[ 전처리 시각화 세션 3-1 ]
- 1차 정제 (문자열/결측/타입 통일)
- 날짜 → datetime 변환 + 파생피처 만들기

- 메뉴 문자열 정리 (strip + 표기 통일)

- price 정리 ("4,500원" → 4500)

- qty 정리 (결측 처리 + 숫자형)
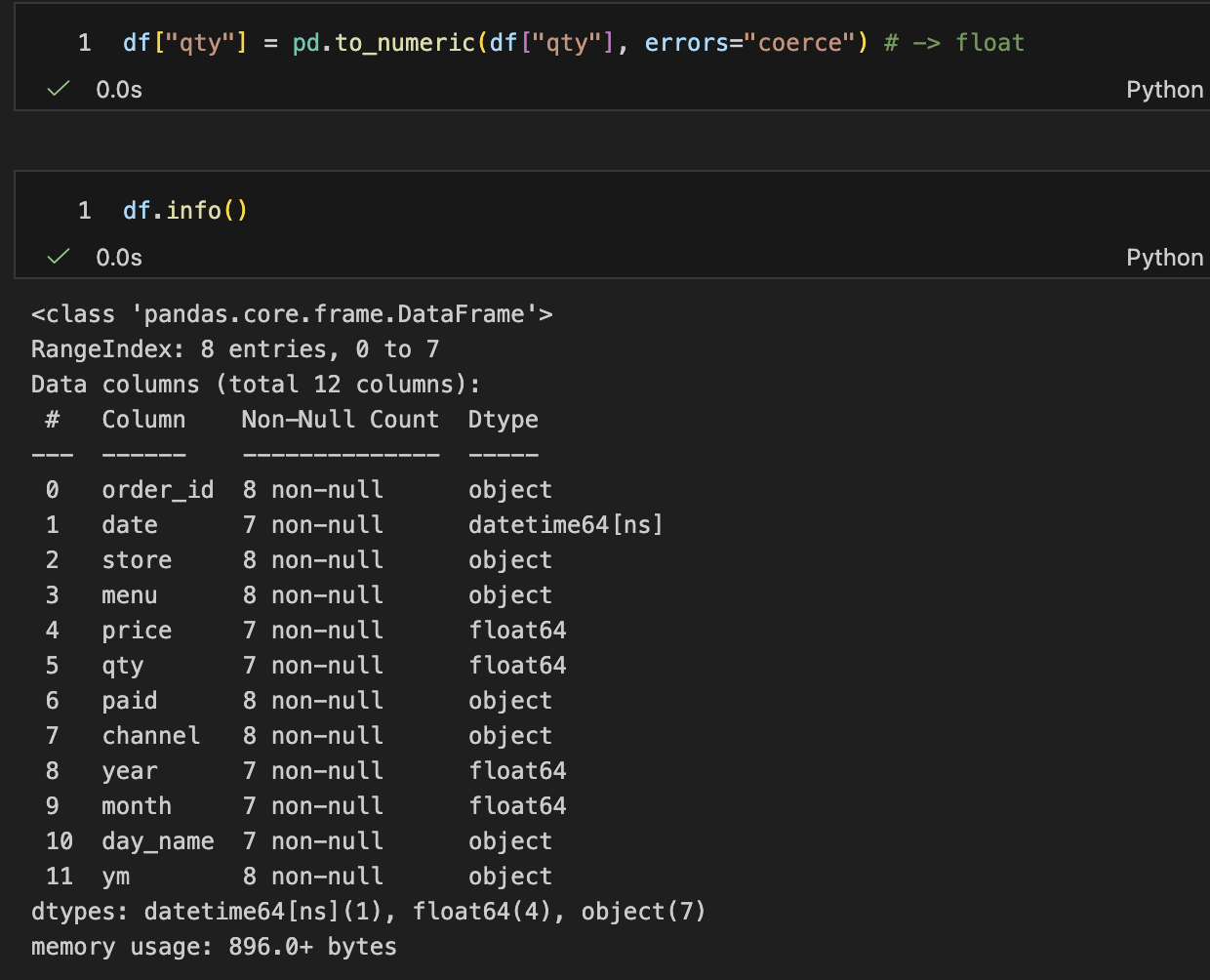

- paid 정리 (TRUE/False/True 혼합 → bool)
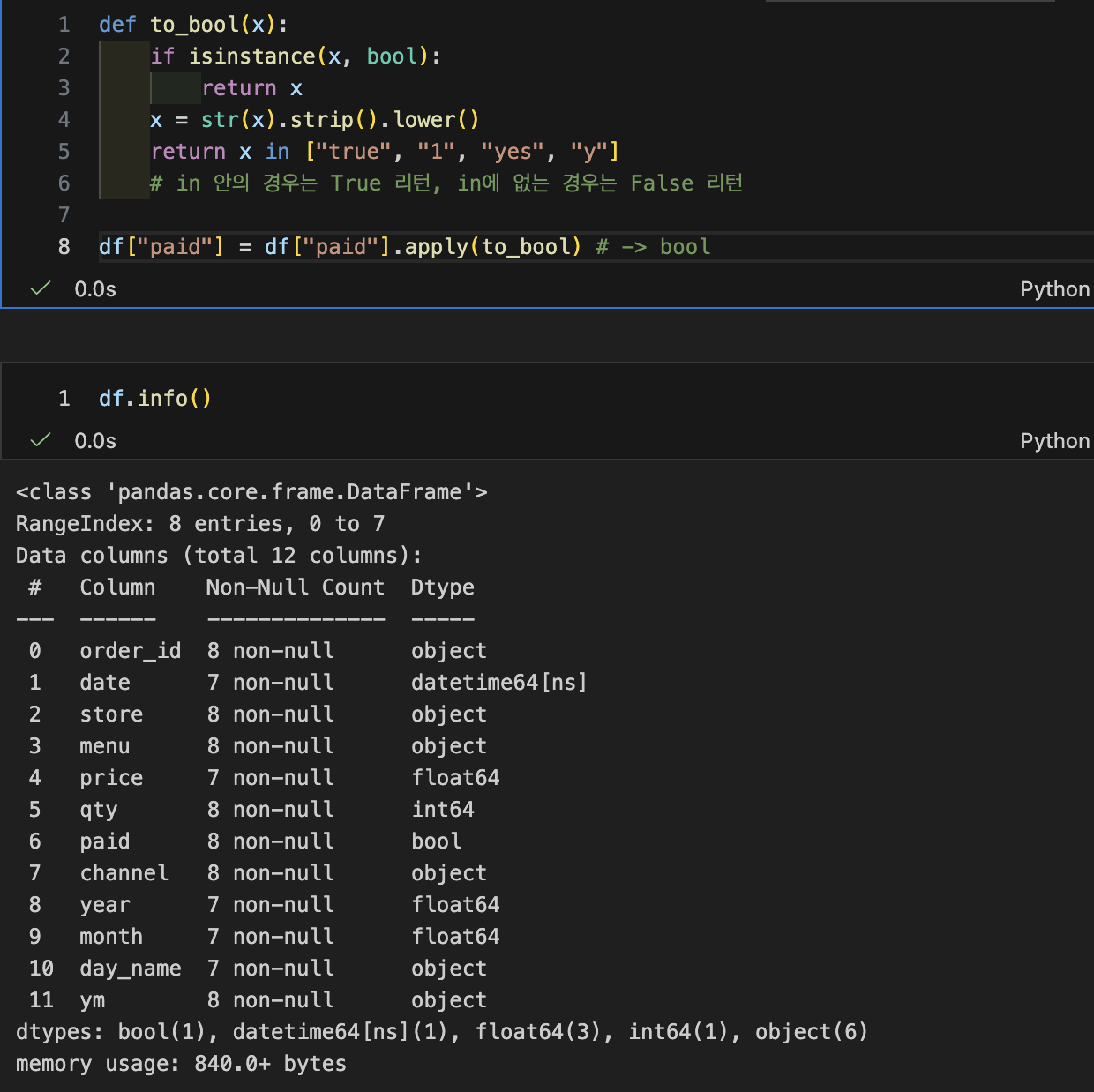
- 매출 컬럼 만들기 (paid가 True일 때만 매출 인정)
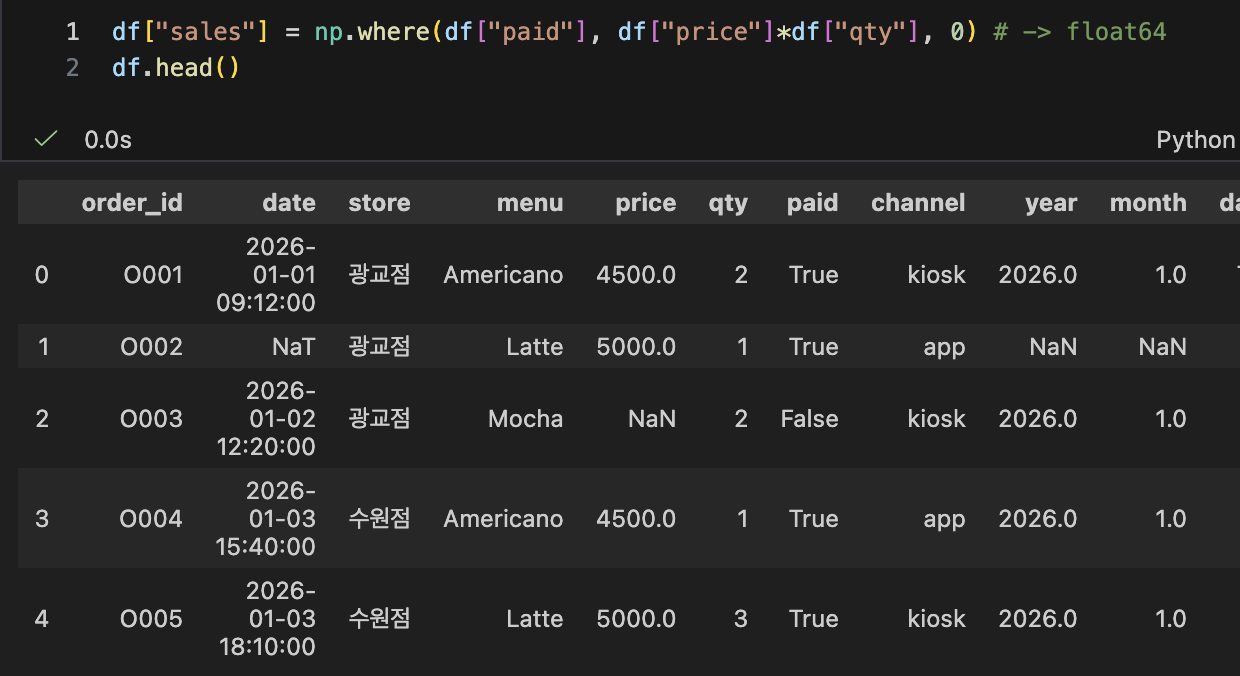
