[Today I Learn]
- SQL codekata
- Python codekata
- 통계학 vod
[SQL codekata]
- 문제 1.
1. 문제 링크: https://www.hackerrank.com/challenges/more-than-75-marks/problem
2. 정답 코드
select name
from students
where marks > 75
order by substr(name,-3,3) asc, id ascselect name
from students
where marks > 75
order by right(name,3) asc, id asc- right(문자열, 문자개수)
- 오른쪽 문자개수만큼 추출
[Python codekata]
- 문제 1.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120849
2. 정답 코드
import re
def solution(my_string):
answer = re.sub('a|e|i|o|u','',my_string)
return answerimport re
def solution(my_string):
answer = re.sub('[aeiou]','',my_string)
return answer- re.sub
- my_string 문자열에서 a/e/i/o/u의 문자들을 모두 빈칸으로 치환
def solution(my_string):
return ''.join(l for l in my_string if l not in "aeiou")def solution(my_string):
vowels = ['a','e','i','o','u']
for v in vowels:
my_string = my_string.replace(v,'')
return my_string
- 문제 2.
1. 문제 링크: https://school.programmers.co.kr/learn/courses/30/lessons/120824?language=python3
2. 정답 코드
def solution(num_list):
even = [i for i in num_list if i%2==0]
odd = [i for i in num_list if i%2!=0]
return (len(even),len(odd))def solution(num_list):
answer=[0,0]
for n in num_list:
answer[n%2]+=1
return answerdef solution(num_list):
odd = [n for n in num_list if n%2]
return [len(num_list)-len(odd),len(odd)]def solution(num_list):
odd = sum(1 for n in num_list if n%2) # 홀수 개수
return [len(num_list)-odd,odd]
[ 통계학 기초 vod ]
- A/B 테스트
- 두 버전(A와 B) 중 어느 것이 더 효과적인지 평가하기 위해 사용되는 검정 방법
- 마케팅, 웹사이트 디자인 등에서 많이 사용됨
- 사용자들을 두 그룹으로 나누고, 각 그룹에 다른 버전을 제공한 후, 반응을 비교
- 일반적으로 전환율, 클릭률, 구매수, 방문기간, 방문한 페이지수, 특정 페이지 방문 여부, 매출 등의 지표를 비교함
import numpy as np
import scipy.stats as stats
# 가정된 전환율 데이터
group_a = np.random.binomial(1, 0.30, 100) # 30% 전환율
group_b = np.random.binomial(1, 0.45, 100) # 45% 전환율
# t-test를 이용한 비교
t_stat, p_val = stats.ttest_ind(group_a, group_b)
print(f"T-Statistic: {t_stat}, P-value: {p_val}")- stats.ttest_ind
- 독립표본 t-검정을 수행하여 두 개의 독립된 집단 간 평균의 차이가 유의미한지 평가함
- 이 함수는 두 집단의 데이터 배열을 입력으로 받아서 t-통계량과 p-값을 반환함
- t-통계량
- 두 집단간 평균 차이의 크기와 방향을 나타냄
- t = 두 집단의 평균차이 / 표준 오차 (데이터의 불확실성)
- 분자(평균 차이): 두 약물의 효과 차이가 크면 클수록 t값은 커짐
- 분모(표준 오차): 데이터가 들쑥날쑥(변동성이 큼)하면 분모가 커져서 t값은 작아짐
- 즉, t값이 크다는 것은 "데이터의 변동성에 비해 두 집단의 평균 차이가 확실히 눈에 띈다"
- p-값
- 귀무가설이 참일 때 현재 데이터보다 극단적인 결과가 나올 확률
- 이 값이 유의수준보다 작으면 귀무가설을 기각하고 이 값이 유의수준보다 크면 귀무가설을 기각하지 않음
- t 값보다 더 바깥쪽에 있을 확률
- t-통계량
- 가설검정
- 표본 데이터를 통해 모집단의 가설을 검증하는 과정
- 즉, 데이터가 특정 가설을 지지하는지 평가하는 과정
- 귀무가설과 대립가설을 설정하고 귀무가설을 기각할지를 결정
- 두가지 전략을 취할 수 있음
- 확증적 자료분석
- 미리 가설들을 먼저 세운 다음 가설을 검증해 나가는 분석
- 탐색적 자료분석
- 가설을 먼저 정하지 않고 데이터를 탐색해보면서 가설 후보들을 찾고 데이터의 특징을 찾는 것
- 확증적 자료분석
- 통계적유의성
- 결과가 우연히 발생한 것이 아니라 어떤 효과가 실제로 존재함을 나타내는 지표
- p값은 귀무가설이 참일경우 관찰된 통계치가 나올 확률을 의미
- 일반적으로 p값이 0.05 미만이면 결과를 통계적으로 유의하다고 판단
- p-값
- 귀무가설이 참일 때, 관찰된 결과 이상으로 극단적인 결과가 나올 확률
- 일반적으로 p-값이 유의수준보다 작으면 귀무가설을 기각
- p-값을 통한 유의성 확인
- p-값이 0.03이라면 3%확률로 우연히 이러한 결과가 나올 수 있음
- 즉, 유의수준보다 낮은 확률!!!로 귀무가설이 참일 때 이러한 유의미한 결과가 나올 수 있음
- 효과가 없다면 0.03%의 확률로 이러한 결과가 나올텐데 이 확률이 굉장히 낮으니까 효과가 없다는 가설이 거짓이지 않을까?
