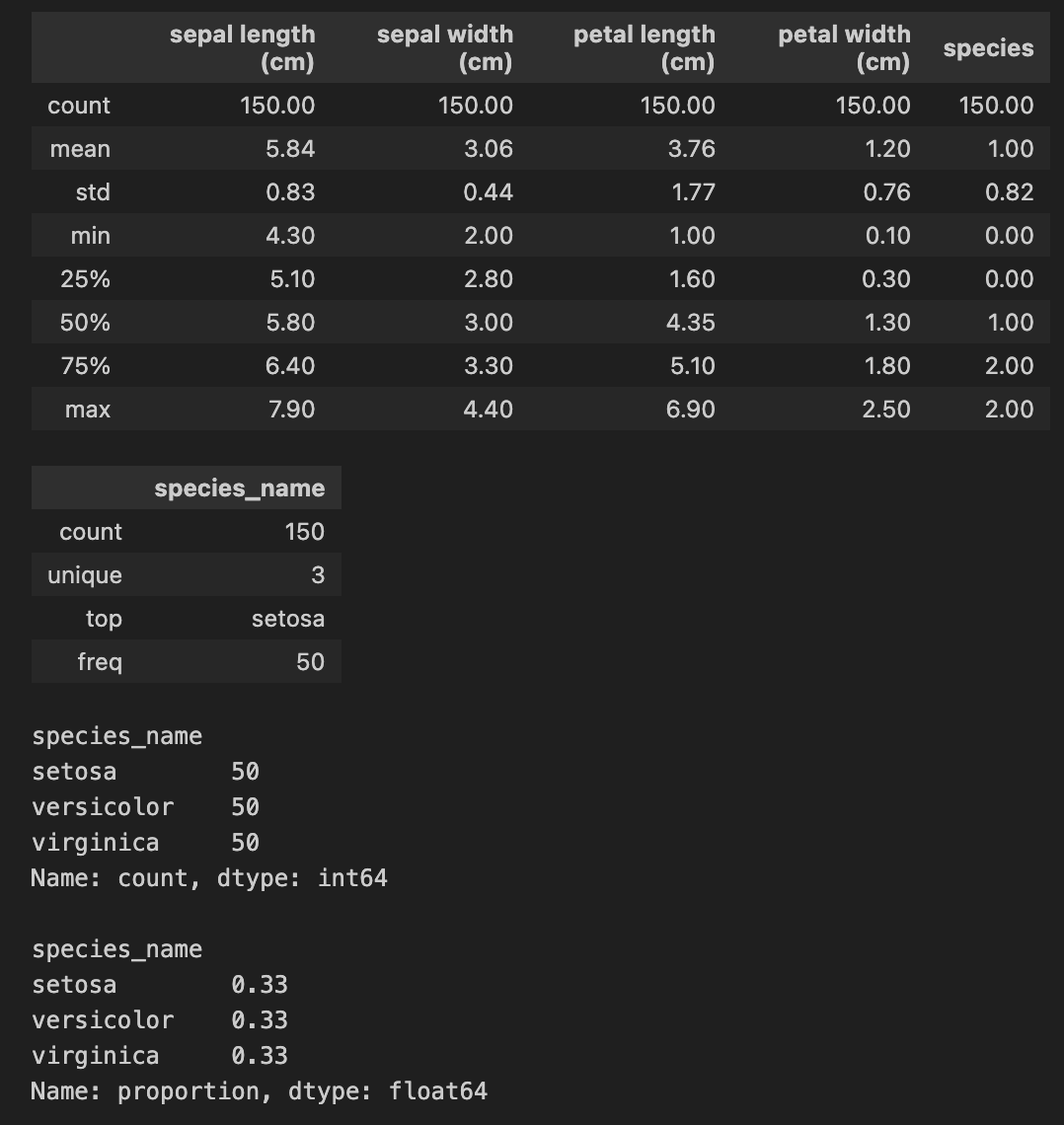
print("\n" + "="*60)
print("Wine 데이터 유형 탐색")
print("="*60)
# (1) Wine(와인) 데이터 로드
# - 이탈리아 3개 지역 와인 178개의 화학 성분을 분석한 데이터
wine = load_wine()
wine_df = pd.DataFrame(wine.data, columns=wine.feature_names)
wine_df['class'] = wine.target
wine_df['class_name'] = wine_df['class'].map({
0: 'class_0', 1: 'class_1', 2: 'class_2'
})
# (2) 데이터 칼럼 및 타입 확인
wine_df.info() # 수치형, 범주형 구분
display(wine_df.head()) # 샘플 데이터 확인
# (3) 수치형 데이터의 기술 통계를 한눈에 파악하기 위한 함수
display(wine_df.describe(include=['int','float']).round(2))
# (4) 범주형의 기술 통계를 한눈에 파악하기 위한 함수
display(wine_df.describe(include=['object','category']).round(2))
# (5) 범주형 데이터 빈도 확인
display(wine_df['class_name'].value_counts())
