[ 전처리 / 시각화 세션 5-1 ]
- 데이터: https://www.kaggle.com/datasets/joniarroba/noshowappointments?resource=download
- 결측치 비율 파악
print("\n--- missing rate(top) ---")
missing = df.isna().mean().sort_values(ascending=False)
print(missing.head(10))
- 컬럼 전처리
# 1) 컬럼명 정리: 소문자/공백 제거/하이픈 -> 언더바
df2.columns = (
df2.columns
.str.strip()
.str.lower()
.str.replace("-", "_", regex=False)
.str.replace(" ", "_", regex=False)
)
df2.columns
# 2) 날짜(datetime) 변환
df2["scheduledday"] = pd.to_datetime(df2["scheduledday"], errors="coerce", utc=True)
df2["appointmentday"] = pd.to_datetime(df2["appointmentday"], errors="coerce", utc=True)
# 3) 타겟 변환: no_show (Yes=1, No=0)
df2["no_show"] = df2["no_show"].map({"Yes": 1, "No": 0})위 코드를 실수로 두번 실행하게되면 이미 1,0으로 바뀐 값들을 다시 map을 실행하는 것이므로 1,0 값이 NaN으로 변함

# 날짜 기준 wait_days (0일 포함) 2016-04-29 18:38:08+00:00 → 2016-04-29 18:38:08
scheduled_date = df2["scheduledday"].dt.tz_convert(None).dt.normalize()
appointment_date = df2["appointmentday"].dt.tz_convert(None).dt.normalize()
df2["wait_days"] = (appointment_date - scheduled_date).dt.days- .dt.tz_convert(None)
- 서로 다른 시간대 기준을 통일하거나, 시간대 정보가 불필요한 연산에서 오버헤드를 줄임
- .dt.normalize()
- 시, 분, 초 데이터를 00:00:00으로 초기화하여 오직 '날짜' 정보만 남김
- 만약 normalize()를 하지 않는다면
- 당일 예약 시 음수값이 발생하는 논리적 오류 발생
- dt.date를 사용해 Object 타입이 되었는데 그 이후 다시 datetime64로 바꾸려면 문자열 파싱이나 객체 순회 과정을 거쳐야 하는데, 이는 대용량 데이터에서 상당한 컴퓨팅 자원을 소모함
- → normalize()로 시간을 0으로 밀어버리더라도 datetime64라는 규격(dtype)을 유지하는 것이 CPU 연산과 메모리 참조 효율성 면에서 압도적으로 유리함
| 구분 | dt.normalize() | dt.date |
| 결과 타입 | datetime64[ns] (Pandas 고유 타입) | object (Python date 객체) |
| 시간 정보 | 00:00:00 으로 남겨둠 | 완전히 제거됨 |
| 연산 편의성 | .dt 접근자를 계속 사용 가능함 | .dt 접근자 사용 불가 (추가 변환 필요) |
| 시각화 | 대부분의 라이브러리에서 시계열로 인식 | 일반 객체나 문자열로 인식될 수 있음 |
| 메모리 저장 방식 | Pandas의 datetime64 타입은 내부적으로 64비트 정수 형태로 메모리에 연속적으로 저장 | Python 객체로 변환되면 각 행이 Python의 Object 타입을 참조하게 되어 메모리 오버헤드가 발생하고 연산 속도가 수십 배 느려짐 |
- 호환성 측면에서 Timestamp가 유리한 이유
- 표준화된 규격이기 때문!