- GroupBy 기초 (단일 기준 집계)
- 매장별 총 매출 / 주문수/ 결제 성공률
- df.groupby("store") : 데이터를 store(매장)별로 묶고
- .agg(...) : 각 매장 그룹에 대해 요약값(집계)을 계산함
- .reset_index() : store가 인덱스로 올라가 있는 걸 다시 일반 컬럼으로 내려서 보기 좋게 만듦
- paid_rate : True=1, False=0처럼 동작해서 mean() 처리하면 '결제 성공 비율'이 됨
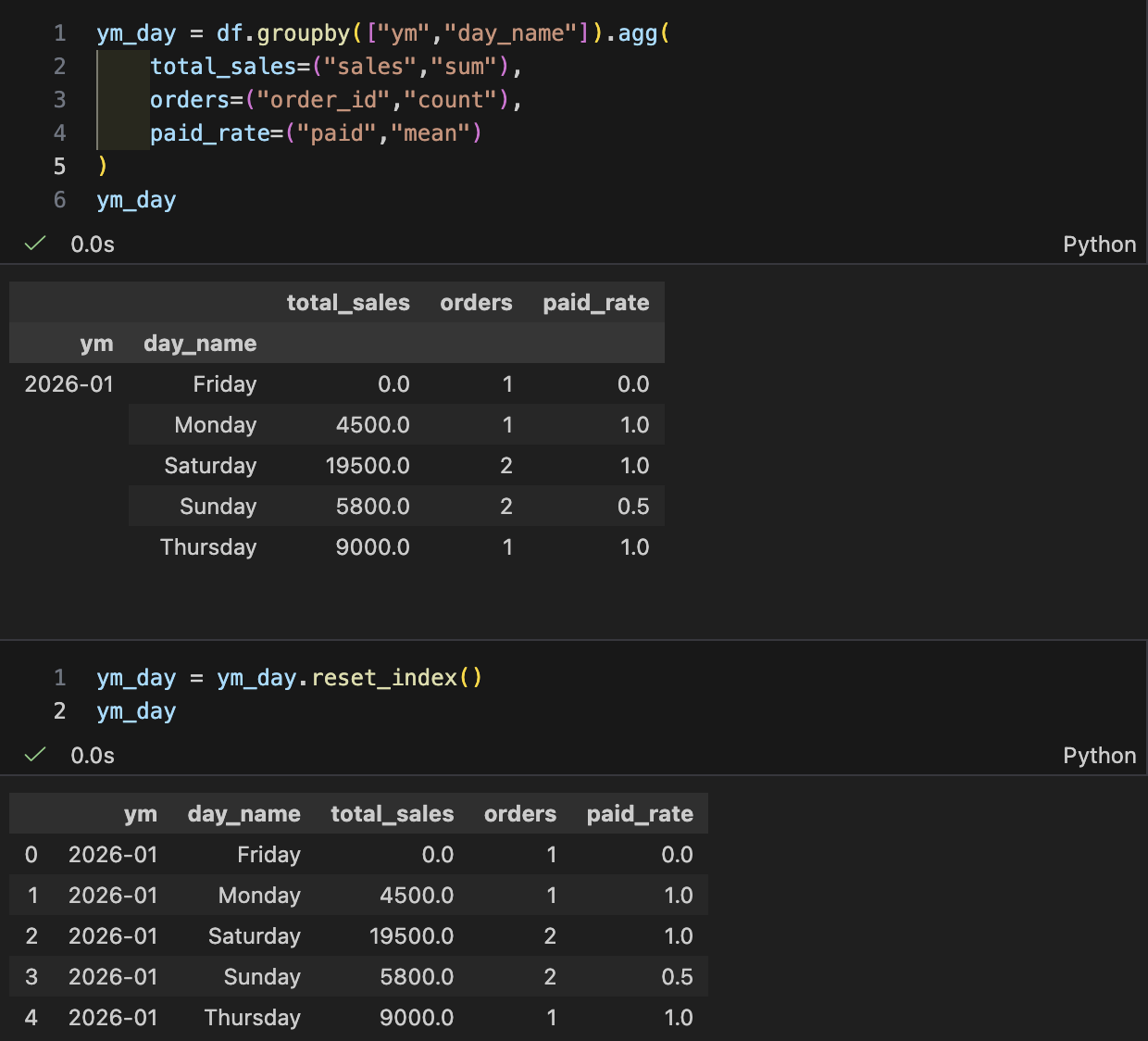
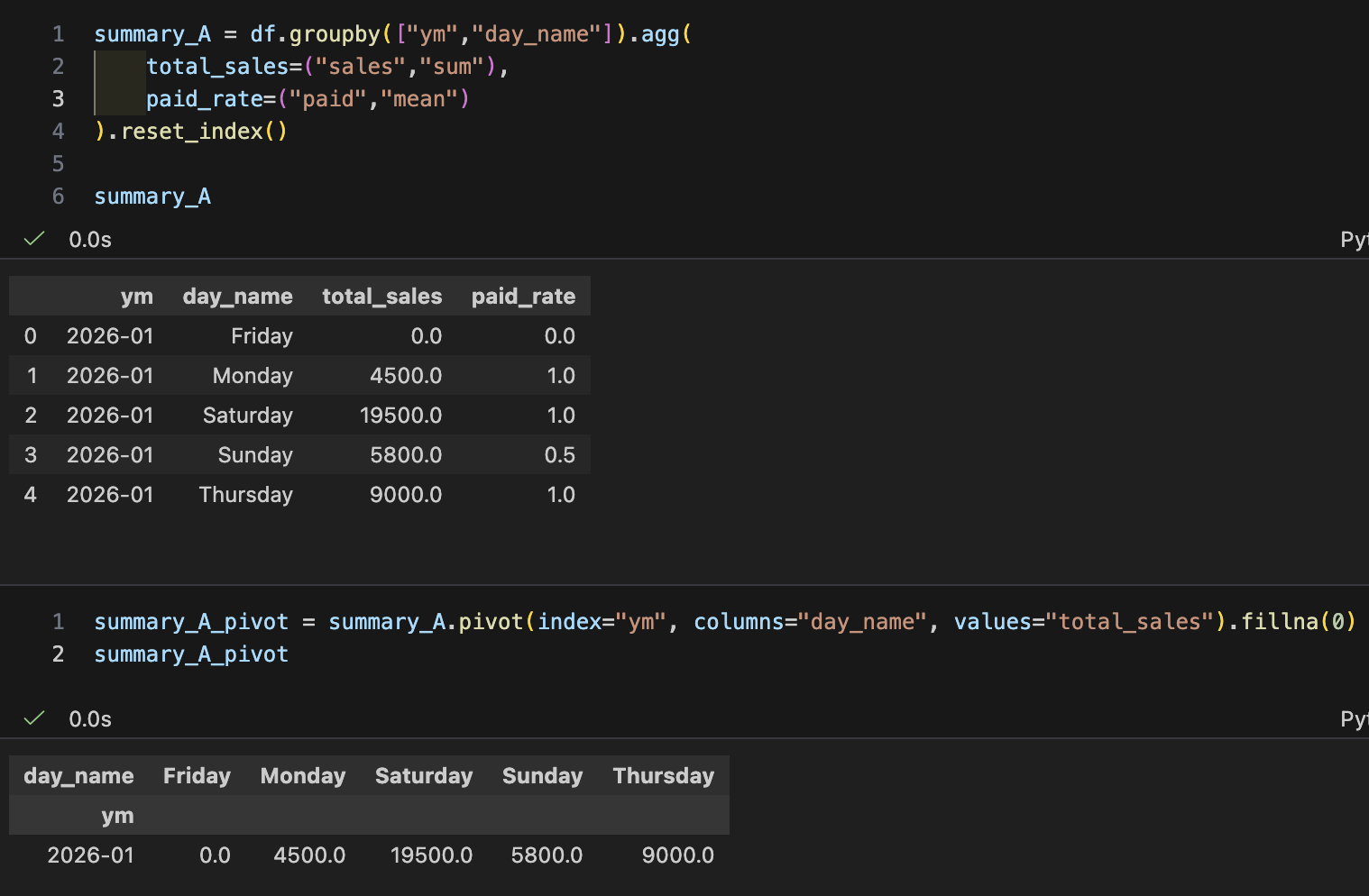
- 피벗 형태로 바꾸기(리포트용): unstack/pivot