display(wine_df['class_name'].value_counts(normalize=True).round(2)) # 범주의 비율
- 기술통계 - 범주 데이터
# 범주 데이터 시각화: 막대도표 & 파이차트
fig, axes = plt.subplots(1, 2, figsize=(12, 5)) # 1행 2열 (1X2 그래프 그림)
# 데이터 준비
class_counts = wine_df['class_name'].value_counts()
# 막대 차트 (1행 1열)
axes[0].bar(class_counts.index, class_counts.values)
axes[0].set_xlabel('와인 클래스')
axes[0].set_ylabel('개수')
axes[0].set_title("막대차트 : 카테고리별 개수 비교")
axes[0].grid(True)
# 파이차트 (1행 2열)
axes[1].pie(class_counts.values, labels=class_counts.index, autopct='%.1f%%', startangle=90)
# 소숫점 한자리수까지 나타내고, 12시 시작하는 곳에서부터 파이차트 시작
axes[1].set_title('파이차트 : 전체 대비 비율확인')
plt.tight_layout()
plt.show()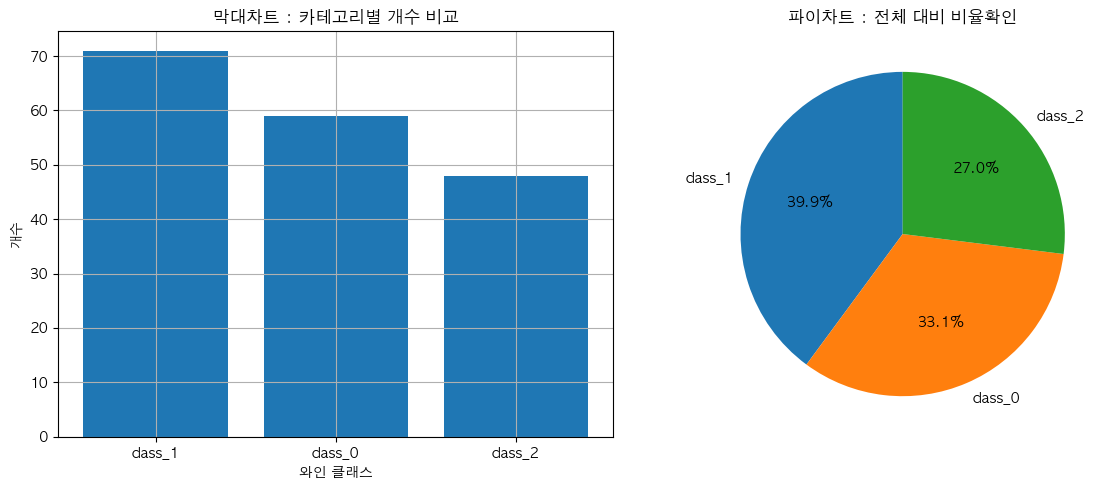