- 시각화 측면 (Matplotlib, Seaborn)
- 시계열 축(x축)을 그릴 때 datetime64는 자동으로 '월, 일, 시간' 단위로 축을 최적화하여 보여줌
- but Object(date) 타입은 이를 단순한 문자열(String)로 인식하여 축이 겹치거나 정렬이 꼬이는 문제가 발생함
- 머신러닝 (Scikit-learn)
- 모델은 숫자형 데이터를 학습함
- datetime64는 내부적으로 정수형이기 때문에 wait_days와 같은 수치 데이터로 변환하기 매우 용이하지만,
- Python 객체는 모델이 직접 읽을 수 없음
- A-B
- timedelta 객체를 생성하여 두 시점 사이의 물리적 간격을 계산
- .dt.days
- timedelta에서 '일(day)' 단위의 정수값만 추출하여 수치형 변수로 변환
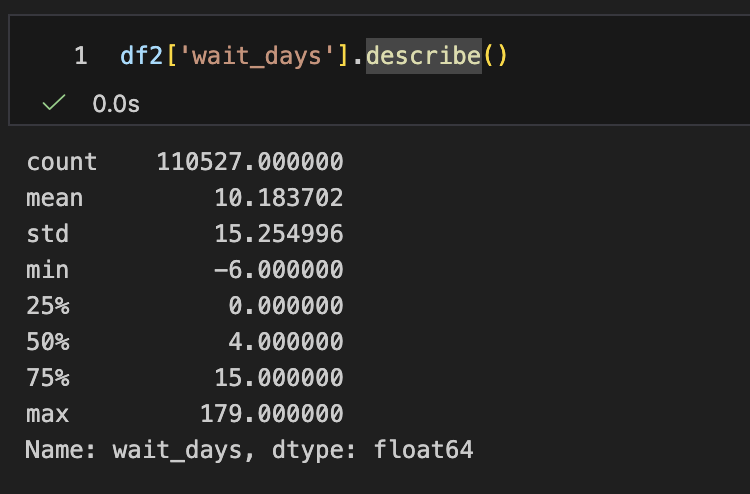
- wait_days 열이 0보다 작은 것은 정상이 아니므로 데이터 확인 후 제거

- 이상치 제거 후 wait_days 열 확인

- 노쇼 비율 막대그래프로 시각화
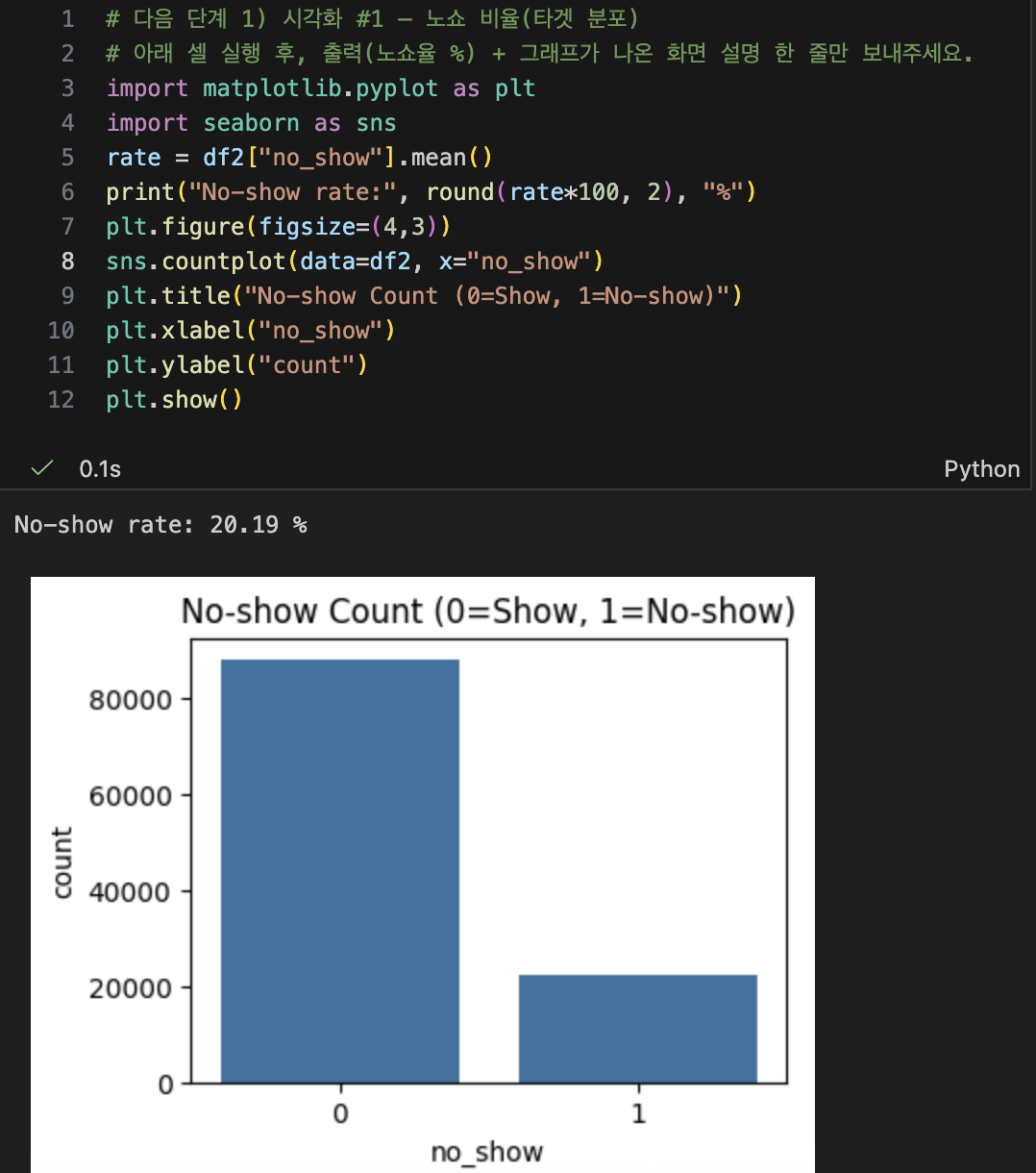
- 두 집단(no_show vs show) 간의 대기 기간 분포 차이

