[ 데이터 전처리 / 시각화 2-1 , 2-2 ]
- 인덱싱 핵심: .loc vs .iloc
- .loc : 라벨(이름) 기반 (행/열 이름으로 접근) ; label(이름표)
- 행/열의 '이름표'를 기준으로 선택
- ex) 인덱스가 0,1,2가 아니라 A001,A002 같은 값이어도 그 '이름'으로 찾는 방식
- .iloc : 위치(순서) 기반 (0번째, 1번째...로 접근) ; integer location(정수 위치)
- 0번째, 1번째 처럼 자리(번호)로 선택
- 액셀에서 '위에서 몇 번째 줄' 같은 느낌
- .loc이 자연스러운 상황
- 조건 필터링과 같이 쓸 때
- '결제 완료(True)인 행만 + 필요한 컬럼만'
- 인덱스/컬럼 이름이 의미가 있을 때
- ex) 날짜가 인덱스인 경우(“2026-01-01” 같은 라벨)
- ex) df.loc["2026-01-01":"2026-01-07"]처럼 라벨 범위로 자를 때
- 조건 필터링과 같이 쓸 때
- .iloc이 자연스러운 상황
- '위에서 몇 줄만 보기'
- ex) 첫 5행, 특정 구간(0~9행)
- 위치 기반으로 정확히 잘라야 할 떄
- ex) df.iloc[0:10] (처음 10개)
- 컬럼 이름이 헷갈릴 때 '몇 번째 열'로 빠르게 확인할 때
- ex) df.ilod[:,0] (첫 번째 열)
- '위에서 몇 줄만 보기'
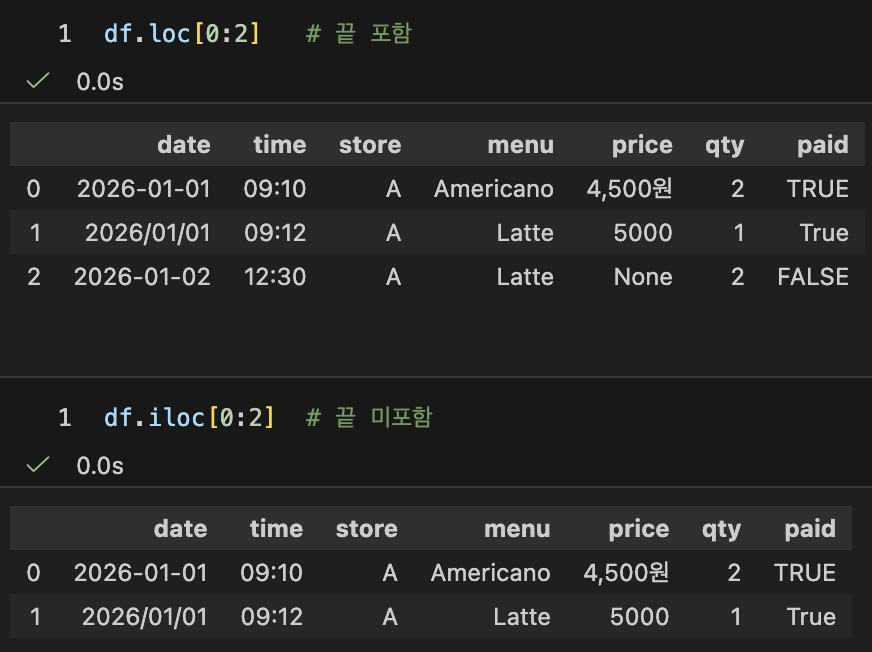
- 슬라이싱 실수 포인트: 끝 포함 여부
- .loc 슬라이싱은 '끝을 포함'하는 경우가 많음
- .iloc 슬라이싱은 파이썬 규칙대로 '끝 미포함'
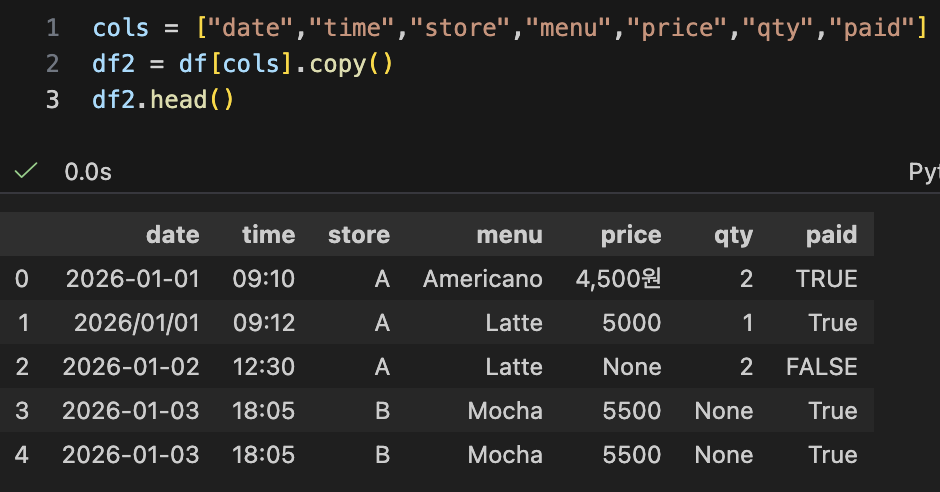