- 가설검정
- 모수가 특정 값과 같은지 다른지 테스트
# 기존 약물(A)와 새로운 약물(B) 효과 데이터 생성
A = np.random.normal(50, 10, 100)
B = np.random.normal(55, 10, 100)
# 평균 효과 계산
mean_A = np.mean(A)
mean_B = np.mean(B)
# t-검정 수행
t_stat, p_value = stats.ttest_ind(A, B)
print(f"A 평균 효과: {mean_A}")
print(f"B 평균 효과: {mean_B}")
print(f"t-검정 통계량: {t_stat}")
print(f"p-값: {p_value}")
"""
A 평균 효과: 50.67957035675973
B 평균 효과: 54.549213204404225
t-검정 통계량: -2.7330499997739275
p-값: 0.006843169283450394
"""import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# 1. 자유도(df) 계산 (독립표본 t-검정의 경우: n1 + n2 - 2)
df = len(A) + len(B) - 2
# 2. t-분포 곡선을 그리기 위한 x축 설정
x = np.linspace(-4, 4, 1000)
y = stats.t.pdf(x, df) # t-분포의 확률밀도함수
plt.figure(figsize=(10, 6))
plt.plot(x, y, label='t-distribution (df={})'.format(df), color='black')
# 3. 계산된 t-통계량 위치에 수직선 긋기
plt.axvline(t_stat, color='red', linestyle='--', label=f'Calculated t-stat: {t_stat:.2f}')
# 4. p-값에 해당하는 영역 색칠하기 (양측 검정)
# t-통계량이 양수일 때 오른쪽 꼬리, 음수일 때 왼쪽 꼬리를 기준으로 색칠
x_fill = np.linspace(abs(t_stat), 4, 100)
plt.fill_between(x_fill, stats.t.pdf(x_fill, df), color='red', alpha=0.3, label='p-value area (one side)')
plt.fill_between(-x_fill, stats.t.pdf(-x_fill, df), color='red', alpha=0.3)
plt.title('T-Distribution and P-value Visualization')
plt.xlabel('t-value')
plt.ylabel('Density')
plt.legend()
plt.show()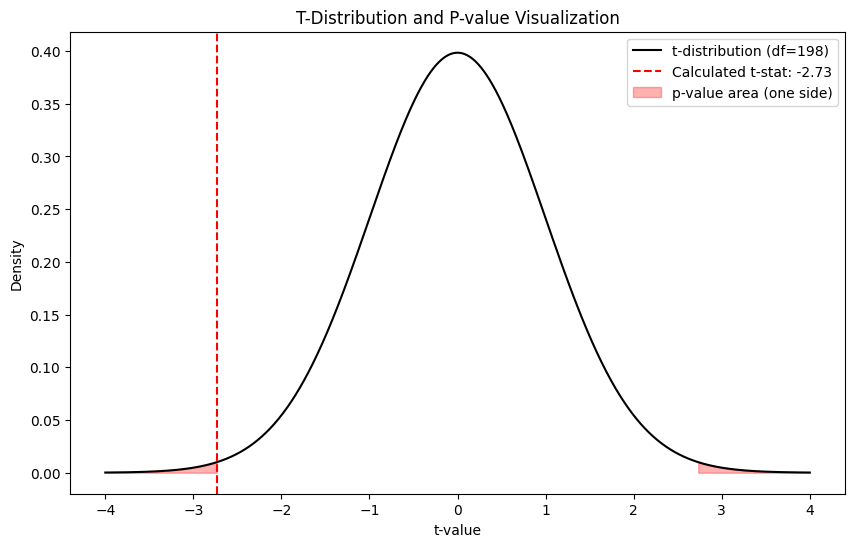
- p-value는 t 값 바깥쪽의 빨간 부분 적분한 값!