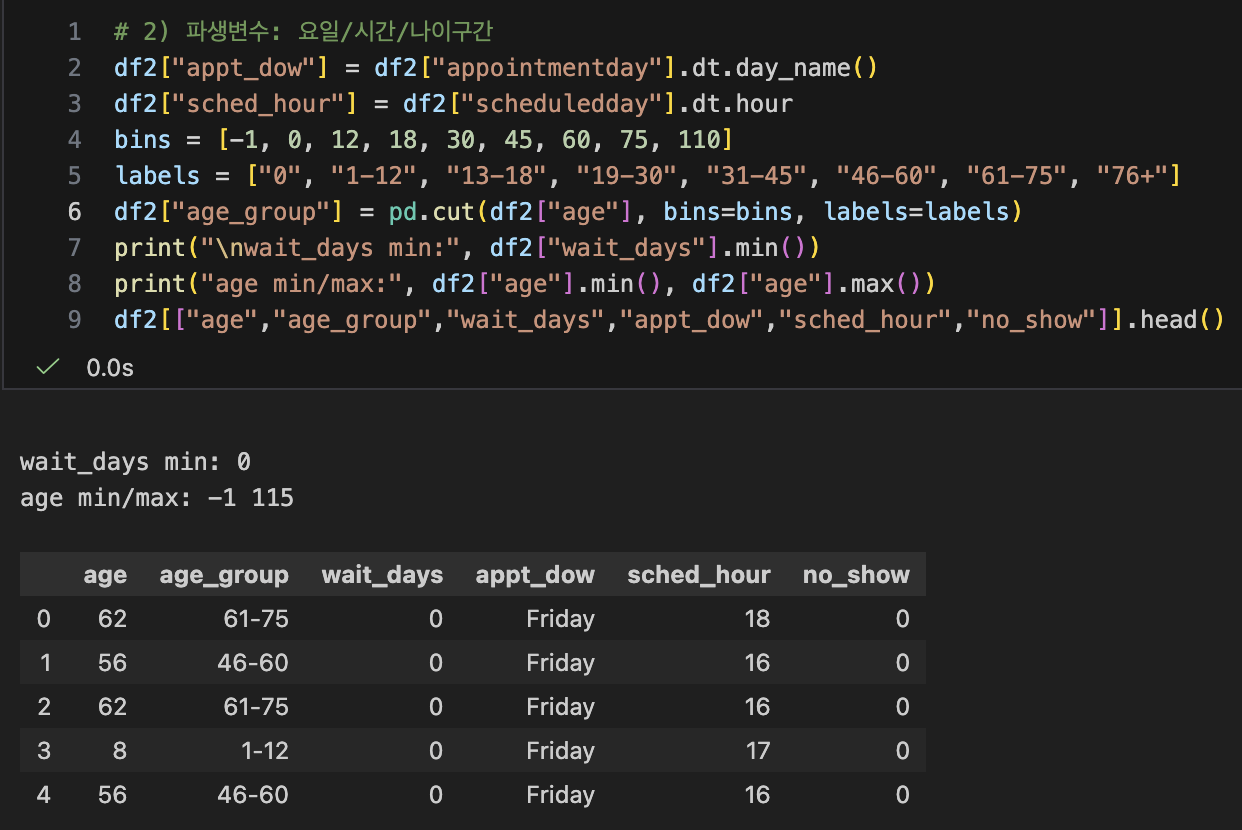
- 나이 구간별로 age 열 나누기
- 요일별 노쇼율
# 다음 단계 3) 시각화 #3 — 요일별 노쇼율 (표 + 막대그래프)
# 아래 셀 실행하고, 출력 표에서 상위 1개 요일 / 하위 1개 요일만 보내주세요.
df2["appt_dow"] = df2["appointmentday"].dt.day_name()
dow_rate = df2.groupby("appt_dow")["no_show"].mean().sort_values(ascending=False)
print(dow_rate.round(4))
plt.figure(figsize=(8,4))
dow_rate.plot(kind="bar")
plt.title("No-show Rate by Appointment Day of Week")
plt.ylabel("No-show rate")
plt.show()
- 오타 있던 컬럼명 수정

- EDA 요약표 생성
- agg(n="size", no_show_rate="mean")
- 그룹화된 데이터에 대해 두 가지 연산을 수행함과 동시에
- 그 결과값들이 담길 열 이름을 지정하는 역할
- min_n=200
- 표본 수가 적을 때 발생하는 '소수의 법칙'에 의한 왜곡을 방지하기 위해
- 표본이 충분할 때 (n>=200) 값을 리턴하도록 조건 추가
# 다음 셀: EDA 요약표 자동 생성
# 나이 구간(없으면 생성)
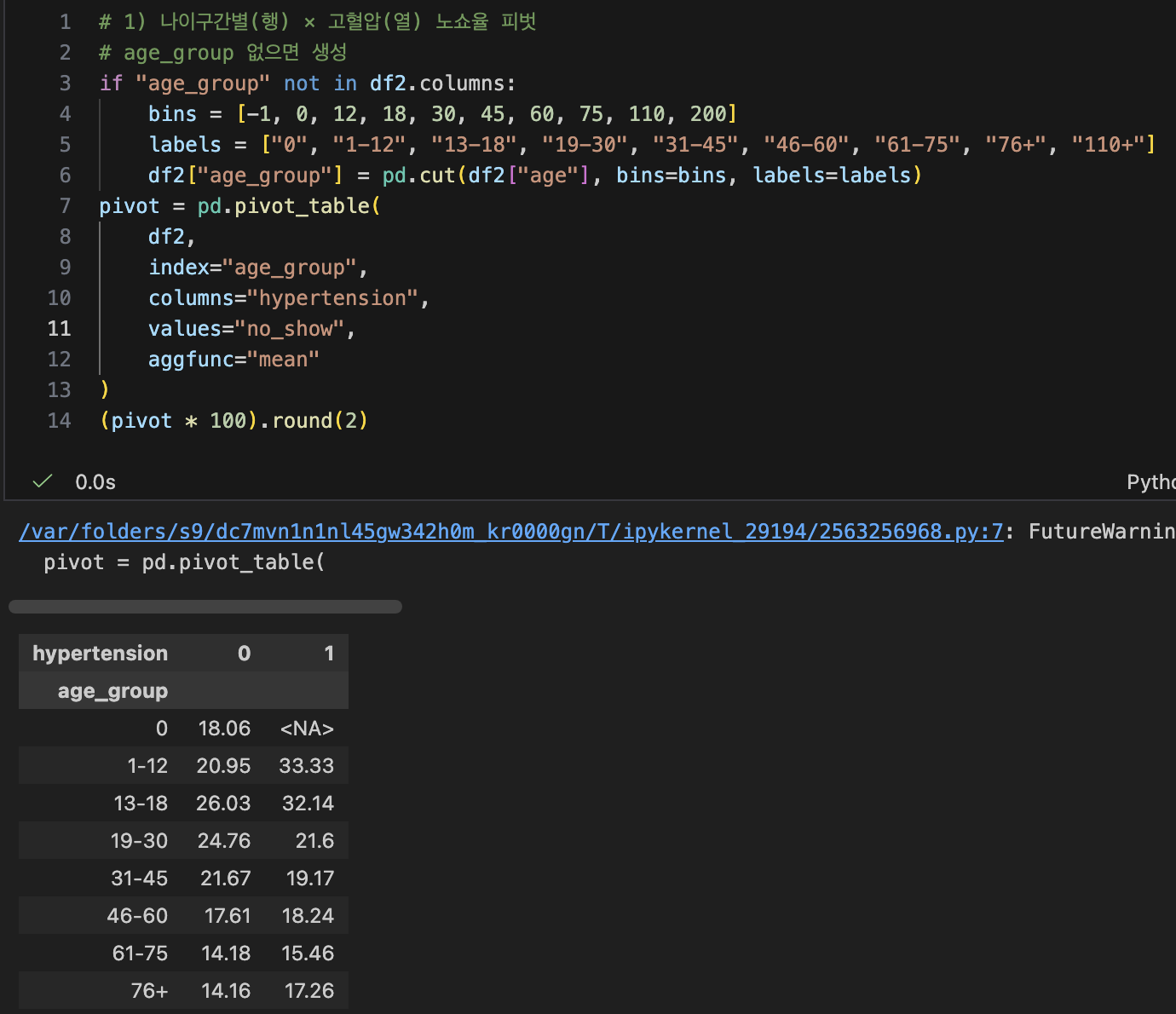
if "age_group" not in df2.columns:
bins = [-1, 0, 12, 18, 30, 45, 60, 75, 110, 200]
