[ 데이터 전처리 / 시각화 4-1 ]
팁:
코드를 암기하는 것보다 그래프 선택 기준 (질문 + 차트) 을 암기한다
1개 그래프를 만들면 반드시 해석 문장 2개를 붙인다
전처리 수업을 막 끝냈다면, 시각화는 전처리 결과가 맞는지 검증하는 용도로 쓴다
- Matplotlib & Seaborn
- Matplotlib
- 모든 그래프의 '기본 엔진'. 세밀한 커스터마이징 가능
- 다만 코드가 조금 길어질 수 있음
- Seaborn
- 예쁘고 빠르게, 통계형 시각화(분포/관계) 친화적
- 기본적으로 보기 좋은 그래프
- 최소 전처리
- 첫 그래프 그려보기
- Matplotlib 예제: 일별 매출 라인 그래프
- df.groupby("date", as_index=False)["sales"].sum()
- 내부적으로 Hash Map을 사용하거나 정렬 후 집계하는 방식을 취함
- as_index=False :인덱스로 유지했을 때와 컬럼으로 뺐을 때의 메모리 구조차이
- df.groupby("date", as_index=False)["sales"].sum()

해석 템플릿
- 관찰: 01-01 대비 01-04 때 매출이 증가했다
- 추정: 수량/결제성공/가격 변화가 원인일 수 있어 추가확인이 필요하다
미션
- 매장별로 일별 매출을 나눠서 2개 라인을 그려보기(멀티 라인)
-> 매장별 일별 매출 비교
- Seaborn 예제: 메뉴별 매출 막대 그래프

해석 템플릿
