[Today I Learn]
- 성취도평가 (SQL, Python, Pandas, 전처리, 시각화)
[오늘 배운 주제]
- Q1.
- SQL에서 집계함수는 count(*) 빼고 NULL 값은 집계되지 않음
- Q9.
import pandas as pd
s = pd.Series(["3", "x", "5"])
out = pd.to_numeric(s, errors="coerce")
print(out.tolist())
# [3.0, nan, 5.0]- errors="coerce"
- 숫자로 못 바꾸는 값을 NaN으로 강제 변환
- Q10.
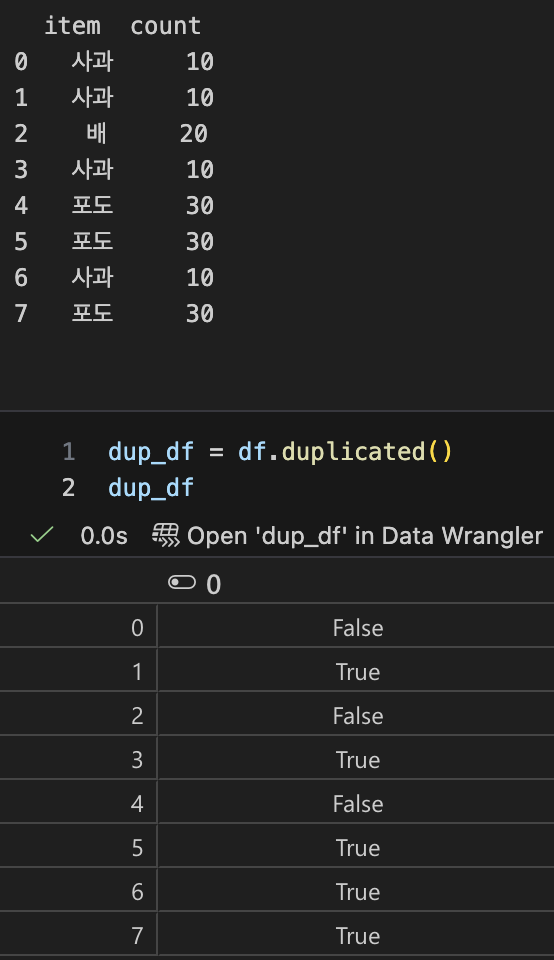
- duplicated()
- 기본 동작은 첫 등장만 False, 이후 중복은 True
- 3번 이상 중복도 첫번째 외에 나머지는 duplicated 결과로 True
- Q11.
import pandas as pd
df = pd.DataFrame({"x": [1, None]})
result = df["x"].fillna(0, inplace=True)
print(result)
# None
- Q3.
# 내가 작성한 코드
select r.rated_at, u.city, m.title, r.rating, r.review_status
from `260203_test`.ratings r
left join `260203_test`.movies m
on r.movie_id = m.movie_id
left join `260203_test`.users u
on r.user_id = u.user_id
where r.rated_at like '2026-01-03%'
and m.genre = 'Comedy'
and m.is_available = 1
and r.review_status in ('OK','SUSPECT')
and r.rating is not null;
# 답안
select r.rated_at, u.city, m.title, r.rating, r.review_status
from `260203_test`.ratings r
left join `260203_test`.movies m
on r.movie_id = m.movie_id
left join `260203_test`.users u
on r.user_id = u.user_id
where DATE(r.rated_at) = '2026-01-03'
and m.genre = 'Comedy'
and m.is_available = 1
and r.review_status in ('OK','SUSPECT')
and r.rating is not null
order by u.city asc, r.user_id as asc;- 내가 놓친 부분: order by 절 (결과는 똑같이 나와도 오름차순에 대한 정렬을 빠트림....)