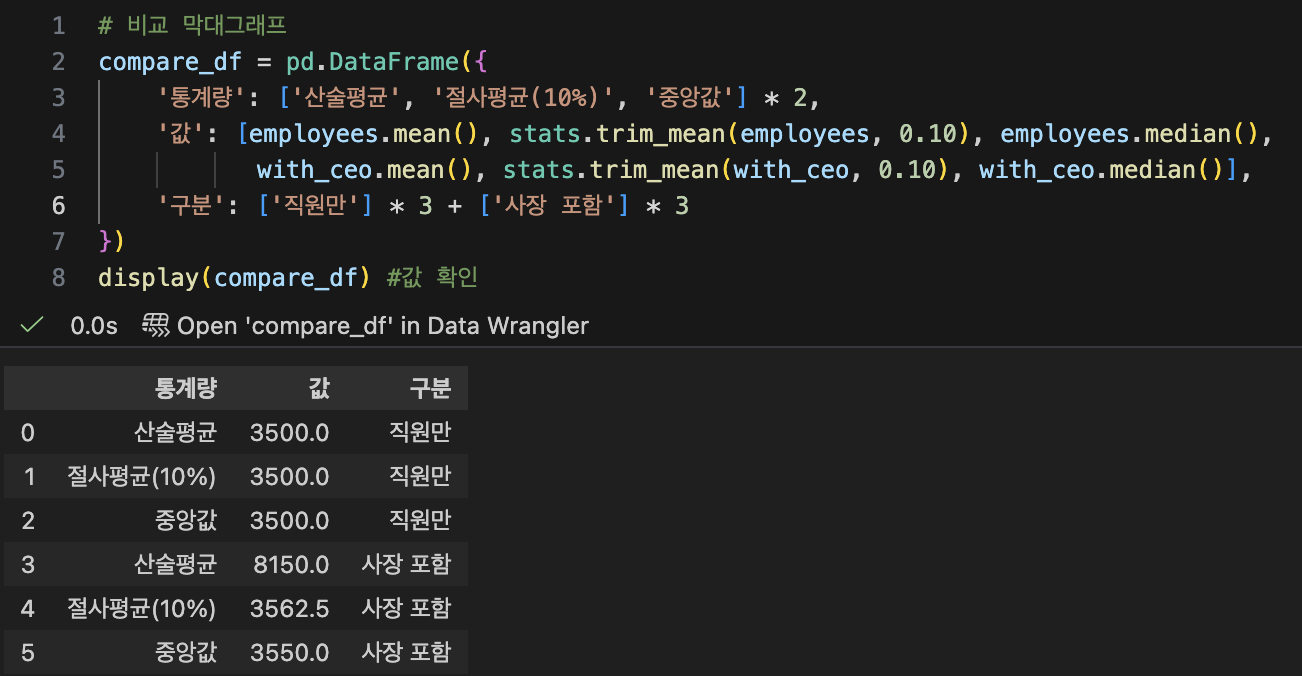
- 기술통계 - 중심 지표 (대표값)
| 대표값 | 장점 | 단점 | 언제쓰나? |
| 산술평균 | 계산이 쉽고 직관적, 모든 데이터 반영 | 이상치에 매우 민감 | 대칭 분포, 이상치 없을 때 |
| 중앙값 | 이상치에 강건함 | 극단값 정보 무시 | 비대칭 분포, 이상치 있을 때 (연봉, 집값) |
| 최빈값 | 범주형 데이터에 유일한 선택 | 수치형에서 의미 약함, 여러개 존재 가능 | 범주형 데이터 (혈액형, 선호도) |
| 절사평균 | 이상치 영향 줄이면서 평균의 장점 유지 | 절사 비율 선택이 주관적 | 평가 점수 (피겨스케이팅, 심사) |
| 가중평균 | 중요도 차이 반영 가능 | 가중치 설정이 주관적 | 학점계산, 포트폴리오 수익률 |

- 음의 왜도: 쉬운 시험 점수 (대부분 고득점, 일부 저득점)
- 대칭 분포: 키, 몸무게 등 자연현상
- 양의 외도: 연봉, 집값 (대부분 중간, 일부 매우 높음)

# Iris 꽃잎 길이 데이터 사용
petal_length = iris_df['petal length (cm)']
display(petal_length.head(10))
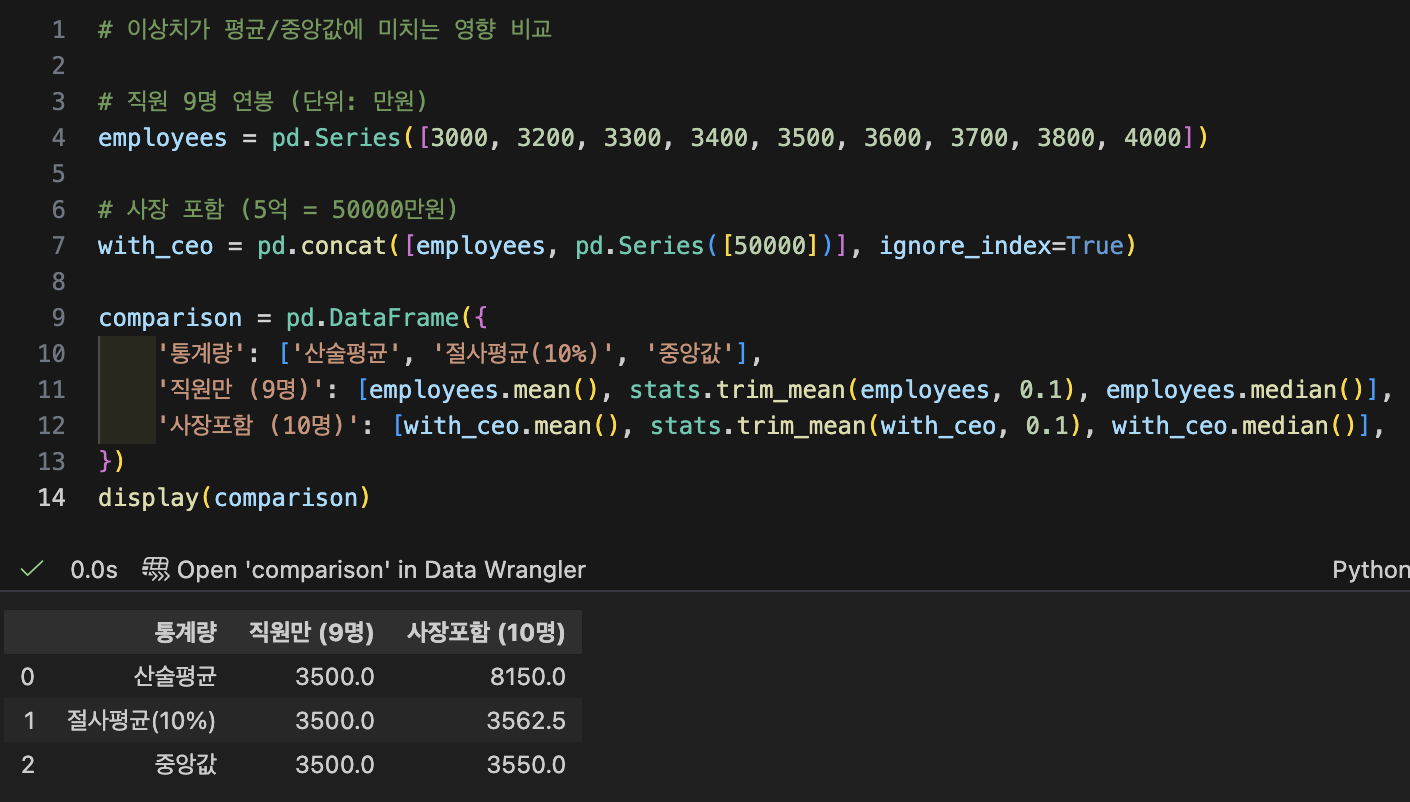
# (1) 산술평균 - 가장 흔한 "평균"
print(f'산술평균:{petal_length.mean():.2f}')
# (2) 절사평균 - 극단값을 잘라낸 평균
print(f'절사평균 (10%):{stats.trim_mean(petal_length, 0.1):.2f}') # 상,하 10% 제거 후 평균
print(f'절사평균 (20%):{stats.trim_mean(petal_length, 0.2):.2f}') # 상,하 20% 제거 후 평균
# (3) 가중평균 - 중요도에 따라 가중치를 다르게 주는 평균
# 각 붓꽃 종별로 가중 평균을 구하기
species_mean = iris_df.groupby('species_name')['petal length (cm)'].mean()
display(species_mean.round(2))
weights = np.array([50, 30, 20]) # 클래스별 가중치
weighted_mean = np.average(species_mean, weights=weights)
print(f'가중평균: {weighted_mean:.2f}')
# (1.46*50 + 4.26*30 + 5.55*20) / (50+30+20)
# (4) 중앙값 - 줄 세우고 한가운데 값
print(f'중앙값: {petal_length.median():.2f}')
# (5) 최빈값 - 가장 많이 나타나는 값
print(f'최빈값: {petal_length.mode().values}')


- 기술통계 - 산포도 (데이터가 얼마나 퍼져있나?)