- 관찰: 아메리카노보다 라떼의 매출이 더 높다. 모카는 매출이 0이다
- 추정: 단가/판매량을 비교해봐야겠다. 모카는 결측치겠구나
- 주요 그래프 유형 맛보기 (핵심은 "언제 쓰는가")
- 선형 그래프: "시간에 따라 변하나?"

해석 템플릿
- 관찰: 01-02일에 매출이 줄어들었다가 다시 증가하는 추세다
- 추정: 01-02일 데이터가 누락이 되었거나 결측이 발생했겠구나 03일엔 매출이 많이 증가했는데 프로모션이 있었던건지 확인이 필요하겠다
미션
- 매장별로 일별 매출을 나눠서 2개 라인을 그려보기(멀티 라인)
-> 매장별 일별 매출 비교


- 관찰: A매장 매출 데이터는 01-01일 기록만 남아있군 나머지는 누락 되었나? B매장 매출 데이터는 01-03일부터 기록되어있네. A매장의 01-01일 매출이 B매장의 01-03일 매출보다 높았지만 B매장의 매출이 04일에 더 높아졌네
- 추정: A매장의 01-02일 데이터는 결측치인가보다. B매장의 매출이 높은 이유는 무엇일까 프로모션이 있었던건지 확인해봐야겠다.
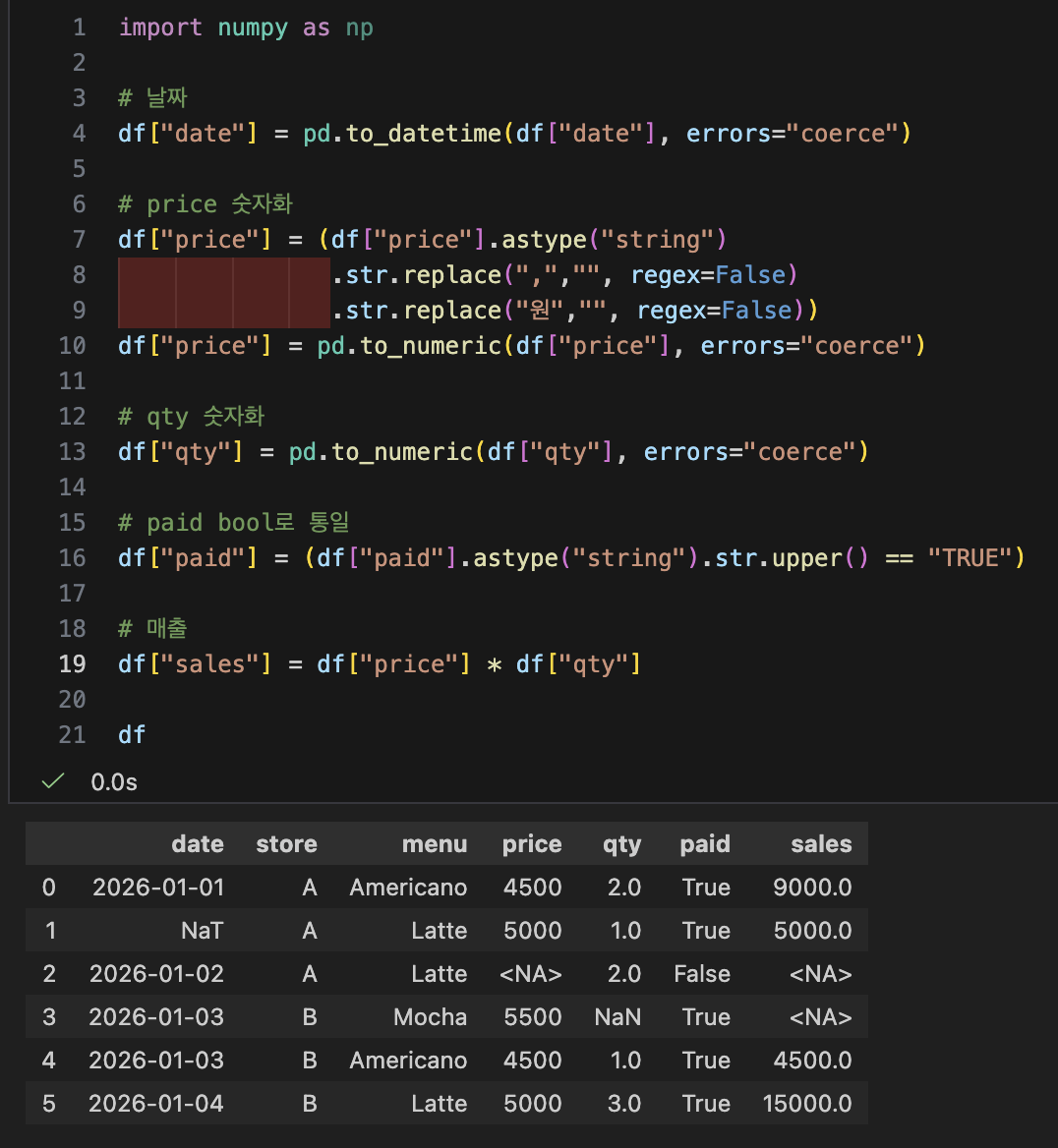
- 막대 그리프: "항목별 비교는?" - 메뉴별 매출 막대그래프

- 관찰: 라떼의 매출이 가장 크고 그 다음은 아메리카노네
- 추정: 라떼의 단가가 높은걸 수도 있겠다 단가와 판매 수량을 확인해봐야겠다
- 막대 그리프: "항목별 비교는?" - 메뉴별 매출량 막대 그래프