- date(r.rated_at) :
- 날짜 필터는 like 대신 date() 함수를 사용하는 것을 더 추천
- Q4.
with city_ratings as (
select r.rated_at, u.city, m.title, r.rating, r.review_status
from `260203_test`.ratings r
left join `260203_test`.movies m
on r.movie_id = m.movie_id
left join `260203_test`.users u
on r.user_id = u.user_id
where r.rated_at like '2026-01-03%'
and m.genre = 'Comedy'
and m.is_available = 1
and r.review_status in ('OK','SUSPECT')
and r.rating is not null
)
select
city,
round(avg(rating),1) as avg_rating,
count(*) as rating_cnt
from city_ratings cr
group by city
order by avg_rating desc, city asc
limit 1;- 소수 1자리 반올림
- round(avg(rating), 1)
- 근데 나는 1자리에서 반올림하는거라 생각하고, 결과 창에서도 정수로 나오길래 round(avg(rating), 0) 이라 작성했는데,
- 0을 하든, 1을 하든 결과는 여기선 정수로 나오므로
- 만약 이 부분이 헷갈렸다면 미리 질문을 했어야할듯......
- Q8.
# 내가 쓴 답안
def sum_ignore_none(values):
sum = 0
for i in range(0, len(values)):
if values[i] == None:
continue
else:
sum+=values[i]
return sum
sum_ignore_none([1, None, 3])
# 튜터님 답안
def sum_ignore_none(values):
total = 0
for value in values:
if value is None:
continue
else:
total+=value
return total
sum_ignore_none([1, None, 3])- None 인지 확인하기 위해선 'is None' 사용하는걸 더 추천
- __eq__ 매직메서드에 잘못된 코드로 오버라이딩 되었을 경우를 예방하기 위해
- 값 비교만 하는 것인 '==' 보다는, 객체 자체를 비교하는 'is'를 사용하는게 더 적합할 듯
- Q13.
# 내가 작성한 코드
import pandas as pd
movies_df = pd.read_csv("movies.csv", encoding='utf-8')
ratings_df = pd.read_csv("ratings.csv", encoding='utf-8', parse_dates=["rated_at"])
users_df = pd.read_csv("users.csv", encoding='utf-8')
dup_cnt = ratings_df.duplicated(subset=['user_id','movie_id','rated_at']).sum()
print(f"dup_cnt: {dup_cnt}")
ratings_df = ratings_df.drop_duplicates(subset=['user_id','movie_id','rated_at'], keep="first")
ratings_df['rating_num'] = pd.to_numeric(ratings_df['rating'], errors="coerce")
df_full = ratings_df.merge(movies_df, on="movie_id", how="left")
df_full = df_full.merge(users_df, on="user_id", how="left")
df_clean = df_full[df_full["is_available"]==1 & df_full["review_status"].isin(["OK","SUSPECT"]) & ~df_full['rating_num'].isnull()]
print(f"rows: {len(df_clean)}")
# 튜터님이 작성하신 모범답안 코드
import pandas as pd
users = pd.read_csv("users.csv")
movies = pd.read_csv("movies.csv")
ratings = pd.read_csv("ratings.csv", parse_dates=["rated_at"])
dup_cnt = ratings.duplicated(subset=["user_id", "movie_id", "rated_at"]).sum()
print("dup_cnt:", dup_cnt)
ratings2 = ratings.drop_duplicates(subset=["user_id", "movie_id", "rated_at"], keep="first").copy()
ratings2["rating_num"] = pd.to_numeric(ratings2["rating"], errors="coerce")
df_full = (
ratings2
.merge(movies, on="movie_id", how="left")
.merge(users, on="user_id", how="left")
)
df_clean = df_full[
(df_full["is_available"] == 1) &
(df_full["review_status"].isin(["OK", "SUSPECT"])) &
(df_full["rating_num"].notna())
].copy()
print("rows:", len(df_clean))- df_clean에 조건필터링을 넣을 때 괄호를 안붙임!!
- 비트 연산자(&,|)가 비교 연산자(==,>,<)보다 우선순위가 높아 논리적 오류 발생함
- 조건필터링 걸땐 비트연산자(&, |) 앞에서 무조건 괄호로 감싸줘야함!!!