labels = ["0", "1-12", "13-18", "19-30", "31-45", "46-60", "61-75", "76+", "110+"]
df2["age_group"] = pd.cut(df2["age"], bins=bins, labels=labels)
def rate_table(col, min_n=200):
tmp = df2.groupby(col)["no_show"].agg(n="size", no_show_rate="mean").reset_index()
tmp["no_show_rate(%)"] = (tmp["no_show_rate"] * 100).round(2)
tmp = tmp.sort_values("no_show_rate(%)", ascending=False)
return tmp[tmp["n"] >= min_n]
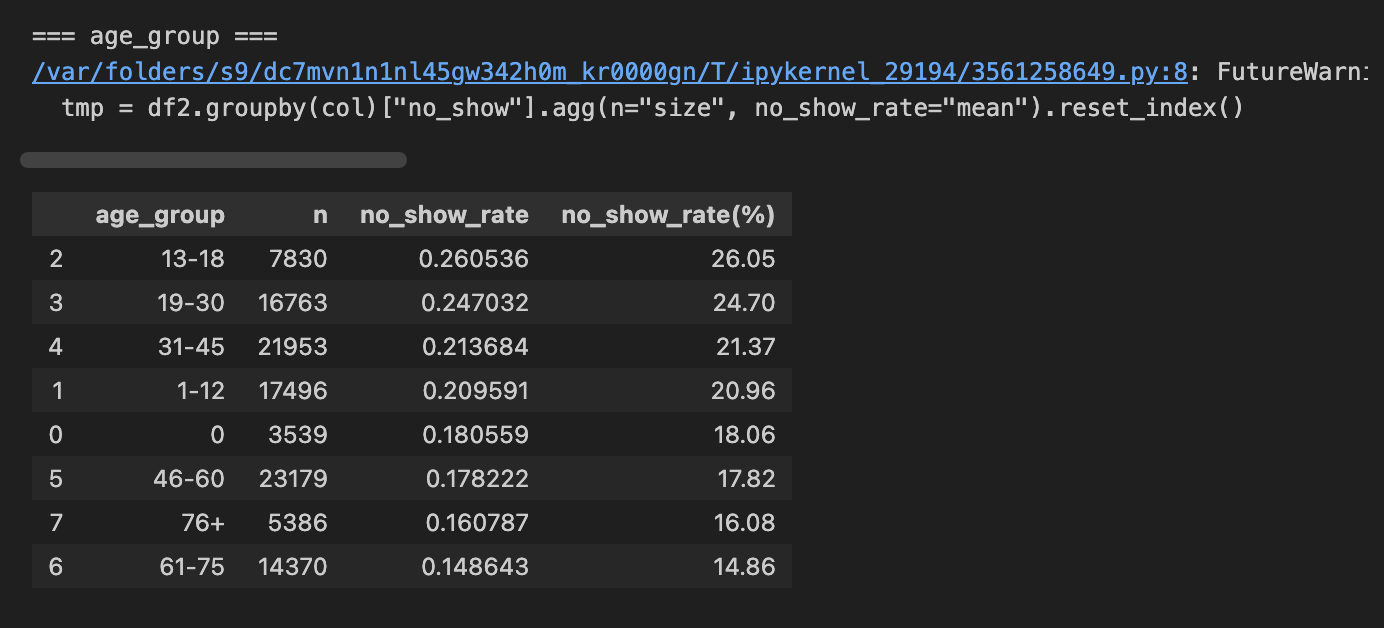
cols = ["gender", "sms_received", "scholarship", "hypertension", "diabetes", "alcoholism", "handcap", "age_group"]
for c in cols:
print(f"\n=== {c} ===")
display(rate_table(c, min_n=200))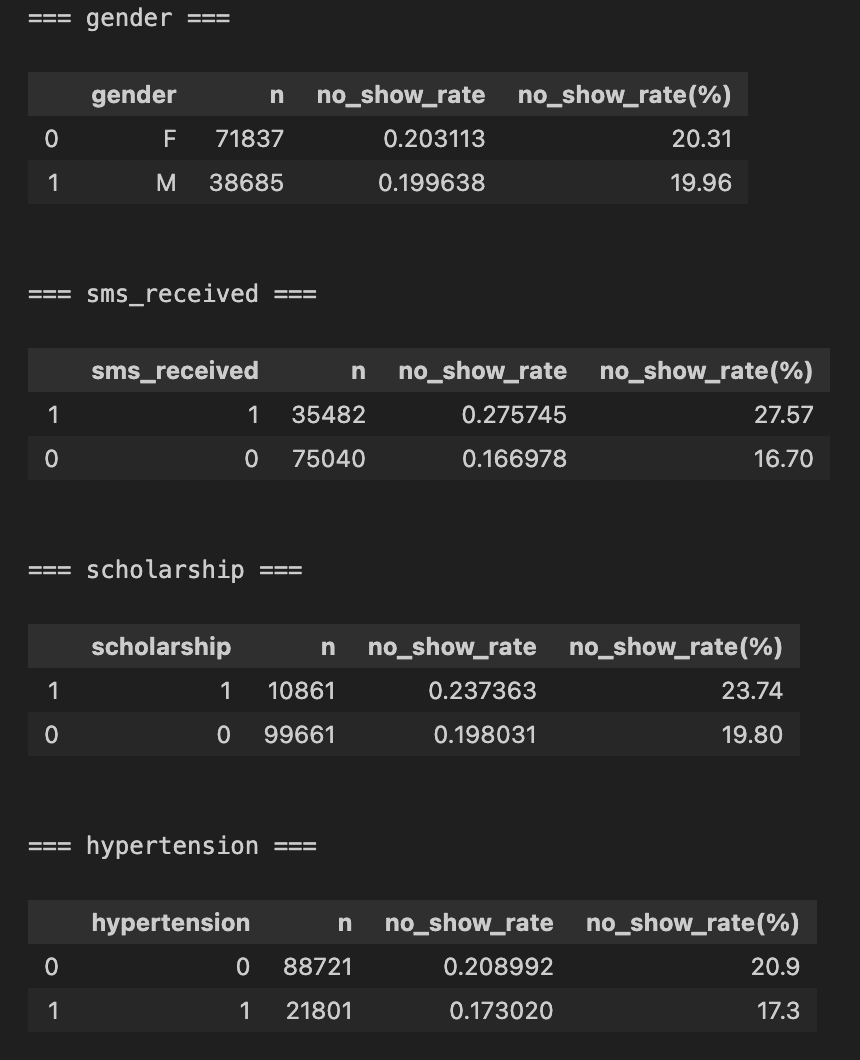

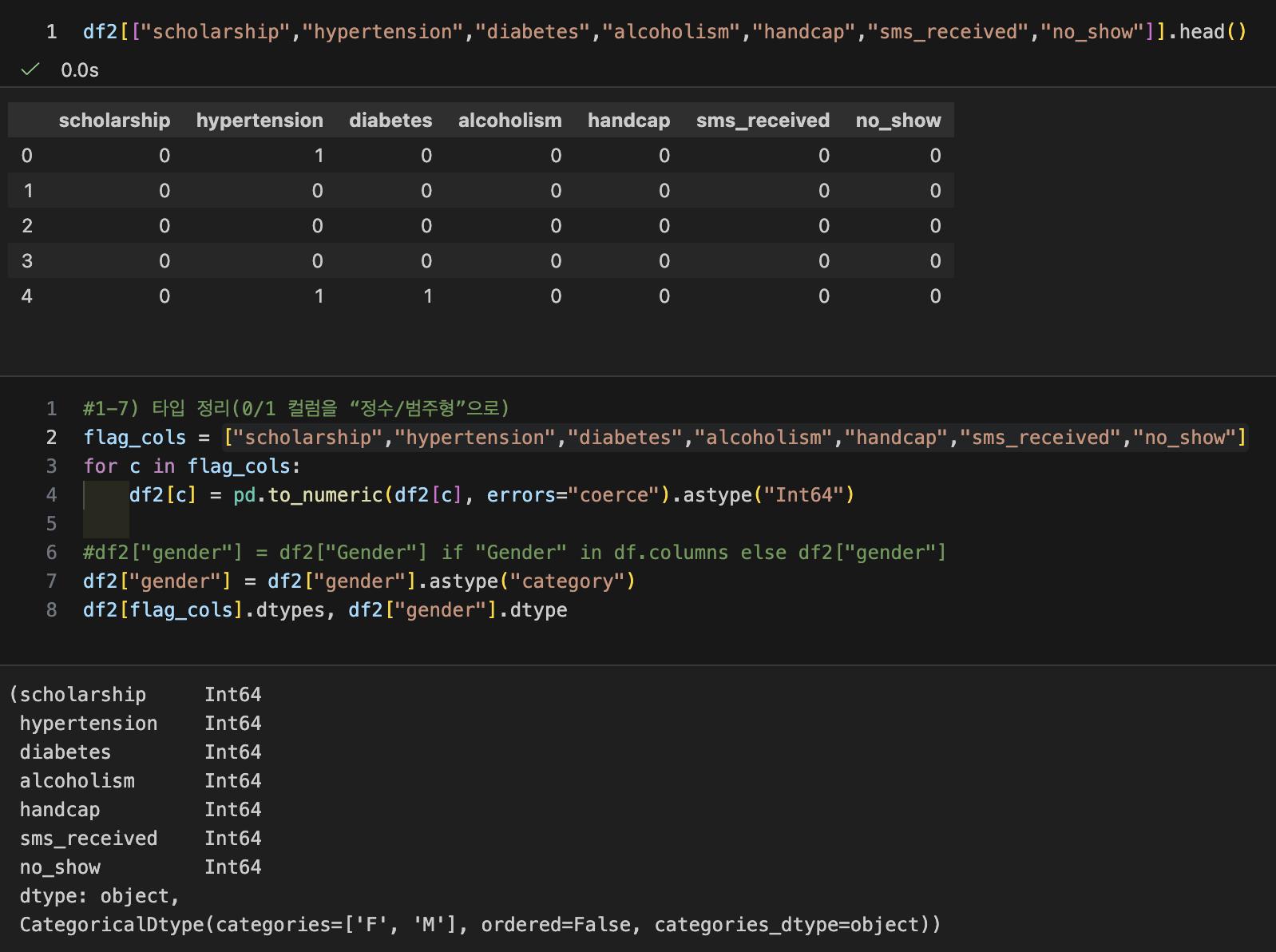
- 타입 정리 (0/1 컬럼을 "정수/범주형"으로)
- 0/1로 되어있던 나머지 컬럼은 모두 정수형으로 타입 변환
- F/M로 되어있던 'gender' 컬럼은 이를 범주형으로 타입 변환 (.astype("category"))

- 나이구간별(행) x 고혈압(열) 노쇼율 피벗