- 데이터 결합 (merge / join / concat 차이 체감)
- 카테고리 매핑 테이블 만들기
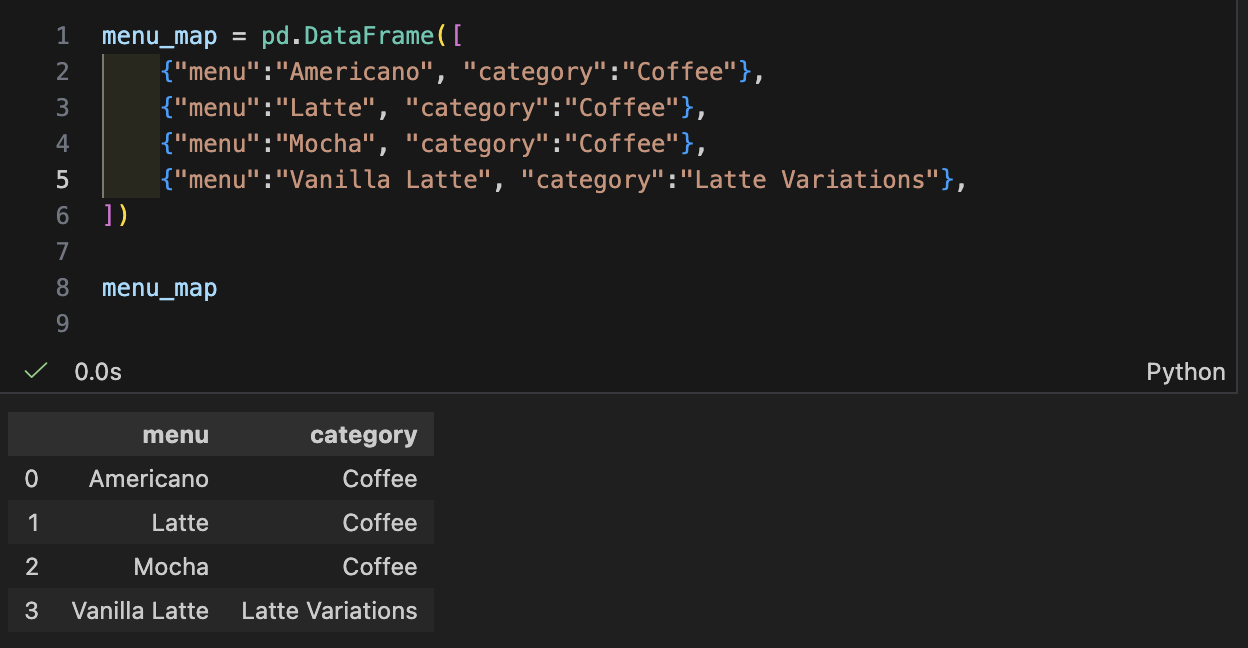
- merge로 결합 (키 기반 결합)
- how="left" : 원본(df)의 행은 유지하면서, 매칭되는 카테고리를 붙임
- 만약 메뉴가 매핑표에 없으면 category가 NaN으로 남음(현업에서 "매핑 누락" 탐지 포인트)