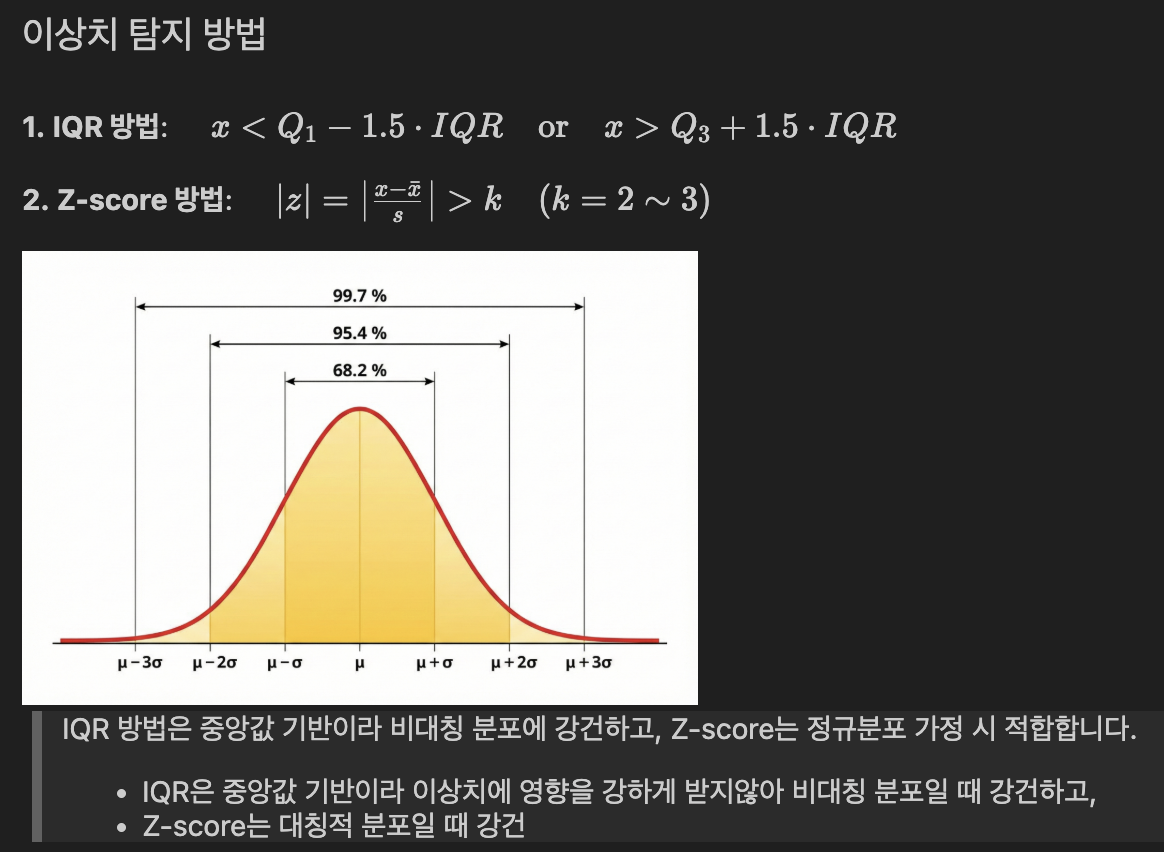
- 이상치 탐지 방법
# 실생활 예시: 같은 수익률, 다른 리스크
print("\n" + "="*60)
print("실생활 예시: 같은 평균 수익률, 다른 리스크")
print("="*60)
print("두 투자 상품의 평균 수익률이 모두 8%라면, 어떤 걸 고르겠습니까?")