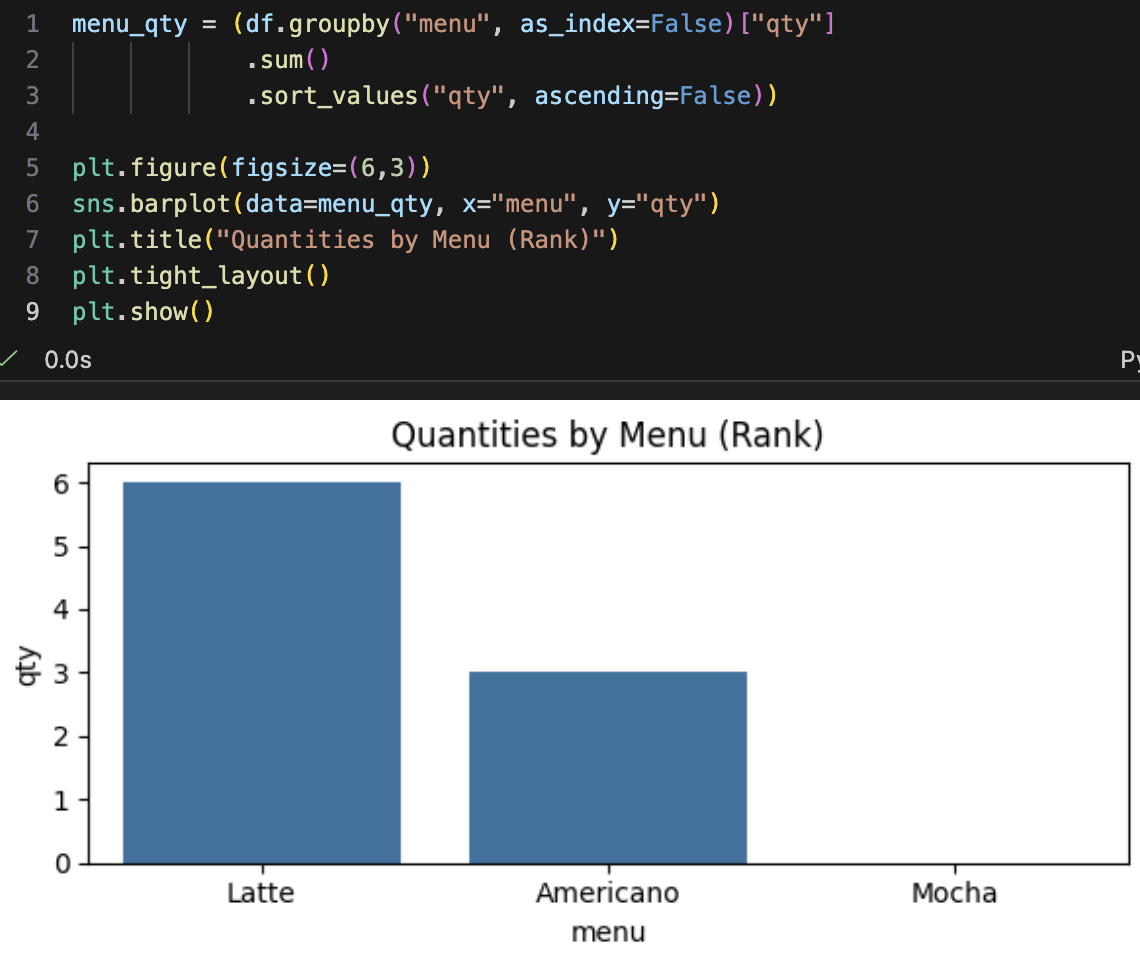
- 산점도(Scatter Plot): "두 변수는 관계가 있나?"
- 포인트: 결측 제거 후 진행
- 관찰: 라떼의 단가가 5000원이고 아메리카노의 단가가 4500원이었네 라떼는 단가가 높지만 판매 수량은 가격과 상관없이 높게 나왔네 아까 위에서 본 메뉴별 매출 그래프에서 라떼가 높게 나온 이유가 여기 있었군
- 추정: 아직 데이터가 얼마 없어서 예외 상황이 나온 걸수도 있으니 데이터가 더 필요하겠다. 더 많은 데이터가 쌓이면 가격과 판매 수량간의 상관관계를 좀 더 정확히 분석할 수 있겠다
- 추가적 인사이트: B매장의 데이터를 더 구했을 때 라떼 매출이 여전히 높게 측정된다면, B매장 경영자에게 라떼 중심의 세트 메뉴를 더 구성하자고 제안할 수 있음(가격을 올리다간 역효과로 매출이 감소할 수도 있어)
- 랜덤으로 아메리카노와 라떼 금액과 수량을 만들어 scatterplot을 통해 메뉴별로 가격과 수량의 관계 확인
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(7)
n = 40 # 점 개수(원하는 만큼 늘려도 됨)
# Americano: 저가 + 수량 많음
a_price = np.random.randint(4200, 4601, size=n)
a_qty = np.random.randint(3, 7, size=n) # 3~6