- apply / map (언제 쓰는가)
- map(딕셔너리 매핑): 채널 한글화 같은 "치환 작업"
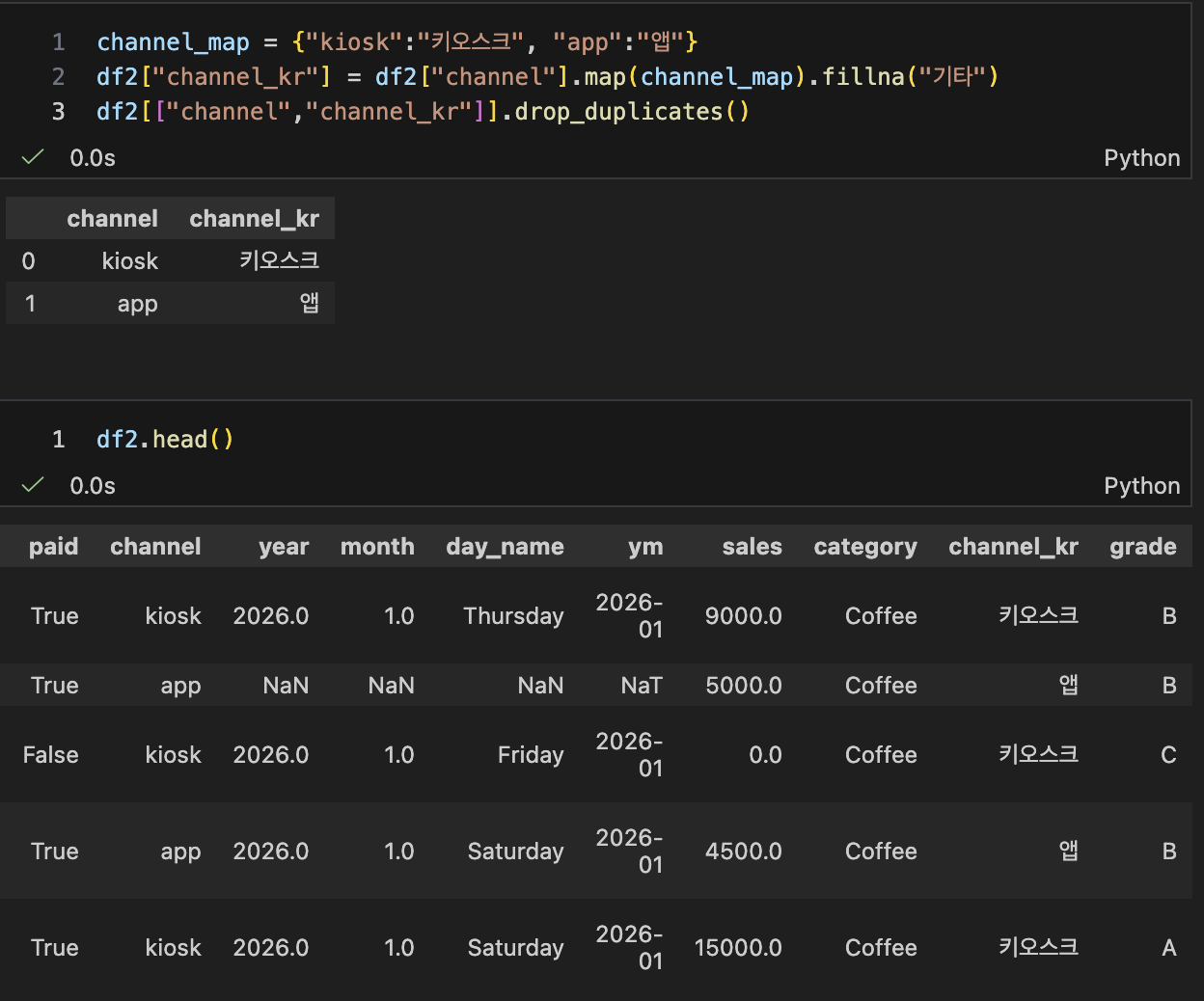
- apply : 행 단위 규칙이 필요할 때 (벡터화보다 느릴 수 있음)