- 상관관계 히트맵 + "중복(높은 상관)" 컬럼 후보 제거
- df2.select_dtypes(include["int64", "float64"])
- 특정 데이터 타입을 가진 열들만 필터링하여 새로운 데이터 프레임을 반환
- 목적
- 상관계수 계산은 '숫자'간의 연산이므로, 문자열(object)이나 범주형(category) 데이터가 섞여있으면 오류가 나거나 계산이 불가능함
- 이를 사전에 방지하기 위해 숫자형만 골라내는 과정임
- 자주 쓰는 옵션
- include="number" 를 쓰면 모든 숫자형(int, float)을 한 번에 가져올 수 있음
- num_df.corr(numeric_only=True)
- 열 간의 피어슨 상관계수를 계산하여 행렬 형태로 반환함
- numeric_only=True
- 데이터프레임 내에 숫자가 아닌 데이터가 섞여있을 경우,
- 이를 자동으로 제외하고 숫자 데이터로만 상관 행렬을 만들겠다는 명시적 설정
- heatmap()
- corr
- 계산된 상관행렬 데이터
- annot=True
- 각 셀 안에 실제 상관계수 수치를 표시할지 여부
- fmt=".2f"
- 수치 표시 형식 (소수점 둘째 자리까지 표시)
- cmap="coolwarm"
- 색상 테마 (양수는 빨간색(warm), 음수는 파란색(cool)으로 표현)
- square=True
- 각 셀의 모양을 정사각형으로 고정하여 가독성 향상
- corr
# A. 상관관계 히트맵 + “중복(높은 상관)” 컬럼 후보 제거
# A-1) 숫자형 컬럼만 뽑고 상관행렬 확인
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
num_df = df2.select_dtypes(include=["int64", "float64"]).copy()
