[ BASIC반 통계학 강의 ]
- 신뢰수준이 넓어지면 당연한 말이 나올 것....
- 신뢰수준은 그 값을 포함할거라고 예상되는 범위의 넓이...
- 신뢰수준이 높을수록 그 범위가 넓어져서 그 값을 신뢰구간이 포함할 확률이 높아짐
- 그래도 더 정밀한 결과를 위해 신뢰수준을 최대한 줄이려고 하는데 가장 적당한 수준이 95%인 것
- 부동산 데이터 실습
numeric_df = df.select_dtypes(include='number')
numeric_df.drop(columns=['접수연도','건축년도'],inplace=True)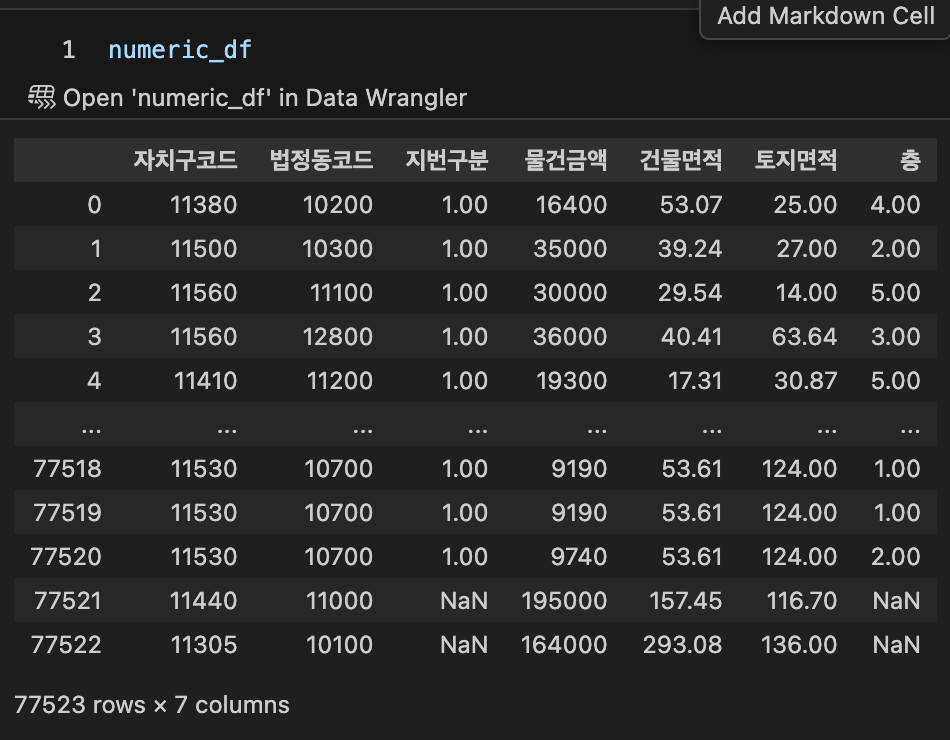

- 이상치 제거

area_data는 현재 numpy array 형태!
pandas의 dataframe이나 series 형태가 아니기 때문에 area_data.quantile(0.25)와 같은 식이 불가능함
따라서 numpy 라이브러리의 percentile 메서드를 통해 quantile을 대체!
lower_whisker = q_1 - 1.5*iqr
upper_whisker = q_3 + 1.5*iqr
outliers = conti_df.loc[(conti_df['토지면적']<lower_whisker)|(conti_df['토지면적']>upper_whisker)]
area_data_cleaned = conti_df.loc[(conti_df['토지면적']>=lower_whisker)&(conti_df['토지면적']<=upper_whisker),'토지면적']
plt.hist(area_data_cleaned,bins=20)
plt.show()

- 추론통계

- 신뢰구간 구하기


- 이산형 분포
- 동전던지기 (베르누이 시행)
- 이항분포 (베르누이 시행을 반복)
- 연속형 분포
- 연속형 데이터에 대한 확률을 나타내는 분포
- 정규분포
- 표준화
- 분포의 평균과 분산 값을 0과 1로 통일하는 작업
- 공식: X (값) 에서 평균 \mu을 빼고 표준편차 \sigma로 나눈 값
- Z = (X - \mu) / \sigma
- 표준화
- t분포
- 카이제곱 분포
- F분포
- 중심극한정리
- 표본평균은 정규분포를 따른다!!!!!는 정리
- 모집단의 분포가 어떠하든 상관없이 표본평균은 정규분포를 따르기 때문에 표본을 이용해서 우리는 모수를 추정해낼 수 있게 된다