- t-value가 가운데 부분 (0에 가까운) 에 있다면 차이가 없다는 귀무가설이 일어날 법한 평범한 확률임
- but 바깥쪽 꼬리 부분에 있다면 차이가 이정도로 크게 날 확률은 매우 희박하다는 것을 보여주는 영역임.
- t-value 바깥쪽 면적(p-value)가 0.05보다 작게 나왔다는 것은 이런 극단적인 결과가 나올 확률이 5% 미만으로 매우 낮으니 이건 단순한 우연이 아니라 유의미한 차이다!!!라고 결론을 내리는 근거가 됨
- 가설 설정 (용의자 선상): "이 약물(B)은 기존 약물(A)이랑 똑같을 거야. (귀무가설)"
- 데이터 증거 수집: 실험을 해보니 효과 차이가 꽤 크게 났고, 그걸 계산해보니 $t$-통계량이 나왔습니다.
- 확률 계산 (p-value): "만약 진짜로 효과가 똑같다면(귀무가설이 참이라면), 이렇게 큰 차이가 날 확률이 **고작 3%($p=0.03$)**밖에 안 되는데?"
- 최종 결론: "3%라는 희박한 확률이 우연히 일어났다고 보기엔 너무 억지스러워. 차라리 '효과가 똑같다'는 처음 가설이 틀렸다고 보는 게 훨씬 합리적이야!"
즉, p-value가 작다는 건:
"우연이라고 하기엔 너무나도 '말이 안 되는(희귀한)' 상황이 벌어졌다. 그러므로 이건 우연이 아니라 실제 약물의 효과다!"라고 선언하는 것입니다.
- t 검정
- 두 집단 간의 평균 차이가 통계적으로 유의미한지 확인하는 검정방법
- 독립표본 t검정과 대응표본 t검정으로 나뉨
- 독립표본 t검정
- 두 독립된 그룹의 평균을 비교
- 대응표본 t검정
- 동일한 그룹의 사전/사후 평균을 비교
- 독립표본 t검정
- p-값을 통한 유의성 확인
- 두 클래스의 시험성적 비교 (독립표본 t검정)
- 다이어트 전후 체중 비교 (대응표본 t검정)
# 학생 점수 데이터
scores_method1 = np.random.normal(70,10,30)
scores_method2 = np.random.normal(75,10,30)
# 독립표본 t검정
t_stat, p_val = stats.ttest_ind(scores_method1, scores_method2)
print(f"T-statistic: {t_stat}. P-value: {p_val}")
# T-statistic: 0.18014269599828237. P-value: 0.8576684770959845
- 다중검정
- 여러 가설을 동시에 검정! 하지만 오류가 발생할 수 있음!