# Latte: 고가 + 수량 적음
l_price = np.random.randint(4900, 5401, size=n)
l_qty = np.random.randint(1, 4, size=n) # 1~3
df_demo = pd.DataFrame({
"menu": ["Americano"] * n + ["Latte"] * n,
"price": np.concatenate([a_price, l_price]),
"qty": np.concatenate([a_qty, l_qty]),
})
# (선택) 판매금액도 같이 보고 싶으면
df_demo["sales"] = df_demo["price"] * df_demo["qty"]
# 산점도
plt.figure(figsize=(6,4))
sns.scatterplot(data=df_demo, x="price", y="qty", hue="menu", s=70, alpha=0.9)
plt.title("Price vs Qty (Demo: Americano sells more, Latte sells less)")
plt.xlabel("price")
plt.ylabel("qty")
plt.tight_layout()
plt.show()
df_demo.head()
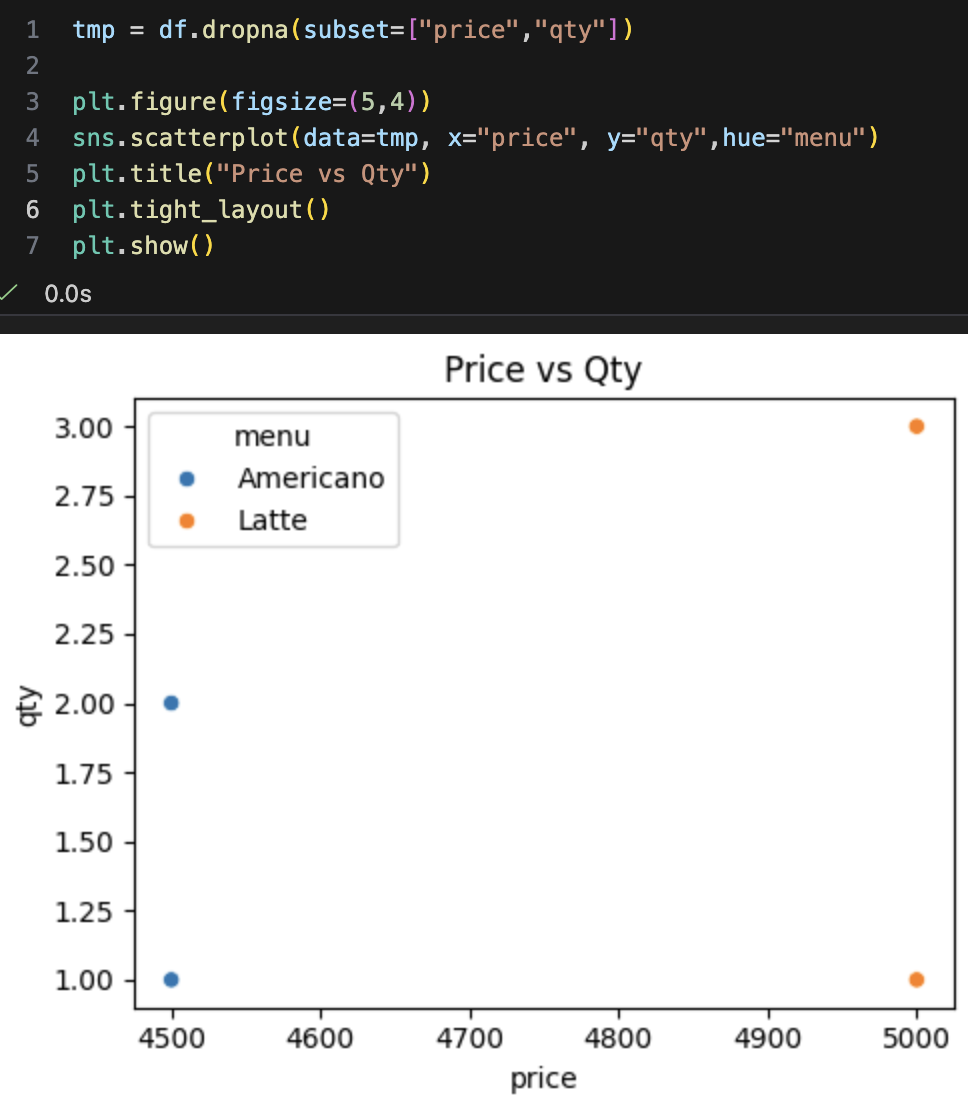
- 히스토그램(Histogram): "값의 분포는 어떤가?" - 우리 주문 가격대는 어떤 구간에 몰려있을까?