# 두 투자 상품 시뮬레이션
investment_A = np.random.normal(8, 3, 10000) #평균 8, 표준편차 3, 데이터 개수 10000개의 데이터를 정규분포에서 샘플링
investment_B = np.random.normal(8, 10, 10000) #평균 8, 표준편차 10, 데이터 개수 10000개의 데이터를 정규분포에서 샘플링
invest_df = pd.DataFrame({
'구분': ['상품A', '상품B'],
'평균 수익률(%)': [investment_A.mean(), investment_B.mean()],
'표준편차(%)': [investment_A.std(), investment_B.std()],
'최악의 수익률': [investment_A.min(), investment_B.min()],
'최고의 수익률': [investment_A.max(), investment_B.max()],
})
display(invest_df.round(2))
# 시각화
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 히스토그램
axes[0].hist(investment_A, bins=20, alpha=0.6, color='blue', edgecolor='black',
label=f'A: 표준편차={investment_A.std():.1f}%', density=True)
axes[0].hist(investment_B, bins=20, alpha=0.6, color='red', edgecolor='black',
label=f'B: 표준편차={investment_B.std():.1f}%', density=True)
axes[0].axvline(0, color='black', linestyle=':', linewidth=1, label='손익분기점(0%)')
axes[0].set_xlabel('수익률 (%)')
axes[0].set_ylabel('밀도')
axes[0].set_title('수익률 분포: A는 모여있고, B는 넓게 퍼짐')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 박스플롯
bp = axes[1].boxplot([investment_A, investment_B],
labels=['A (안정형)', 'B (공격형)'],
patch_artist=True)
bp['boxes'][0].set_facecolor('lightblue')
bp['boxes'][1].set_facecolor('lightcoral')
axes[1].axhline(0, color='black', linestyle=':', linewidth=1)
axes[1].set_ylabel('수익률 (%)')
axes[1].set_title('박스플롯: 상자 크기 = 데이터가 퍼진 정도')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("\n" + "="*60)
print("Part 5: 기술통계 - 산포도")
print("="*60)
# Wine 알코올 도수 사용
data = wine_df['alcohol']
display(data.head())
# (1) 편차 - 각 값이 평균에서 얼마나 떨어져 있는가
deviations = data - data.mean()
print("편차 : ")
display(deviations.head())
# (2) 분산 - 편차 제곱의 평균
# 데이터의 개수가 많으면 모집단과 표본집단의 값은 비슷해진다.
print(f"분산 (모집단) : {data.var(ddof=0):.4f}")
print(f"분산 (표본집단) : {data.var(ddof=1):.4f}")
# (3) 표준편차 - 분산에 루트를 씌워서 원래 단위로 되돌림
print(f"표준편차 (모집단) : {data.std(ddof=0):.4f}")
print(f"표준편차 (표본집단) : {data.std(ddof=1):.4f}")
# (4) 범위 - 가장 단순한 산포 지표
print(f"범위(max-min) : {data.max() - data.min():.4f}")
# (5) 백분위수와 IQR
Q1 = data.quantile(0.25)
Q2 = data.quantile(0.5)
Q3 = data.quantile(0.75)
print(f"Q1: {Q1:.4f}")
print(f"Q2: {Q2:.4f}")
print(f"Q3: {Q3:.4f}")
print(f"IQR: {Q3 - Q1:.4f}")
# (6) 이상치 판별
# 6-1) IQR 기반 이상치 판별 방법
IQR = Q3 - Q1
iqr_lower = Q1 - 1.5 * IQR
iqr_upper = Q3 + 1.5 * IQR
iqr_outliers = data[(data < iqr_lower)| (data > iqr_upper)]
print('IQR 이상치:')
print('IQR 이상치 개수: ', len(iqr_outliers))
display(iqr_outliers.head())
# 6-2) Z-Score 방법
z_scores = (data - data.mean()) / data.std()
z_outliers_2 = data[np.abs(z_scores) > 2]
z_outliers_3 = data[np.abs(z_scores) > 3]
print('Z-score 이상치:')