- 각 검정마다 유의수준을 조정하지 않으면 1종 오류 (귀무가설이 참인데 기각하는 오류) 발생 확률이 증가
- 보정 방법
- 본페르니 보정, 튜키 보정, 던넷 보정, 윌리엄스 보정 등
- 가장 대표적이고 기본적인게 본페로니 보정
# 세 그룹의 데이터 생성
np.random.seed(42)
group_A = np.random.normal(10, 2, 30)
group_B = np.random.normal(12, 2, 30)
group_C = np.random.normal(11, 2, 30)
# 세 그룹 간 평균 차이에 대한 t 검정 수행
p_values = []
p_values.append(stats.ttest_ind(group_A, group_B).pvalue)
p_values.append(stats.ttest_ind(group_B, group_C).pvalue)
p_values.append(stats.ttest_ind(group_C, group_A).pvalue)
# 본페로니 보정 적용
alpha = 0.05
adjusted_alpha = alpha / len(p_values)
# 결과 출력
print(f"본페로니 보정되기 전 유의 수준: {alpha:.4f}")
for i, p in enumerate(p_values):
if p < alpha:
print(f"검정 {i+1}: 유의미한 차이 발견 (p={p:.4f})")
else:
print(f"검정 {i+1}: 유의미한 차이 없음 (p={p:.4f})")
# 결과 출력
print(f"본페로니 보정된 유의 수준: {adjusted_alpha:.4f}")
for i, p in enumerate(p_values):
if p < adjusted_alpha:
print(f"검정 {i+1}: 유의미한 차이 발견 (p={p:.4f})")
else:
print(f"검정 {i+1}: 유의미한 차이 없음 (p={p:.4f})")
# 본페로니 보정되기 전 유의 수준: 0.0500
# 검정 1: 유의미한 차이 발견 (p=0.0000)
# 검정 2: 유의미한 차이 없음 (p=0.1461)
# 검정 3: 유의미한 차이 발견 (p=0.0058)
# 본페로니 보정된 유의 수준: 0.0167
# 검정 1: 유의미한 차이 발견 (p=0.0000)
# 검정 2: 유의미한 차이 없음 (p=0.1461)
# 검정 3: 유의미한 차이 발견 (p=0.0058)- 본페로니 보정
- 유의수준을 p_value의 개수로 나누어 더 기준을 타이트하게 만듦 (그룹이 3개여서 p_values가 3개로 나옴..)
- 이번 사례에서는 본페로니 보정을 하기 전과 한 후의 결과가 같지만 실무에선 달라지는 경우 많음
- 귀무가설
- 언제나!!! '차이가 없다', '특별한 일이 일어나지 않았다', '서로 관련이 없다'는 보수적인 입장!
- 독립성 검정
- 귀무가설: 변수간 상관이 없다 (독립이다)
- p값이 유의수준보다 낮으면 귀무가설 기각이니까 연관이 있다, 즉 독립이 아니다
- p값이 유의수준보다 높으면 귀무가설 채택이니까 연관이 없다, 독립이다.
- 적합도 검정
- 귀무가설: 예상과 차이가 없다 (일치한다)
- P값이 유의수준보다 낮으면 귀무가설 기각이니까 차이가 있다, 즉 관측 분포와 기대 분포가 일치하지 않는다 (정상이 아니다)
- p값이 유의수준보다 높으면 귀무가설 채택이니까 차이가 없다, 즉 관측 분포와 기댓값이 일치한다 (정상이다. 골고루 나온다)
- 카이제곱검정
- 범주형 데이터의 표본분포가 모집단 분포와 일치하는지 검정 (적합도 검정)
- 두 범주형 변수 간의 독립성을 검정 (독립성 검정)
- 적합도 검정
- 관찰된 분포와 기대된 분포가 일치하는지 검정
- p값이 높으면 관측분포와 기댓값에 차이가 있다
- p값이 낮으면 관찰된 분포가 기대된 분포에 일치한다
- 독립성 검정
- 두 범주형 변수 간의 독립성을 검정
- p값이 높으면 귀무가설대로 두 범주형 변수에 연관성이 없다, 즉 독립이다
- p값이 낮으면 귀무가설 기각으로 두 범주형 변수에 연관성이 있다, 즉 독립성이 없다
# 적합도 검정
observed = [20, 30, 25, 25]
expected = [25, 25, 25, 25]
chi2_stat, p_value = stats.chisquare(observed, f_exp=expected)
print(f"적합도 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")
# 적합도 검정 카이제곱 통계량: 2.0, p-값: 0.5724067044708798
# p-value가 0.05보다 큼 --> 귀무가설대로 관측값과 기댓값에 차이가 없다
# 독립성 검정
observed = np.array([[10, 10, 20], [20, 20, 40]])
chi2_stat, p_value, dof, expected = stats.chi2_contingency(observed)
print(f"독립성 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")
# 독립성 검정 카이제곱 통계량: 0.0, p-값: 1.0
# p-value가 0.05보다 큼 --> 두 범주형 변수는 연관이 없다 --> 독립이다
# 나이와 흡연 여부 독립성 검정
observed = np.array([[30, 10], [20, 40]])
chi2_stat, p_value, dof, expected = stats.chi2_contingency(observed)
print(f"독립성 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")
# 독립성 검정 카이제곱 통계량: 15.041666666666666, p-값: 0.00010516355403363106
# p-value가 0.05보다 작음 --> 귀무가설 기각 --> 두 범주형 변수는 연관이 있다 --> 독립성이 없다
- 제 1종 오류와 제 2종 오류
- 제 1종 오류 (위양성)
- 효과가 있다고 했는데 사실은 효과가 없는 것
- 귀무가설을 기각을 했는데 사실은 귀무가설이 맞았던 것
- 귀무가설을 기각할 기준을 더 강화하면 위양성 가능성이 낮아짐
- --> 유의수준(⍺)을 더 낮추면 제 1종 오류 제어 가능
- 제 1종 오류가 발생할 확률 = ⍺
- 다중검정시 제 1종 오류가 증가하는 이유?