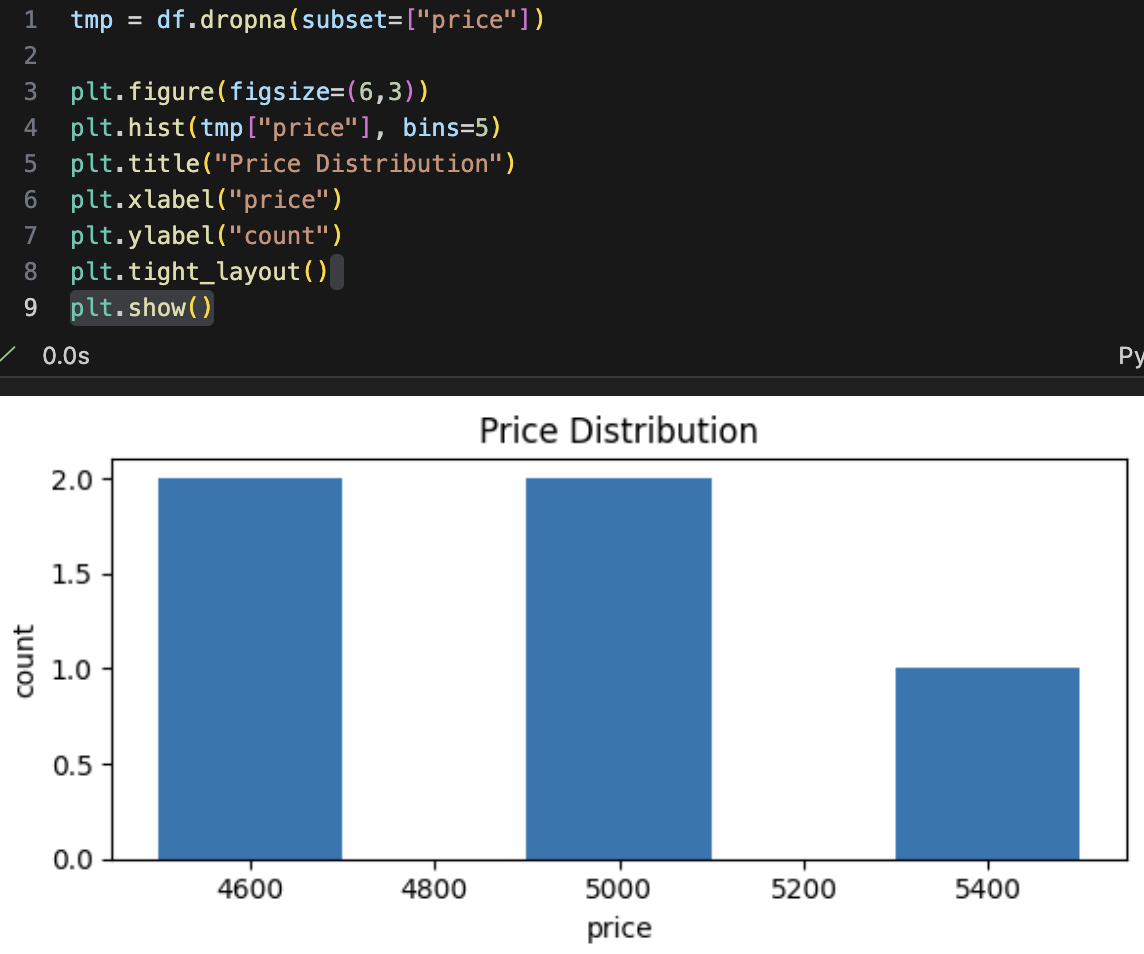
- 히스토그램(Histogram): "값의 분포는 어떤가?" - 매출 분포도 확인하고 한두 건이 전체를 끌어올리는지 확인하기
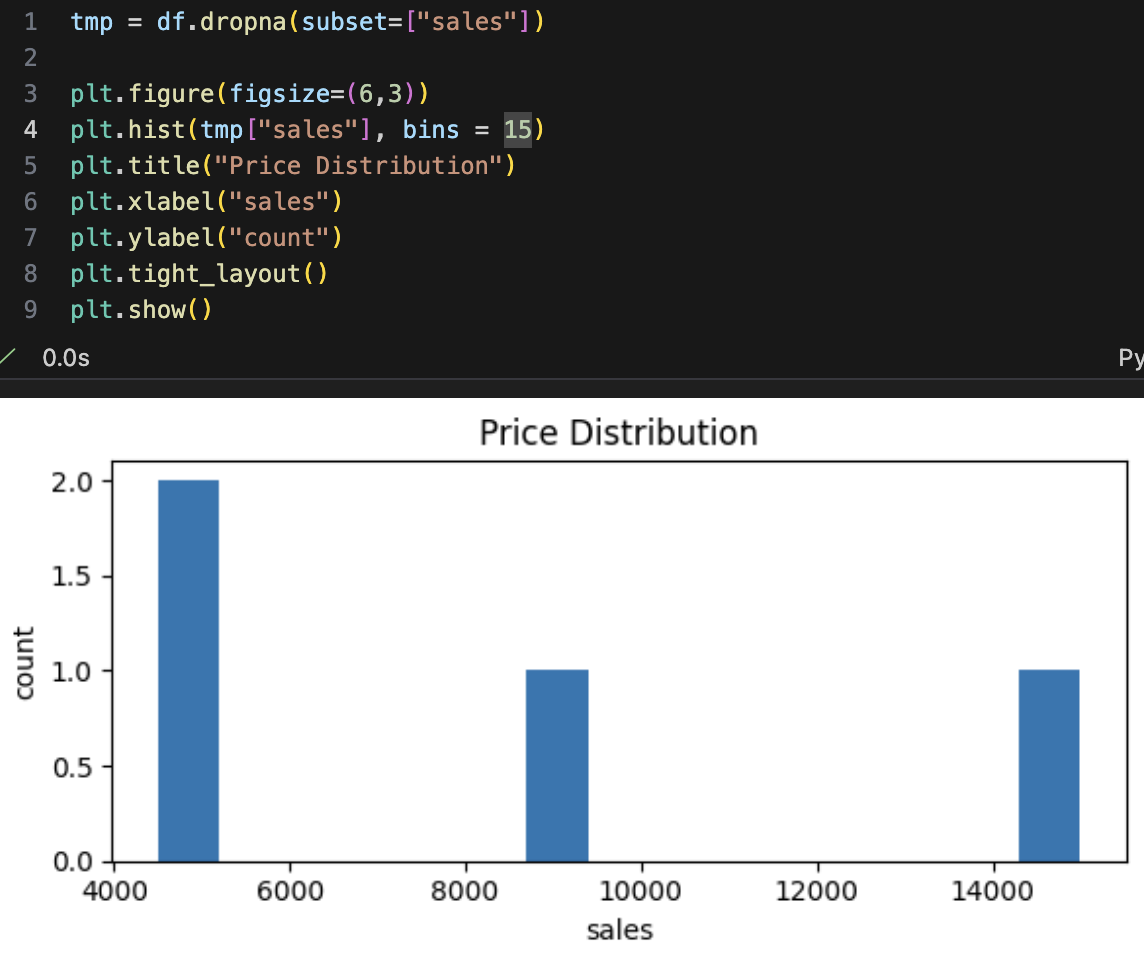
- 박스플롯(Box) & 바이올린(Violin): "이상치/범위 비교" - A와 B 매장 중 매출이 더 안정적인 곳은?
tmp = df.dropna(subset=["sales"])
plt.figure(figsize=(6,3))
sns.boxplot(data=tmp, x="store", y="sales")
plt.title("Sales Spread by Store (Box)")
plt.tight_layout()
plt.show()
plt.figure(figsize=(6,3))
sns.violinplot(data=tmp, x="store", y="sales")
plt.title("Sales Spread by Store (Violin)")
plt.tight_layout()
plt.show()
해석 포인트
- 박스플롯: 중앙값, IQR, 이상치 여부
- 바이올린: 어디에 데이터가 몰려 있는지(밀도)
- 관찰: B 매장의 판매량이 더 범위가 넓게 나왔네 평균과 중간값도 A매장보다 B매장이 더 높게 나왔네
- 추정: B 매장의 매출이 더 높게 나온 이유가 무엇일까. 단가를 높게 잡았을까 아니면 단가가 높은 음료의 주문이 많았을까 그 이유는 뭘까 프로모션이 있었을까 아니면 지리적으로 유리했을까
- 추가적 인사이트: B매장의 매출 범위가 넓다는 것은 변동성이 크다는 것!