- ~df['col'].isnull() 대신 df['col'].notna() 사용하는 것을 추천
- 가독성 및 Pandas 전용 메서드 활용 최적화
- merge를 두문장으로 나누지 않고 바로 연결해서 두번 사용하면 한문장에 해결 가능
- Q14.
# 내가 평가 끝나고 수정해본 코드
import pandas as pd
movies_df = pd.read_csv("movies.csv", encoding='utf-8')
ratings_df = pd.read_csv("ratings.csv", encoding='utf-8', parse_dates=["rated_at"])
users_df = pd.read_csv("users.csv", encoding='utf-8')
dup_cnt = ratings_df.duplicated(subset=['user_id','movie_id','rated_at']).sum()
ratings_df = ratings_df.drop_duplicates(subset=['user_id','movie_id','rated_at'], keep="first")
ratings_df['rating_num'] = pd.to_numeric(ratings_df['rating'], errors="coerce")
df_full = ratings_df.merge(movies_df, on="movie_id", how="left")
df_full = df_full.merge(users_df, on="user_id", how="left")
df_clean = df_full[df_full["is_available"]==1 & df_full["review_status"].isin(["OK","SUSPECT"]) & ~df_full['rating_num'].isnull()]
df = df_clean[['city','genre','rating']]
agg_df = df.groupby(['city','genre'])['rating'].agg(
rating_cnt = "count",
avg_rating = "mean"
)
agg_df['avg_rating'] = agg_df['avg_rating'].round(1)
df = df.merge(agg_df, on=['city','genre'], how='left')
df = df.drop_duplicates(subset=['city','genre','rating_cnt','avg_rating'])
df = df[['city','genre','rating_cnt','avg_rating']].sort_values(by=['city','genre'], ascending=[True,True]).reset_index(drop=True)
df
# 튜터님 모범답안 코드
import pandas as pd
users = pd.read_csv("users.csv")
movies = pd.read_csv("movies.csv")
ratings = pd.read_csv("ratings.csv", parse_dates=["rated_at"])
ratings2 = ratings.drop_duplicates(subset=["user_id", "movie_id", "rated_at"], keep="first").copy()
ratings2["rating_num"] = pd.to_numeric(ratings2["rating"], errors="coerce")
df_full = (
ratings2
.merge(movies, on="movie_id", how="left")
.merge(users, on="user_id", how="left")
)
df_clean = df_full[
(df_full["is_available"] == 1) &
(df_full["review_status"].isin(["OK", "SUSPECT"])) &
(df_full["rating_num"].notna())
].copy()
summary = (
df_clean.groupby(["city", "genre"])