- 열 선택 : 필요한 컬럼만 남기기
- date, time, store, menu, price, qty, paid 등 필요한 컬럼만 남기기
- 조건 필터링 (불리언 인덱싱) : "결제 완료 + A매장 + 오전"
- paid 값을 통일 (소문자/대문자/True 섞임)

- 결제 완료만 추출
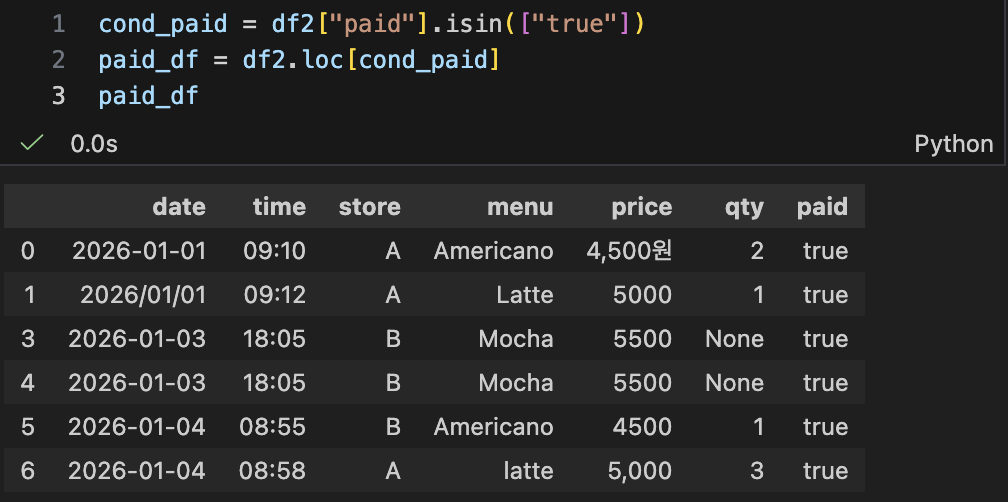
- A매장 + 오전(09시대)만 더 좁히기

- 정렬 : "메뉴별 판매수량 TOP"을 뽑을 준비
- sort_values : 값 기준 정렬
- sort_index : 인덱스 기준 정렬

- 클리닝 기본기 4종 세트
- rename / drop : 컬럼명 정리
- 문자열 정리: menu 공백/대소문자 통일
- 기대 결과
- "Americano " -> "Americano"
- "latte" -> "Latte"
- 기대 결과

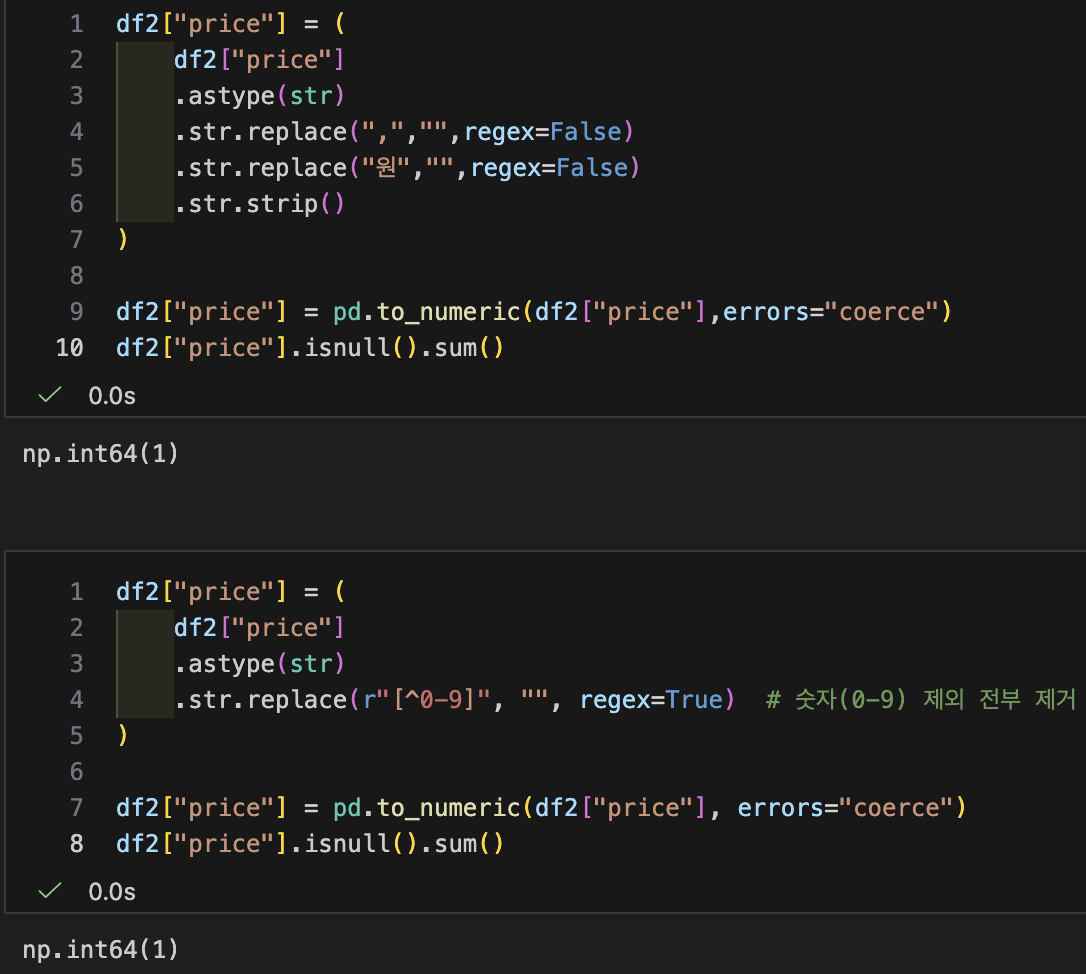
- price 정리: "원","," 제거하고 숫자로 만들기
- 문자열 패턴에 따라 정규식 (Regular Expression)을 사용할 수 있음
- 결측치 처리 : dropna vs fillna
- drop(삭제): 데이터가 적어도 괜찮고, 결측이 중요 변수면 제거
- fill(대체): 평균/중앙값/메뉴별 평균 등으로 대체
- 중복 처리: duplicated / drop_duplicates
- 기대 결과
- 완전히 같은 행이 있으면 제거해서 "실제 판매 기록"에 가까워짐
- 미니 결과물 만들기: "매출 컬럼 추가 + 회의용 테이블 정리"