- 하나의 검정에서 제 1종 오류가 발생하지 않을 확률은 1-⍺
- m개의 독립된 검정에서 제 1종 오류가 전혀 발생하지 않을 확률은 (1-⍺)^m
- m개의 검정에서 하나 이상의 제 1종 오류가 발생할 확률은 1-(1-⍺)^m
- 이 값은 m이 커질수록 빠르게 증가함
- e.g.) ⍺=0.05, m=10 --> 1-(1-0.05)^10 ≈ 0.401
- 즉, 10개의 가설을 동시에 검정할 때 하나 이상의 가설에서 제 1종 오류가 발생할 확률이 약 40.1%이므로 개별검증에서 발생하는 오류율(5%)보다 높음
- 제 2종 오류 (위음성)
- 효과가 없다고 했는데 사실은 효과가 있는 것
- 귀무가설이 거짓인데 기각하지 않는 오류
- 제 2종 오류가 발생할 확률 = ß
- 제 2종 오류가 발생하지 않을 확률 = 검정력 (1-ß)
- 하지만 이를 직접 통제할 수는 없음
- 그나마 통제 해볼 수 있는 방법으로는...
- 표본크기 n이 커질수록 ß가 작아짐 (더 좋은 방법)
- ⍺와 ß는 상충관계에 있어서 너무 낮은 ⍺를 가지게 되면 ß는 더욱 높아짐
- 단순선형회귀
- 하나의 독립변수(X)와 하나의 종속변수(Y)간의 관계를 직선으로 모델링하는 방법
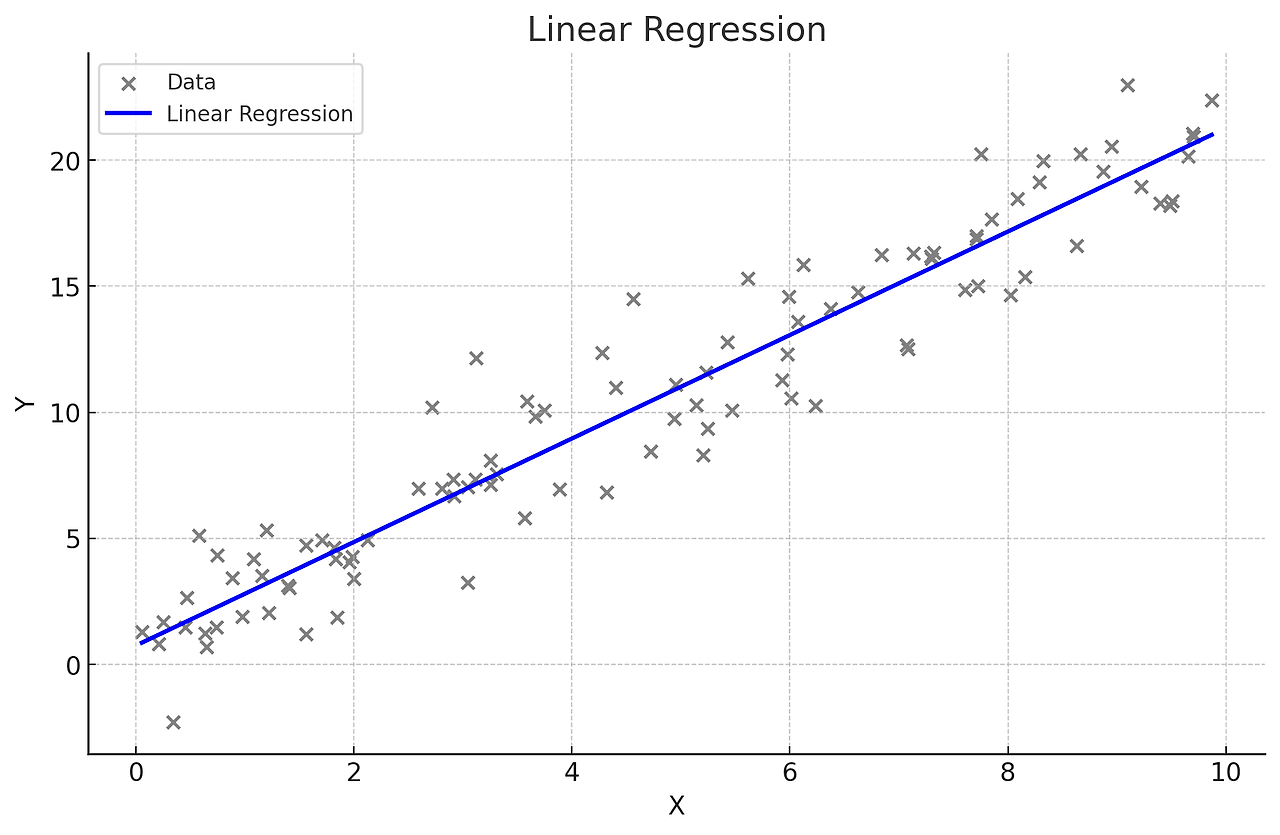
- y = ß0 + ß1X, 여기서 ß0는 절편, ß1는 기울기
- 독립 변수의 변화에 따라 종속 변수가 어떻게 변화하는지 설명하고 예측
- 데이터가 직선적 경향을 따를 때 사용
- 간단하고 해석이 용이함
- 데이터가 선형적이지 않을 경우 적합하지 않음
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 예시 데이터 생성