- 종합 실습 (오늘의 목표: 요약 테이블 2개 만들기)
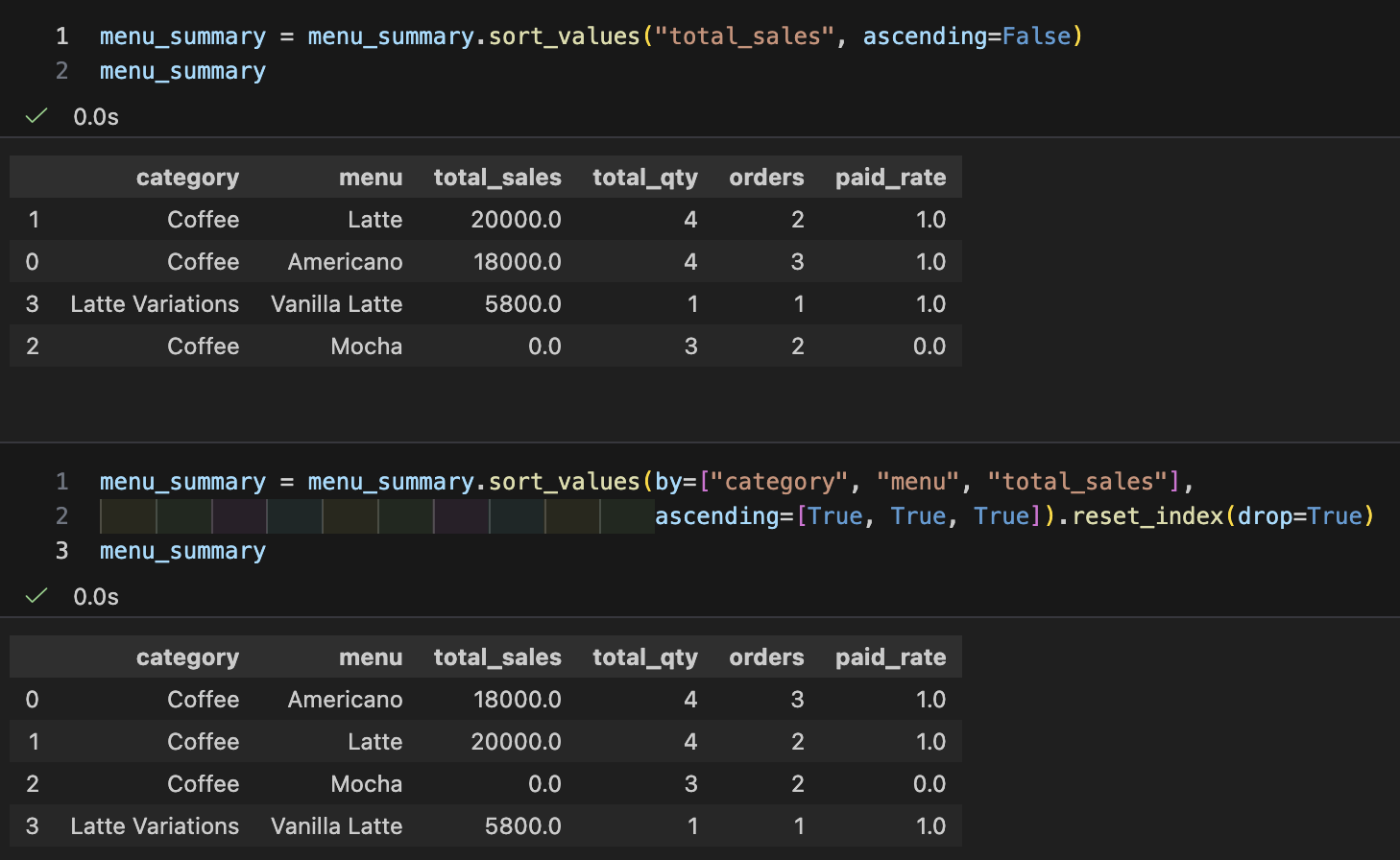
- 요약 테이블 A: "월별 요일 매출 피벗 + 결제율"
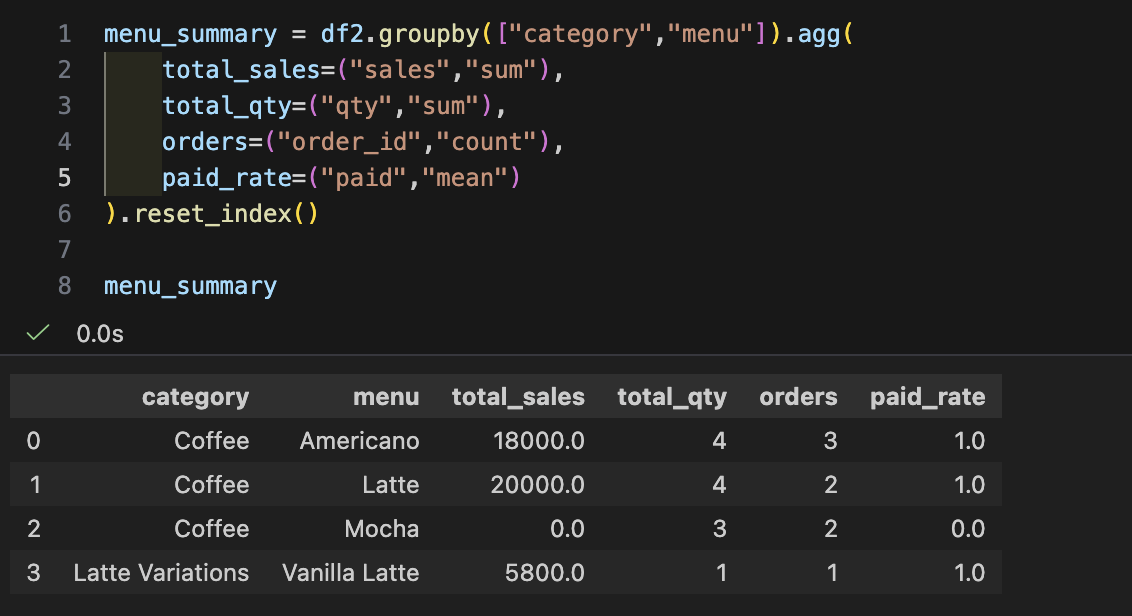
- 요약 테이블 B : "메뉴별(카테고리 포함) 매출/수량 TOP"
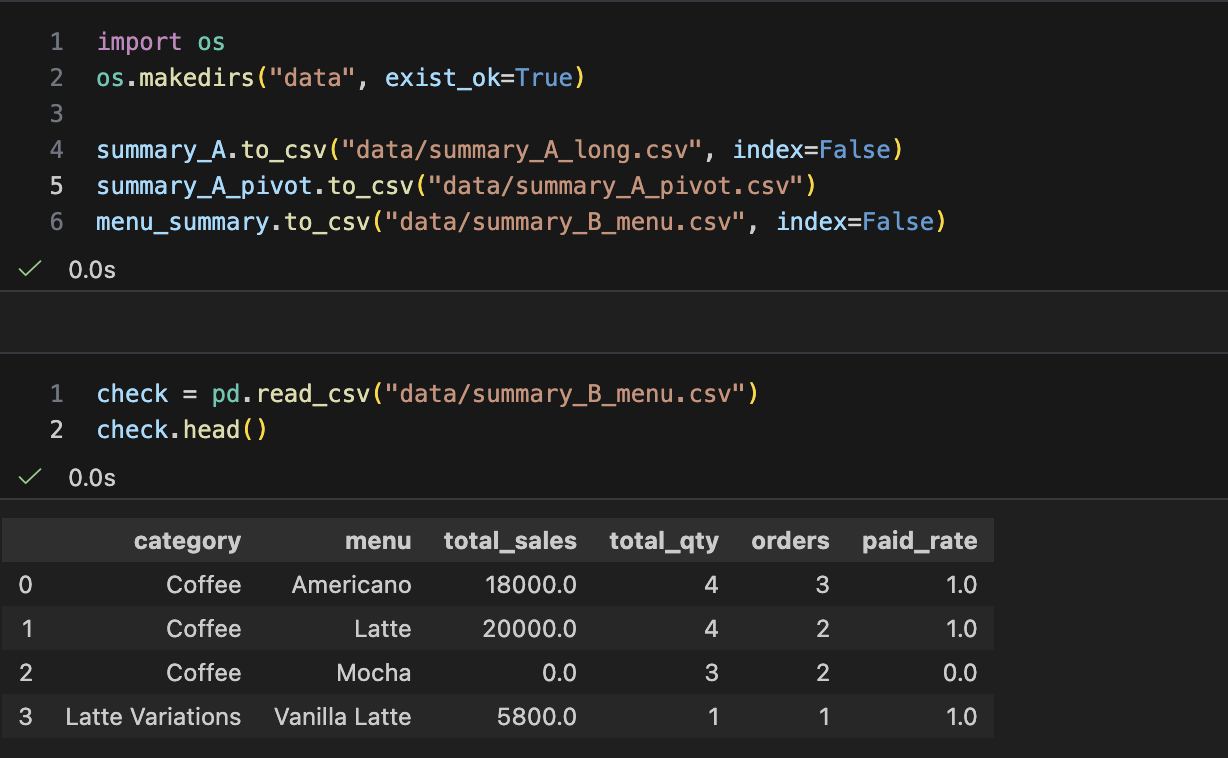
- 저장 & 재현성(검증 로드까지)
- 저장
- 다시 로드해서 확인 ("내가 저장한게 맞는지")
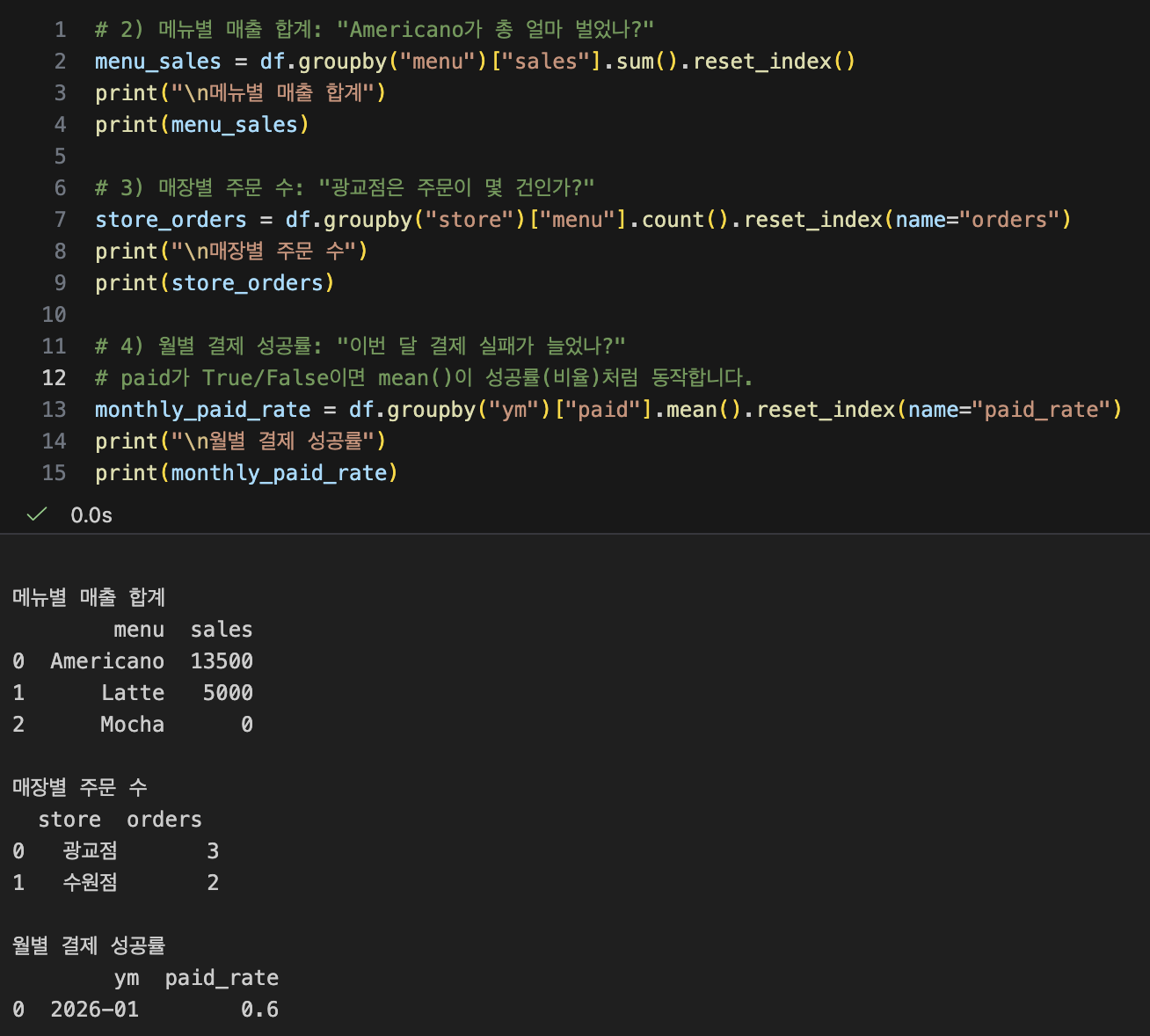
- GroupBy(그룹화) 이론