# 타겟 포함한 숫자형 컬럼 목록 확인
print("numeric columns:", num_df.columns.tolist())
corr = num_df.corr(numeric_only=True)
plt.figure(figsize=(10, 7))
sns.heatmap(corr, annot=True, fmt=".2f", cmap="coolwarm", square=True)
plt.title("Correlation Heatmap (Numeric Features)")
plt.show()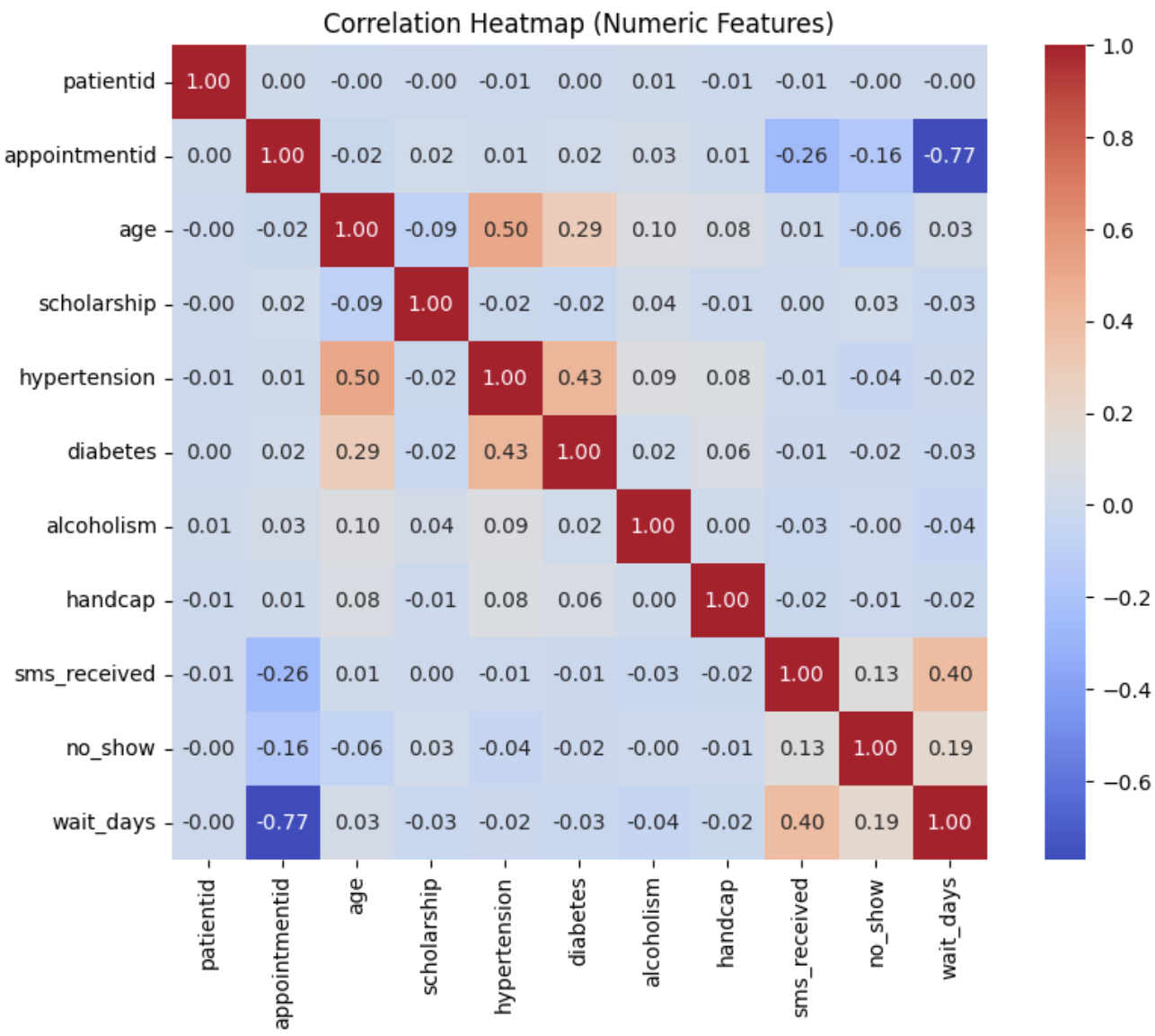
- 기계학습

- Train/Test 분리

- 인코딩 + 정규화 + 로지스틱 회귀 모델 학습 / 평가
# 다음 단계: Step 3 (인코딩 + 정규화 + 로지스틱 회귀 모델 학습/평가)
# 아래 셀을 그대로 실행하고, 출력(특히 confusion_matrix, classification_report)을 캡처해서 올려주세요.
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report
# 숫자/범주 컬럼 분리
num_cols = X_train.select_dtypes(include=["int64","float64","int32","float32"]).columns.tolist()
cat_cols = [c for c in X_train.columns if c not in num_cols]
print("num_cols:", num_cols)
print("cat_cols:", cat_cols)
preprocess = ColumnTransformer(
transformers=[