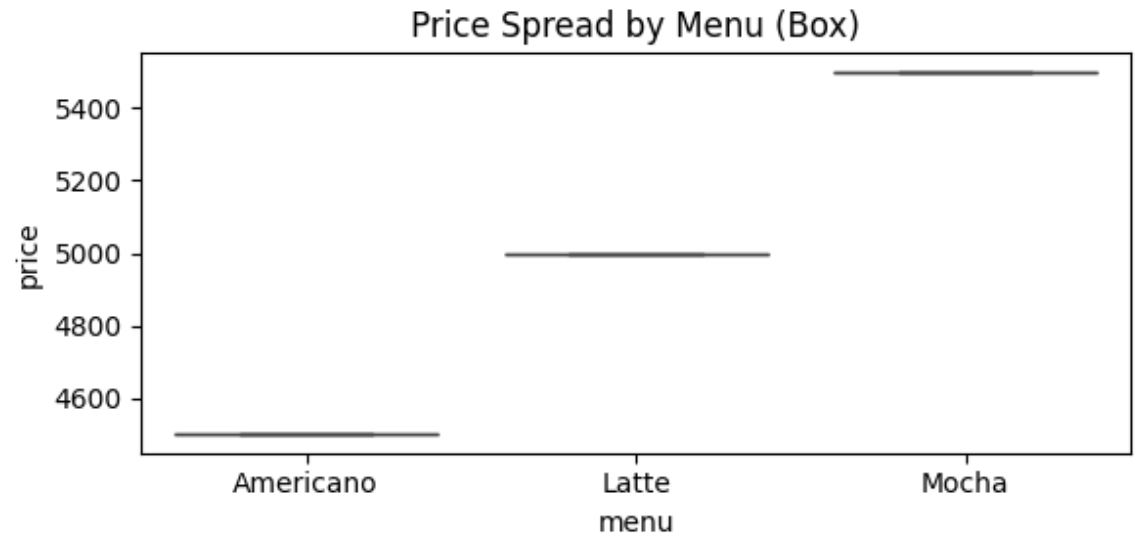
- 미션: menu별 price 박스플롯을 그려서 "가격 변동이 큰 메뉴"를 찾기
- 그래프 예쁘게 꾸미기
- figsize로 크기 조절
- title, xlabel, ylabel
- xticks(rotation=45)
- tight_layout()
- 범례: plt.legend() 또는 seaborn의 hue
- 정렬 후 그리기(순위 그래프는 꼭 정렬)
- 결측 제거/대체 후 그리기(그래프 오류 예방)
- 초보자를 위한 FAQ
- Q. 왜 그래프가 안 그려져요?
- plt.show() 누락, 컬럼명이 틀림, 결측/문자열 때문에 숫자축이 깨짐이 대부분.
- Q. line plot인데 날짜가 이상해요.
- pd.to_datetime이 핵심. errors="coerce"면 실패가 NaT로 바뀌니 확인 필요.
- Q. barplot 결과가 이상해요.
- 집계 없이 원본을 바로 그리면 중복 막대가 생길 수 있음. groupby().sum() 먼저.
- Q. seaborn이 더 좋은가요?
- 빠른 성공은 seaborn, 세밀한 보고서 품질은 matplotlib 조합이 좋음.
- 차트 선택의 5가지 기준
- 시간에 따른 변화(추이) → Line
- 항목 간 크기 비교(순위) → Bar
- 두 변수 관계(상관/패턴) → Scatter
- 값이 어떻게 퍼져 있나(분포) → Histogram
- 이상치/범위/안정성 비교(사분위, IQR = Interquartile Range) → Box(또는 Violin)
Time이면 Line, Compare면 Bar, Relation이면 Scatter, Distribution이면 Hist, Outlier/Spread면 Box
- Line Plot
- 언제 쓰나?