- 메뉴별 매출 합계 / 매장별 주문 수 / 월별 결제 성공률
- 집계 함수(aggregation) 핵심 5종
- sum
- mean
- count
- nunique: 고유값 개수 ex) 고유 고객 수, 고유 메뉴 수
- min / max
- paid가 True/False일 때, mean(paid)는 성공률처럼 해석될 수 있음
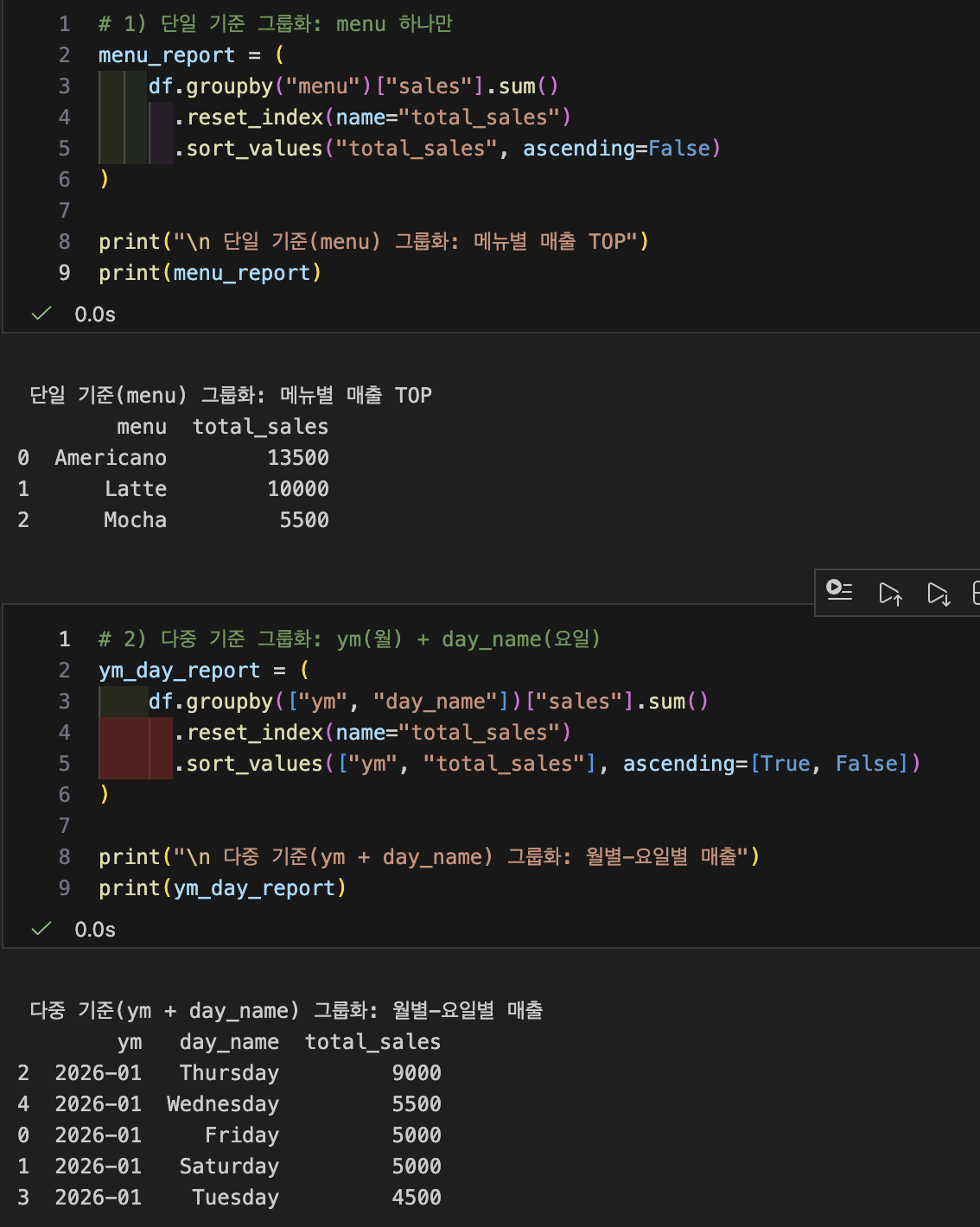
- 단일 기준 vs 다중 기준 (리포트가 달라짐)
- 단일 기준 그룹화
- 기준: menu 하나만
- 결과: "메뉴별 매출 TOP"처럼 단순하고 직관적인 표
- 다중 기준 그룹화