.agg(
rating_cnt=("rating_num", "size"),
avg_rating=("rating_num", "mean"),
)
.reset_index()
)
summary["avg_rating"] = summary["avg_rating"].round(1)
summary = summary.sort_values(["city", "genre"], ascending=[True, True])
print(summary)
- size vs count
- size는 결측치 포함 전체 칸수
- count는 결측치 포함 x
- sql의 count는 결측치 포함
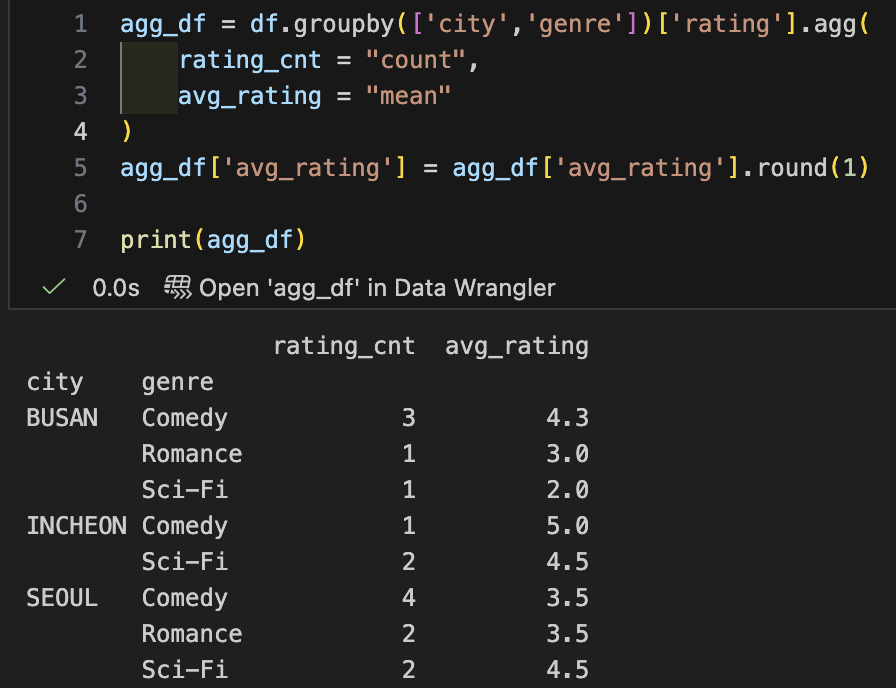
- groupby().agg() 코드
- 내가 쓴 코드에서 reset_index()를 했다면 merge를 하지 않았더라도 원하는 데이터프레임이 완성되었을것
- reset_index()를 안했을 때
- reset_index()를 했을 때
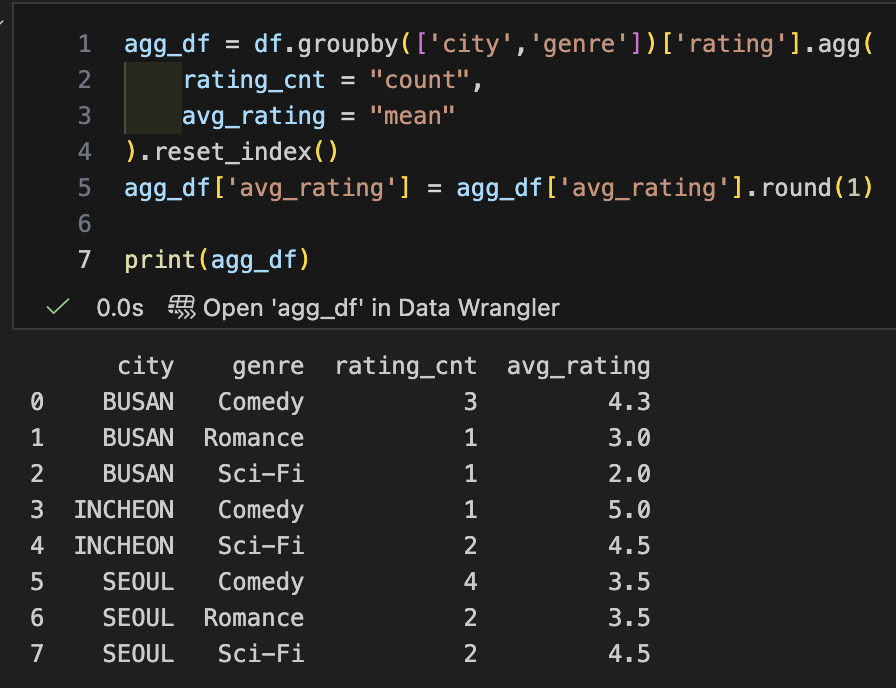
# 최종 수정코드
import pandas as pd
movies_df = pd.read_csv("movies.csv", encoding='utf-8')
ratings_df = pd.read_csv("ratings.csv", encoding='utf-8', parse_dates=["rated_at"])
users_df = pd.read_csv("users.csv", encoding='utf-8')
dup_cnt = ratings_df.duplicated(subset=['user_id','movie_id','rated_at']).sum()
ratings_df = ratings_df.drop_duplicates(subset=['user_id','movie_id','rated_at'], keep="first")
ratings_df['rating_num'] = pd.to_numeric(ratings_df['rating'], errors="coerce")
df_full = ratings_df.merge(movies_df, on="movie_id", how="left")
df_full = df_full.merge(users_df, on="user_id", how="left")
df_clean = df_full[(df_full["is_available"]==1) & (df_full["review_status"].isin(["OK","SUSPECT"])) & (df_full['rating_num'].notna())]
df = df_clean[['city','genre','rating']]
agg_df = df.groupby(['city','genre'])['rating'].agg(
rating_cnt = "count",
avg_rating = "mean"
).reset_index()
agg_df['avg_rating'] = agg_df['avg_rating'].round(1)
summary = agg_df.sort_values(["city", "genre"], ascending=[True, True])
print(summary)
- Q18.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
ratings_df = pd.read_csv("ratings.csv", encoding='utf-8', parse_dates=["rated_at"])
plt.figure(figsize=(6,4))
sns.countplot(ratings_df, x='review_status', order=["OK","SUSPECT","BAD"])
plt.title("Count of Ratings by Review Status")
plt.xlabel("Review Status")
plt.ylabel("Count")
plt.tight_layout()- sns.countplot에서 x축의 순서를 정하는 파라미터는 order!