import numpy as np
import matplotlib.pyplot as plt
# 1. 모집단: 0~100 사이의 균등분포 (전혀 정규분포가 아님)
population = np.random.uniform(0, 100, 10000)
sample_means = []
n = 30 # 표본의 크기
iterations = 1000 # 표본 추출 반복 횟수
for _ in range(iterations):
sample = np.random.choice(population, size=n)
sample_means.append(np.mean(sample))
# 2. 표본평균들의 분포 시각화
plt.hist(sample_means, bins=30, edgecolor='black')
plt.title(f"Distribution of Sample Means (n={n})")
plt.show()
# 표본 개수에 따른 표준오차 확인
import numpy as np
# 모집단 설정 (평균 50, 표준편차 15)
pop_std = 15
# 표본 크기 시나리오
n_small = 5
n_large = 100
# 표준오차(Standard Error) 계산
se_small = pop_std / np.sqrt(n_small)
se_large = pop_std / np.sqrt(n_large)
print(f"n=5 일 때의 표준오차: {se_small:.2f}")
print(f"n=100 일 때의 표준오차: {se_large:.2f}")
# 결과 해석: n이 20배 커지면, 오차의 범위는 약 1/4.5 수준으로 감소함
- 표본평균이 정규분포 위에 있다는 것을 알게되면 신뢰구간을 구할 수 있다
- 즉, 표본데이터를 통해서 모집단의 신뢰구간을 구할 수 있다!
- t분포 (t-distribution) : 모집단의 표준편차를 모를 때 사용하는 분포!!!
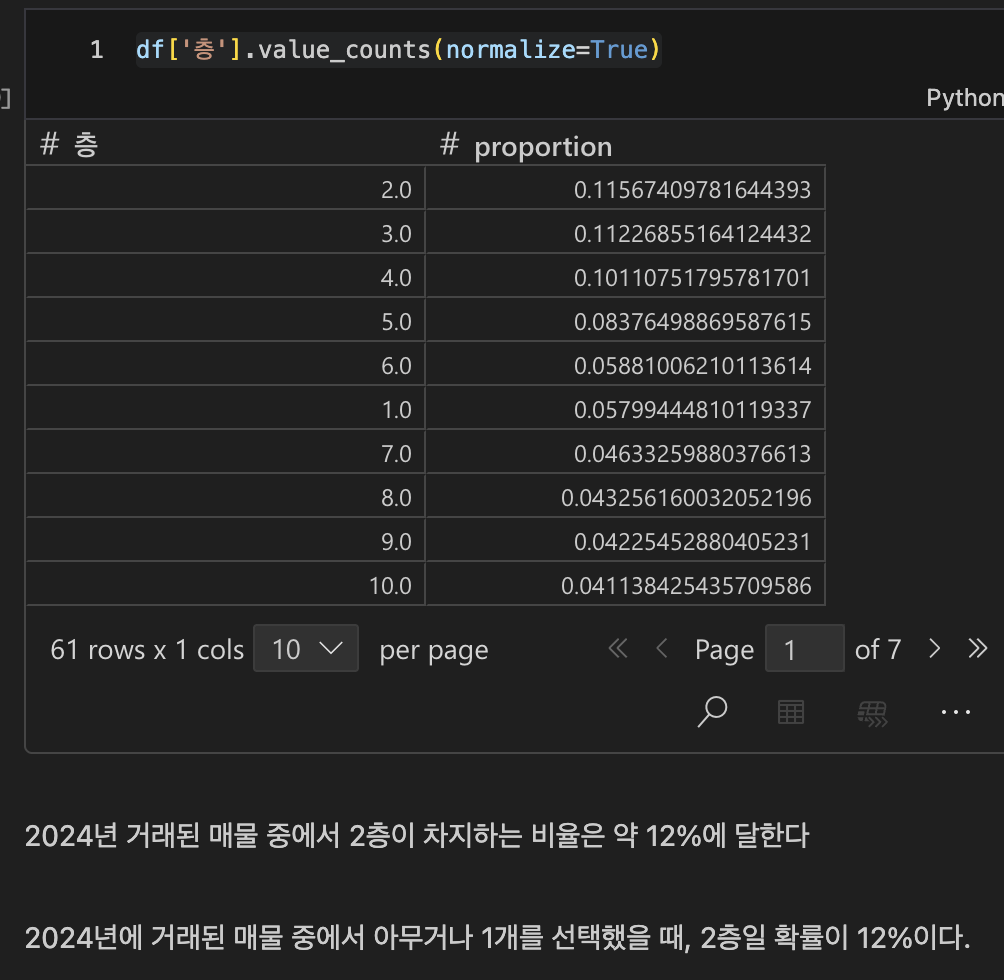
- 각 범주별 차지 비율 확인
- value_counts(normalize=True)
- 표준화
- 연립다세대주택 중에서 오복홈타운의 건물 면적과 토지면적은 높은 편일까? => 평균보다 높은가?
- 만약 둘다 평균보다 높다고 나온다면, 오복홈타운의 건물면적과 토지면적 중 어떤 면적이 평균에서 더 멀리 떨어져있을까?
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
multiplex_house_df_cleaned['건물면적_표준화']= scaler.fit_transform(multiplex_house_df_cleaned[['건물면적']])
multiplex_house_df_cleaned['토지면적_표준화']= scaler.fit_transform(multiplex_house_df_cleaned[['토지면적']])
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
data_A = multiplex_house_df_cleaned['건물면적']
data_B = multiplex_house_df_cleaned['토지면적']
# 두 변수의 평균과 표준편차
mu_A, sigma_A = np.mean(data_A), np.std(data_A)
mu_B, sigma_B = np.mean(data_B), np.std(data_B)
# x 범위 (두 분포를 모두 포함하도록)
x = np.linspace(
min(min(data_A),min(data_B)),
max(max(data_A),max(data_B)),