- 기준: ym(월) + day_name(요일)처럼 2개 이상
- 결과: "월별-요일별 매출 패턴" 같은 리포트형 분석이 가능
- ex) 1월은 월요일이 강하고, 금요일은 약하다와 같은 패턴
- 단일 기준 그룹화
- 피벗(표 형태 변환) 이론: "리포트용 표 만들기"
- pivot
- 행/열/값을 지정해서 피벗 표를 만듦
- 가독성 good
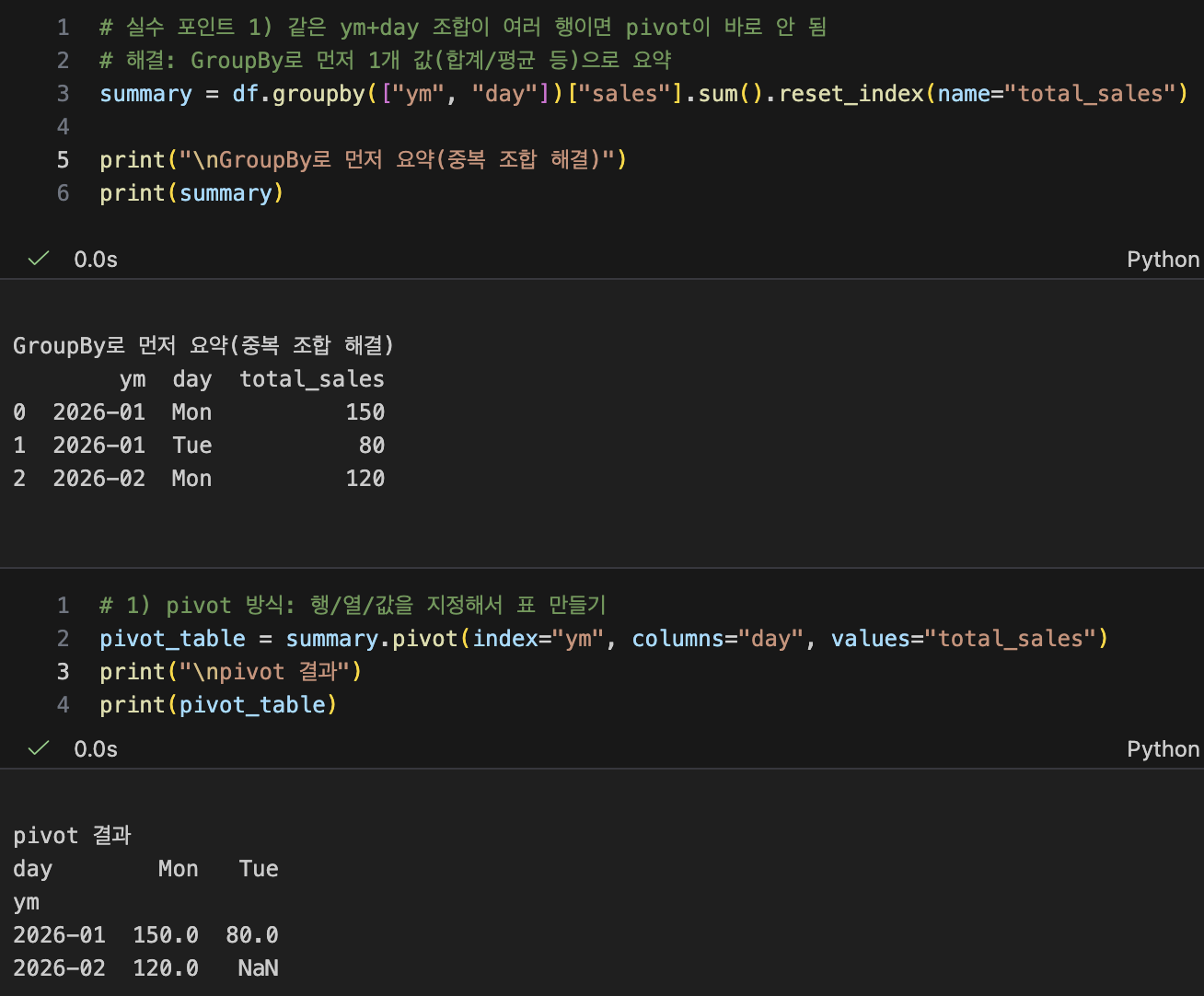
- unstack
- GroupBy 결과가 MultiIndex 일 때
- 한 인덱스 레벨을 열로 펼친다는 느낌
- pivot보다 조금 더 GroupBy 결과를 다루는 방식에 가까움