("num", StandardScaler(), num_cols),
("cat", OneHotEncoder(handle_unknown="ignore"), cat_cols)
]
)
model = Pipeline(steps=[
("prep", preprocess),
("clf", LogisticRegression(max_iter=1000))
])
model.fit(X_train, y_train)
pred = model.predict(X_test)
print("confusion_matrix:\n", confusion_matrix(y_test, pred))
print("\nclassification_report:\n", classification_report(y_test, pred, digits=4))

- 가상 데이터로 예측하기

- streamlit 입력폼 제작

import joblib, json
import pandas as pd
from pandas.api.types import is_numeric_dtype
# 1) 파이프라인 저장 (전처리+모델 통째로)
joblib.dump(model_bal, "./data/no_show_pipeline.joblib")
# 2) Streamlit 입력폼을 쉽게 만들기 위한 메타 저장
feature_columns = X_train.columns.tolist()
schema = {}
defaults = {}
for col in feature_columns:
s = X_train[col]
if is_numeric_dtype(s):
schema[col] = {"type": "num"}
defaults[col] = float(s.median()) # 기본값: 중앙값
else:
schema[col] = {
"type": "cat",
# 옵션이 너무 많으면 UI가 무거워져서 최대 200개만 (원하면 늘리세요)
"options": sorted(s.dropna().astype(str).unique().tolist())[:200]
}
mode = s.dropna().astype(str).mode()
defaults[col] = mode.iloc[0] if len(mode) else ""
meta = {
"feature_columns": feature_columns,
"schema": schema,
"defaults": defaults,
"label_map": {0: "Show", 1: "No-show"} # 본인 기준에 맞게 유지
}
with open("./data/no_show_meta.json", "w", encoding="utf-8") as f:
json.dump(meta, f, ensure_ascii=False, indent=2)
print("Saved:", "/data/no_show_pipeline.joblib", "/data/no_show_meta.json")
- streamlit 실행
- vscode에서 app.py가 있는 디렉토리까지 이동한 후 streamlit run app.py 실행


'데이터 전처리 및 시각화' 카테고리의 다른 글
| 시각화 - 각 그래프의 특성 (1) | 2026.01.22 |
|---|---|
| GroupBy 결합, apply/map 사용 (0) | 2026.01.20 |
| 결측, 중복 전처리: Pandas Cleaning 정제 (1) | 2026.01.19 |
| dtype, 결측치, CSV/Excel/JSON 다루기 (0) | 2026.01.19 |