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 단순선형회귀 모델 생성 및 훈련
model = LinearRegression()
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 회귀 계수 및 절편 출력
print("회귀 계수:", model.coef_)
print("절편:", model.intercept_)
# 모델 평가
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("평균 제곱 오차(MSE):", mse)
print("결정 계수(R2):", r2)
# 시각화
plt.scatter(X, y, color='blue')
plt.plot(X_test, y_pred, color='red', linewidth=2)
plt.title('linear regeression')
plt.xlabel('X : cost')
plt.ylabel('Y : sales')
plt.show()
# 회귀 계수: [[2.9902591]]
# 절편: [4.20634019]
# 평균 제곱 오차(MSE): 0.9177532469714291
# 결정 계수(R2): 0.6521157503858556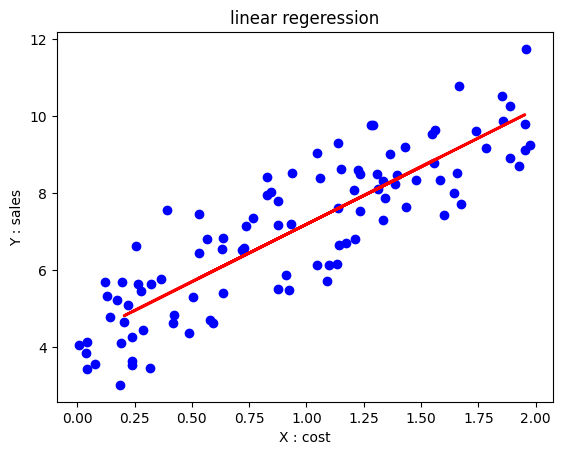
'[데이터분석] 부트캠프 TIL' 카테고리의 다른 글
| 20260216 TIL (0) | 2026.02.17 |
|---|---|
| 20260214 TIL (0) | 2026.02.15 |
| 20260212 TIL (0) | 2026.02.12 |
| 20260211 TIL (0) | 2026.02.11 |
| 20260210 TIL (0) | 2026.02.10 |