- 문자열 처리 이론(실무형) 확장
- 왜 문자열 처리가 필수인가?
- 같은 값인데 다르게 저장됨(표기 흔들림)
- 숫자가 문자열로 섞여 들어옴(단위/쉼표/통화 기호)
- 문자열 정리를 안 하면 생기는 문제
- 메뉴별 매출 TOP이 잘못 나옴
- 가격 합계가 안되거나(문자열이라) 일부만 변환돼 왜곡됨
- 포함 여부 필터: contains

- 치환: replace

- 시간 데이터 처리 이론
- 왜 날짜 처리가 중요한가?
- 리포트는 거의 항상 "시간축"이 들어감
- 월별 매출, 주간 매출, 요일별 패턴,시간대별 피크 같은 분석은 전부 '시간'이 기준임
- 정렬이 이상해짐(문자열 정렬 문제)
- 문자열은 "시간 순서"가 아니라 "글자 순서(사전순)"로 정렬될 수 있음
- 특히 dd/mm/yyyy 같은 형식은 시간 순서와 사전순이 잘 맞지 않아 더 문제가 잦음
- 파생 피처를 못 만듦(월/요일/주차 등)
- 월별/요일별 분석을 하려면 month, day_name 같은 파생 컬럼이 필요함
- 날짜가 문자열이면 .dt(datetime 전용 기능)를 쓸 수 없어서 파생 피처 생성이 막힘
- 기간 필터링이 어려움
- "2026-01만 보기", "특정 기간만 자르기" 같은 작업이 날짜 계산 기반이라
- 문자열 상태로는 실수(경계값, 포함/제외)가 늘어남
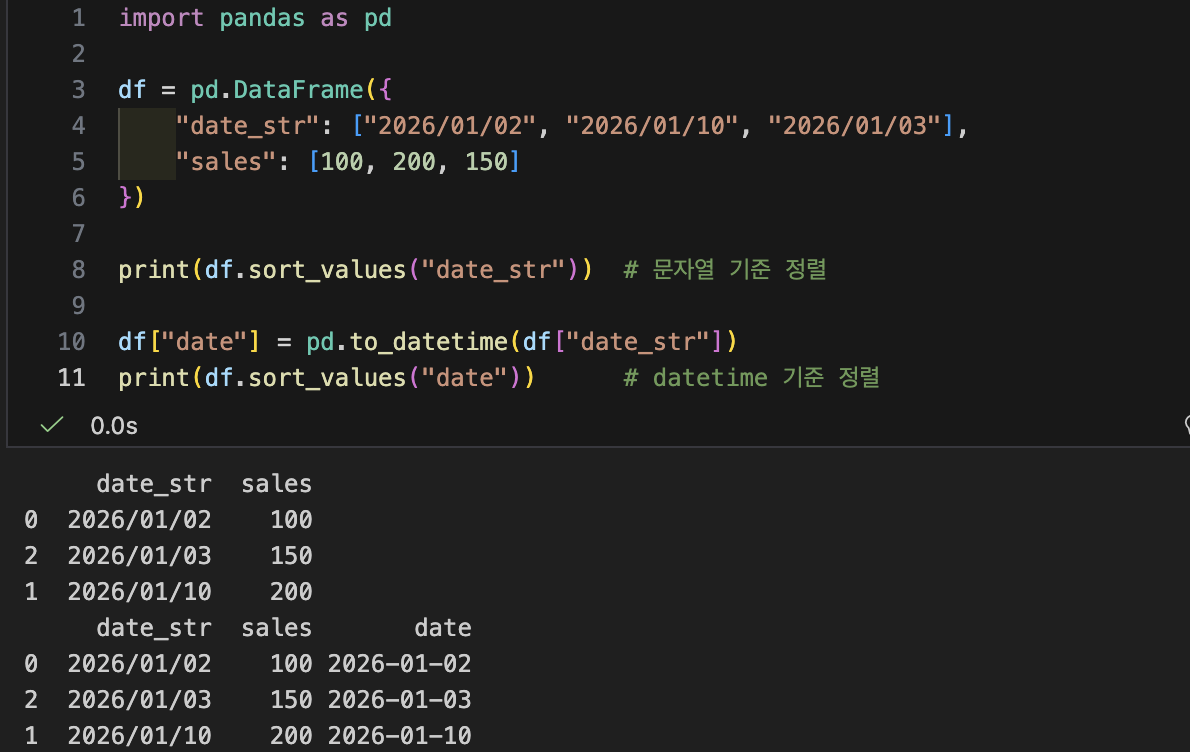
- "datetime으로 바꾸고 파생 피처 만든다

- 데이터 결합(merge/join/concat)
- merge = "키로 붙이는 조인"
- how 옵션
- left
- inner
- outer
- 매핑표 붙일 때는 보통 left로 붙인 뒤,
- category가 NaN인 행을 찾아서 "매핑 누락"을 수정함
- indicator=True는 병합 결과에 행 출처를 표시해주는 홉션
- how 옵션


- concat
- 위아래로 쌓아서(누적) 데이터 양을 늘릴 때 씀

- apply vs map
- map: 값 치환/매핑에 특화(간단 + 빠름)
- 실수 포인트
- 매핑표에 없는 값은 결과가 NaN이 됨
- 누락이 있을 수 있으니 확인하는 습관 필요
- 실수 포인트
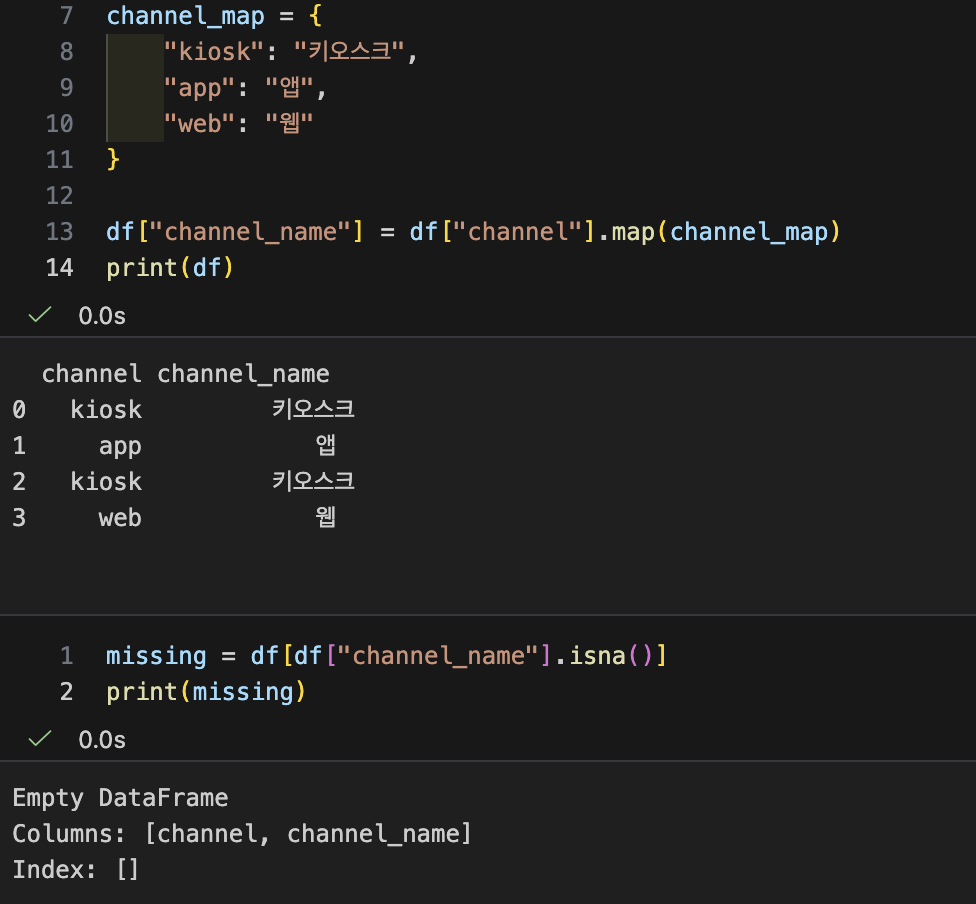
- apply: 행 단위 규칙이 필요할 때
- apply는 편하지만 느릴 수 있음
- apply는 "파이썬 함수로 한 행씩 처리"하는 경우가 ㅁ낳아서 데이터가 커지면 느려질 수 있음

- apply 대신 벡터화로 등급 만들기 (빠르고 깔끔)

'데이터 전처리 및 시각화' 카테고리의 다른 글
| 기계학습, 파이프라인 저장과 streamlit 입력폼 생성 (0) | 2026.01.23 |
|---|---|
| 시각화 - 각 그래프의 특성 (1) | 2026.01.22 |
| 결측, 중복 전처리: Pandas Cleaning 정제 (1) | 2026.01.19 |
| dtype, 결측치, CSV/Excel/JSON 다루기 (0) | 2026.01.19 |