print('|Z-score| > 2 이상치 개수:', len(z_outliers_2))
print('|Z-score| > 3 이상치 개수:', len(z_outliers_3))
# (7) 클래스별 산포도 비교
class_stats = wine_df.groupby('class_name')['alcohol'].agg([
('평균', 'mean'),
('분산', 'var'),
('표준편차', 'std'),
('최소', 'min'),
('Q1', lambda x: x.quantile(0.25)),
('Q2', lambda x: x.quantile(0.5)),
('Q3', lambda x: x.quantile(0.75)),
('최대', 'max'),
('범위', lambda x: x.max() - x.min()),
('IQR', lambda x: x.quantile(0.75) - x.quantile(0.25))
])
display(class_stats)

# 전체 알코올 도수 분포 + 이상치 기준선
fig, ax = plt.subplots(figsize=(10, 5))
data = wine_df['alcohol']
# 히스토그램
sns.histplot(data=wine_df, x='alcohol', kde=True, color='steelblue', ax=ax)
# IQR 이상치 기준
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
iqr_lower = Q1 - 1.5 * IQR
iqr_upper = Q3 + 1.5 * IQR
# Z-score 이상치 기준 (|Z| > 2)
z_lower = data.mean() - 2 * data.std()
z_upper = data.mean() + 2 * data.std()
# 기준선 표시
ax.axvline(iqr_lower, color='red', linestyle='--', linewidth=2, label=f'IQR 하한: {iqr_lower:.2f}')
ax.axvline(iqr_upper, color='red', linestyle='--', linewidth=2, label=f'IQR 상한: {iqr_upper:.2f}')
ax.axvline(z_lower, color='orange', linestyle=':', linewidth=2, label=f'Z=±2 하한: {z_lower:.2f}')
ax.axvline(z_upper, color='orange', linestyle=':', linewidth=2, label=f'Z=±2 상한: {z_upper:.2f}')
ax.set_title('전체 알코올 도수 분포 + 이상치 기준', fontsize=14, fontweight='bold')
ax.set_xlabel('알코올 도수')
ax.set_ylabel('빈도')
ax.legend(loc='upper right')
plt.tight_layout()
plt.show()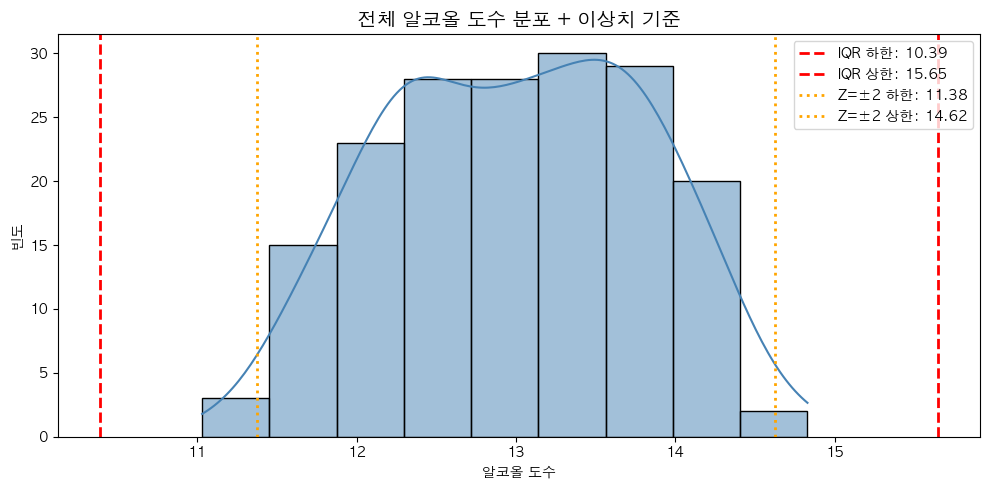
# 클래스별 알코올 도수 히스토그램
# - FacetGrid : 하나 이상의 범주형 변수 조합별로 동일한 차트를 나란히 비교할 때 사용
g = sns.FacetGrid(wine_df, col='class_name', height=5, aspect=1)
g.map_dataframe(sns.histplot, x='alcohol', kde=True, color='steelblue')
g.set_titles('{col_name}')
g.set_axis_labels('알코올 도수', '빈도')
g.figure.suptitle('클래스별 알코올 도수 분포', fontsize=14, fontweight='bold', y=1.02)
plt.tight_layout()
plt.show()
[ 오후 통계학 이론 세션 ]
- 이진 데이터와 범주 데이터 탐색
- 확률
- 확률변수 (Random Variable)
- 정규분포
- 표준화 (z-score)
https://myun0506.tistory.com/97
통계학 세션 이론 2일차 (확률분포, 정규분포)
[ 오후 통계학 이론 세션 ]- 이진 데이터와 범주 데이터 탐색히스토그램에서 막대들은 일반적으로 서로 붙어있고, 중간에 틈이 있ㄷ는 것은 그 부분에 해당하는 값들이 존재하지 않는다는 것을
myun0506.tistory.com
[ 아티클 스터디 ]
- 요약:
- 거래 후기 실험을 통해 당근마켓이 어떻게 성장해나가는지 소개
- 좋은 경험은 좋은 후기로 이어진다는 가설로 연결
- 상황에 맞는 방법 제시하여 실험 설계 후 실험 결과 분석함
- → 따뜻한 거래를 만들기 위해, 거래 후기 작성 비율을 증가시키려고 했고, 이를 위해 구매자에게 시스템 메시지를 발송하는 아이디어를 제안하여 실험 후 효과를 입증함
- 주요 포인트:
- 좋은 경험 → 좋은 후기
- 거래 후기를 주고받은 사용자가 더 높은 유지율을 보였고,
- 정성이 담긴 텍스트 후기를 받은 유저는 그보다 더 높은 유지율을 보였음
- 거래 후기 외에도 다양한 변수가 유지율에 영향을 주었겠지만, 거래 후기를 주고받는 행동이 서비스를 계속 이용하게 하는 원동력 중 하나가 된다고 가정할 수 있었음
- 좋은 경험을 확대하는 성장을 지향
- 정량적 경험은 거래내역에 남고,
- 정성적 경험은 거래후기에 담김
- → 거래 후기를 주고 받은 사용자가 더 좋은 서비스 경험을 하고 있다는 가정으로 거래 후기를 잘 작성하도록 유도하는 실험 설계!