- 성취도 평가 볼때 마지막에 추측성으로 적었던 코드에서 맞는 결과가 나온걸 보고 신났는데
- 답안 작성할 땐 이전에 적은 코드(order 없는 코드)로 제출했나봄......
- Pandas Index 관리 및 집계 최적화
1. 인덱스 파편화 원인
- Filtering: df[condition] 적용 시 조건에 맞지 않는 행만 제거되고 인덱스는 유지됨
- Sorting: sort_values() 수행 시 행의 순서는 바뀌지만 인덱스 번호는 행을 따라 이동함
- Dropping: drop_duplicates() 등 행 삭제 연산 후 인덱스에 '구멍'이 생김
2. 해결 방법: reset_index()
- drop=True: 기존의 파편화된 인덱스를 완전히 폐기하고 0부터 새로 부여함. (미지정 시 기존 인덱스가 index라는 이름의 새로운 컬럼으로 삽입됨)
- inplace=True: 새로운 객체를 생성하지 않고 원본을 수정하여 메모리 효율을 높임
3. 전공자적 관점의 설계 제언
- Merge 기반의 집계보다는 Groupby-Agg 패턴을 우선하기. 코드의 가독성뿐만 아니라 연산 성능에서 압도적인 차이가 발생
- 데이터 스키마 정의: 분석 목적에 맞는 최소한의 컬럼만 남기는 Column Pruning 습관화함
- 임경원 튜터님 튜터링
- 컨퍼런스 있으면 무조건 명함을 많이 가져가라!!!
- 내 개인정보를 주고 사은품을 많이 받아와라!!!!!
- 컨퍼런스는 평일에 가라
- 합법적 땡떙이 가능.....
- 점심은 근사한거 줄 수도 있음 웬만하면 기업 이미지 들어가있어서 신경써서 줌 (무료 점심 이득....)
- 부트캠프에서 만났던 분들 컨퍼런스에서 만날 확률 높음
- 여기 업계가 다 좁아서 가끔 이런데서 만날 확률 높음
- 통계나 머신러닝을 배우기 위해선 데이터 분석의 기본적인 감이 필요함
- 그래서 그동안 배웠던 것.
- 임경원 튜터님께서 우리한테 이번 부트캠프에서 얻어갔으면 하는 점은
- 취업을 하고 1년을 포기하지 않고 버티는 힘!!!!
- 이를 기르게 하는 것이 튜터님의 목표임
- 그래서 가이드를 주지 않는 것이
- 가이드를 주게되면 가이드대로만 따라가는 것에 익숙해져
- 가이드가 없을 경우 스스로 일을 찾아서 하지 못할 것임...
- 추천 다큐멘터리
- 고양이를 건드리지 마라 (Don't fxxk with cats)
'[데이터분석] 부트캠프 TIL' 카테고리의 다른 글
| 20260205 TIL (0) | 2026.02.05 |
|---|---|
| 20260204 TIL (0) | 2026.02.04 |
| 20260202 TIL (0) | 2026.02.02 |
| 20260129 TIL (0) | 2026.01.29 |
| 20260128 TIL (0) | 2026.01.28 |