- 저장: 2회차 결과물을 파일로 남기기 (3회차를 위해 필수)

- 행/열 선택 패턴
- 단일 컬럼 선택 -> Series가 되는 경우가 많음
예를 들어 menu 한 개 열만 보고 싶을 때:
df["menu"] → 보통 Series특징: “한 줄짜리 컬럼”처럼 보이고, name이 menu로 붙습니다.
어떤 상황에서 문제?
Series는 DataFrame처럼 columns가 없습니다.그래서 “다음 단계에서 DataFrame이라고 생각하고” 코드를 쓰면 에러가 나요.
- 자주 하는 실수 1
- series에 .columns를 접근하려고 함 → 오류 발생
- ex) df["menu"].columns (오류)
- 자주 하는 실수 2
- merge를 series에 바로 하려고 함
- merge는 보통 DataFrame 기준으로 쓰는 경우가 많아서, series로 작업하면 흐름이 꼬이거나 바로 사용이 어려움
other = pd.DataFrame({
"menu": ["Latte", "Mocha"],
"category": ["Milk", "Chocolate"]
})
# Series에는 merge 메서드가 없기 때문에 보통 이런 식으로는 안 됩니다(오류/불편).
df["menu"].merge(other, on="menu")
# [출처] 데이터 전처리/시각화 2 결측·중복·문자열 지옥 탈출: Pandas 클리닝 핵심|작성자 아토믹데브- 실무에서 안전한 방식
- merge가 필요하면, 단일 컬럼이라도 DataFrame으로 유지하는게 편함
- 이중 대괄호를 쓰면 단일 컬럼도 DataFrame으로 유지됨
menu_df = df[["menu"]] # <- DataFrame 유지!