- 실험
- 목표 설정
- 거래 여정에서 이웃 간 따뜻함을 느낄 수 있게 하기
- 현 상황 분석
- 구매자가 판매자보다 거래 후기를 덜 작성한다 (구매자에게 거래 후기 작성에 대한 동기 부족)
- 아이디어 수집
- 판매자가 게시글 상태를 거래 완료로 변경하는 시점에 구매자에게 채팅 메시지로 후기 작성을 유도하는 메시지 발송
- 가설 설정과 실험 설계
- 가설: 거래 완료한 게시글의 채팅 시스템 메시지로 거래 후기 작성을 유도하면 거래 후기 작성률이 높아질 것이다.
- 핵심지표: 구매자 중 거래완료 게시글에 후기를 작성한 비율
- 실험 결과 분석 및 서비스 반영 여부 결정
- 2주간 실험 진행 후 메시지를 받은 실험군의 거래 후기 작성률이 유의미하게 증가함을 확인
- 목표지표였던 구매자의 거래 후기만이 아닌, 판매자 후기 또한 증가
- 목표 설정
- 좋은 경험 → 좋은 후기
- 핵심 개념:
- 유지율(retention)
- 거래 후기 작성률
- 실험군
- 목표지표: 구매자의 거래 후기
- 용어 정리:
- 유지율(retention): 특정 기간 시작 지점에 있던 고객, 계약, 혹은 직원 등이 기간 종료 후에도 떠나지 않고 남아있는 비율
실생활에서 우리가 경험해봤을 예시여서 너무 이해가 잘됐고, 너무 우리 생활과 밀접해서 그냥 지나쳤을 법한 가설과 설계였는데 이를 진행하여 실제 변화로 이끌어낸 것이 진짜 데이터분석가 같고 멋있다....
나도 저렇게 할 수 있을까...?
[의미 있었던 의견]
- B2C에서 사용하는 구조(정략적 지표 : 리뷰)를 C2C에 대입하여 안정화된 결과를 도출
- 성장 실험은 수치적 개선도 물론 중요하지만, 해당 서비스가 지향하는 가치와 일관되어야 더 도움이 된다
[ VS Code Explorer에서 Git 상태 ]
- M (Modified) — 이미 Git에서 추적 중인 파일이 수정된 상태
- U (Untracked) — Git에서 아직 추적하지 않는 새로 생성된 파일
- A (Added) — git add로 스테이징 영역에 추가된 새 파일
- D (Deleted) — 삭제된 파일
- C (Conflict) — 브랜치 병합(merge) 시 충돌이 발생한 파일
- R (Renamed) — 파일 이름이 변경된 상태
- 초록 — 새 파일 (U, A)
- 노란/주황 — 수정됨 (M)
- 빨간 — 삭제 또는 충돌 (D, C)
- 회색 — 무시됨 (.gitignore에 포함된 파일)

'[데이터분석] 부트캠프 TIL' 카테고리의 다른 글
| 20260209 TIL (0) | 2026.02.09 |
|---|---|
| 20260206 TIL (0) | 2026.02.06 |
| 20260204 TIL (0) | 2026.02.04 |
| 20260203 TIL (0) | 2026.02.03 |
| 20260202 TIL (0) | 2026.02.02 |