- 시간 흐름에 따른 변화를 보고 싶을 때
- “추세(trend)”를 보여주는 데 최적
- 주의점(초보자 실수 TOP3)
- 날짜가 문자열이면 축이 깨짐 → to_datetime() 필수
- 원본 데이터 그대로 그리면 “한 날짜가 여러 줄”로 섞임 → 일자별 집계(groupby) 필요
- 날짜 정렬을 안 하면 선이 왔다 갔다 → sort_values("date") 필수
- Bar Chart
- 언제 쓰나?
- 항목 간 비교(메뉴별/지점별/카테고리별)
- 순위 보여주기(Top-N)
- 왜 '집계+정렬'이 핵심인가?
- 막대 그래프는 '항목별 총합/평균'을 비교한느 경우가 대부분이라
- groupby로 먼저 요약(집계)하고
- sort_values로 순위를 정렬해야 “의미 있는” 그래프가 됨
- 막대 그래프는 '항목별 총합/평균'을 비교한느 경우가 대부분이라
- Scatter Plot (산점도)
- 언제 쓰나?
- "A가 커지면 B도 커지나?"
- 즉 두 변수의 관계/패턴(양/음/무관)을 볼 때
- 산점도에서 결측 제거가 중요한 이유
- 산점도는 x,y가 둘 다 필요함
- x 또는 y가 결측이면 점을 찍을 수 없어 결과가 왜곡되거나 에러가 남
- 산점도는 **dropna(subset=[x,y])**가 기본임
- Histogram
- 언제 쓰나?
- 값이 어떤 구간에 몰려 있는지(분포)
- "대부분 비슷한가?", "극단적으로 큰 값이 있나?" 확인
- 히스토그램의 핵심 포인트
- bins(막대 개수)에 따라 느낌이 달라짐
- 처음엔 5~15 사이로 시작하면 이해가 쉬움
- Bins가 너무 많을 때
- 막대의 폽이 좁아지고 개수가 많아짐
- 문제점:
- 데이터의 전체적인 흐름이나 패턴(경향성)보다 노이즈가 두드러짐
- 개별 데이터의 미세한 변동에 집중하게 되어, 실제로 중요한 '분포의 모양'을 파악하기 어려움
- 과적합과 유사한 상태
- Bins가 너무 적을 때
- 막대의 폭이 넓어지고 개수가 적어짐
- 문제점
- 데이터가 가진 세부 특징이 묻혀버림
- 중요한 정보를 손실 할 가능성 존재
- Box Plot
- 언제 쓰나?
- 이상치(outlier)가 있는지
- 그룹별(지점/메뉴 등)로 '어느 쪽이 더 안정적인지' 비교할 때
- 박스플롯이 보여주는 것
- 가운데 선: 중앙값
- 박스: 가운데 50% (Q1~Q3)
- 수염: 일반 범위
- 점(또는 튀는 값): 이상치 후보

- Matplotlib 그래프 한글 깨짐 대부분 해결 (macOS)
plt.rcParams["font.family"] = "AppleGothic"
plt.rcParams["axes.unicode_minus"] = False
- Tableau vs matplotlib
- tableau의 인터페이스가 better
- Tableau: 대시보드용
- Matplotlib: 분석용
- 해석 템플릿(학생이 그대로 쓰게)
- 관찰: “01-01 대비 01-04에 매출이 (증가/감소)했다.”
- 추정: “(수량/결제성공/가격) 변화가 원인일 수 있어 추가 확인이 필요하다.”
- 이거 차트 만들 때마다 아래에 마크다운으로 작성하기
'데이터 전처리 및 시각화' 카테고리의 다른 글
| 기계학습, 파이프라인 저장과 streamlit 입력폼 생성 (0) | 2026.01.23 |
|---|---|
| GroupBy 결합, apply/map 사용 (0) | 2026.01.20 |
| 결측, 중복 전처리: Pandas Cleaning 정제 (1) | 2026.01.19 |
| dtype, 결측치, CSV/Excel/JSON 다루기 (0) | 2026.01.19 |