menu_df.merge(other, on="menu")
# [출처] 데이터 전처리/시각화 2 결측·중복·문자열 지옥 탈출: Pandas 클리닝 핵심|작성자 아토믹데브- 복수 컬럼 선택 → DataFrame으로 남는 경우가 많음
- 여러 컬럼을 함께 선택하면 DataFrame 형태가 유지됨
menu_info = pd.DataFrame({
"menu": ["Latte", "Americano", "Mocha"],
"category": ["Milk", "Coffee", "Chocolate"]
})
merged_df = df_small.merge(menu_info, on="menu", how="left")
sorted_df, merged_df
# [출처] 데이터 전처리/시각화 2 결측·중복·문자열 지옥 탈출: Pandas 클리닝 핵심|작성자 아토믹데브
- 추천하는 실무 습관 2가지
- '표 형태를 유지하고 싶으면' 항상 이중 대괄호
- ex) df[['menu']]
- 내가 지금 가진게 series인지 dataframe인지 한 번만 확인
- type(변수) 또는 .shape로 감 잡기
- Series: 보통 (행수,)
- DataFrame: 보통 (행수, 열수)
- type(변수) 또는 .shape로 감 잡기
- 조건 필터링 (불리언 인덱싱)
- 핵심 아이디어: True/False 필터를 먼저 만들기
- 조건을 만족하면 True, 아니면 False인 필터(마스크)를 만들기
- 그 필터로 데이터프레임에서 True인 행만 골라내기
- 왜 굳이 True/False 필터를 만들까?
- 조건이 맞는 행이 몇 개가 되는지 바로 확인 가능
- 여러 조건을 조합할 때 디버깅이 쉬움
- 필터를 저장해두면 같은 조건을 재사용하기 좋음
- df.loc[조건, 컬럼]
- 조건: '행을 고르는 기준'
- 컬럼: '보여줄 열만 선택'
- 정렬(sort_values, sort_index)이 필요한 이유
import pandas as pd
# 샘플: 카페 주문 데이터
df = pd.DataFrame({
"menu": ["Latte","Americano","Mocha","Latte","Mocha","Americano","Tea","Tea","Latte"],
"qty": [2, 1, 1, 3, 2, 4, 5, 1, 1],
"price":[5000,4500,5500,5000,5500,4500,4000,4000,5000]
})
# 매출(=수량*가격) 컬럼 추가
df["revenue"] = df["qty"] * df["price"]
# 메뉴별 매출 집계표 만들기
menu_sales = df.groupby("menu", as_index=False)["revenue"].sum()
# 1) 정렬 안 한 집계표: 순서가 애매해서 TOP 메뉴가 바로 안 보일 수 있음
menu_sales_unsorted = menu_sales
# 2) 매출 내림차순 정렬: TOP 메뉴가 즉시 보임 (TOP 5)
menu_sales_sorted = menu_sales.sort_values(by="revenue", ascending=False)
top5 = menu_sales_sorted.head(5)
# 3) 하위 메뉴(개선 대상)도 바로 보임 (BOTTOM 3)
bottom3 = menu_sales_sorted.tail(3)
# 노트북에서 한 번에 보기
menu_sales_unsorted, top5, bottom3
# [출처] 데이터 전처리/시각화 2 결측·중복·문자열 지옥 탈출: Pandas 클리닝 핵심|작성자 아토믹데브- sort_values vs sort_index
- sort_values: '값' 기준 정렬
- 매출, 수량, 평점, 가격 순서로 정렬할 때
- sort_index: '인덱스(행 이름표)' 기준 정렬
- 날짜를 인덱스로 두었을 때 날짜순으로 정렬하고 싶을 때
- sort_values: '값' 기준 정렬
# 2) sort_index 예시: 날짜를 인덱스로 둔 뒤 인덱스(날짜 라벨)로 정렬
daily = pd.DataFrame({
"date": ["2026-01-03", "2026-01-01", "2026-01-02"],
"revenue": [12000, 8000, 15000]
}).set_index("date") # date가 인덱스(행 이름표)가 됨
# 인덱스(날짜) 기준 오름차순 정렬 -> 시간 흐름대로 정리할 때
daily_sorted_by_index = daily.sort_index(ascending=True)
# [출처] 데이터 전처리/시각화 2 결측·중복·문자열 지옥 탈출: Pandas 클리닝 핵심|작성자 아토믹데브
- 클리닝(정제)의 4대 문제
- 컬럼명/구조 문제: rename, drop
- 문자열 문제: 공백, 대소문자, 불필요 문자('원',',')
- 결측치 문제: NaN(비어있음)
- dropna: 신뢰할 수 없는 행은 버린다
- fillna: 합리적으로 값을 채운다
- 평균/중앙값/그룹별 평균 등
- subset: 무엇을 기준으로 비어있는지 판단할지 (없으면 한 열이라도 비어있으면 그 행 삭제)
- 중복 문제: 같은 행이 여러 번 있음
- subset: 무엇을 기준으로 중복인지 판단할지
- keep: 첫번째를 남길지 마지막을 남길지
'데이터 전처리 및 시각화' 카테고리의 다른 글
| 기계학습, 파이프라인 저장과 streamlit 입력폼 생성 (0) | 2026.01.23 |
|---|---|
| 시각화 - 각 그래프의 특성 (1) | 2026.01.22 |
| GroupBy 결합, apply/map 사용 (0) | 2026.01.20 |
| dtype, 결측치, CSV/Excel/JSON 다루기 (0) | 2026.01.19 |