500
)
# PDF 계산
pdf_A = norm.pdf(x, mu_A, sigma_A)
pdf_B = norm.pdf(x, mu_B, sigma_B)
# 시각화
plt.figure(figsize=(8,5))
plt.plot(x, pdf_A, label="건물면적",color ='blue')
plt.plot(x, pdf_B, label="토지면적",color ='orange')
plt.axvline(x=target['건물면적'].values,linestyle = "--", alpha=0.3, label="오복홈타운 건물면적",color ='blue')
plt.axvline(x=target['토지면적'].values,linestyle = "--", alpha=0.3, label="오복홈타운 토지면적",color='orange')
plt.xlabel("Value")
plt.ylabel("Probability Density")
plt.title("Normal Distribution Comparison (Assumed)")
plt.legend()
plt.show()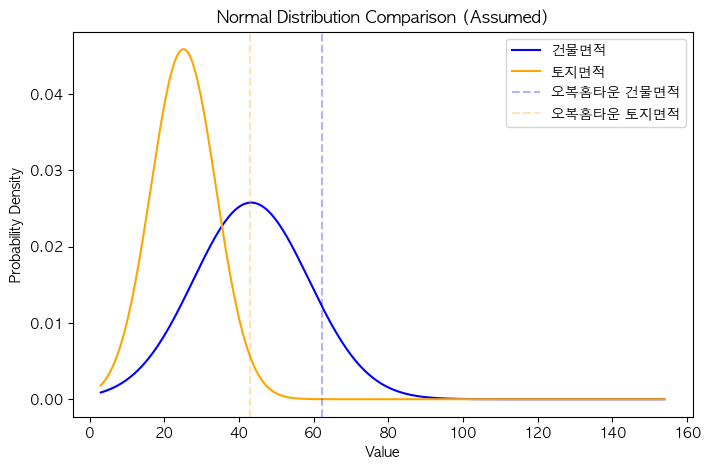
- 두 변수(건물면적, 토지면적)가 정규분포를 따른다고 가정했을 떄, 두 분포의 모양을 비교하고 특정데이터(오복홈타운)의 위치를 시각화하는 코드
- np.linspace(min, max, 500) : 시각화를 위한 x축의 좌표들을 생성함, 최소값부터 최댓값까지 500개의 점을 아주 촘촘하게 찍는 것. 이 점들이 모여 부드러운 곡선을 만듦
- norm.pdf(x, mu, sigma) : 확률밀도함수 값을 계산함. 주어진 평균과 표준편차를 가진 정규분포에서 x라는 지점의 밀도가 얼마인지를 반환함
- plt.axvline(x=...,...) : 특정 x축 지점에 세로선을 그음. '오복홈타운'이라는 특정 샘플의 실제 값을 선으로 표시하여, 전체 분포 중 어느 위치(평균에 가까운지, 극단치에 가까운지)에 있는지 시각적으로 대조하기 위해 사용됨
- but 이 그래프를 봐서는 두 그래프의 모양과 평균이 다르기 때문에 비교를 할 수가 없음!
- 확률밀도는 특정 지점에서의 '확률' 그 자체가 아님
- 확률 vs 확률밀도 (Probability vs Density)
- 확률: 특정 사건이나 범위가 일어날 가능성. 연속형 데이터에서는 특정 '지점'의 확률은 항상 0임. 대신 범위의 면적이 확률이 됨.
- 확률밀도: 특정지점에서 확률이 얼마나 밀집되어있는지를 나타내는 '높이'. 이 높이 자체는 확률이 아니므로 1보다 클 수도 있음.
- norm.pdf 값
from scipy.stats import norm
# 건물면적의 평균 50, 표준편차 10 가정
mu, sigma = 50, 10
# 1. 확률밀도(높이): 50일 때의 밀도
density_50 = norm.pdf(50, mu, sigma)
print(f"평균 지점의 밀도(높이): {density_50}") # 0.0398
# 2. 확률(면적): 면적이 40에서 60 사이일 확률
prob_40_60 = norm.cdf(60, mu, sigma) - norm.cdf(40, mu, sigma)
print(f"40~60 사이의 확률(면적): {prob_40_60:.4f}") # 약 0.6827
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
data_A = multiplex_house_df_cleaned['건물면적_표준화']
data_B = multiplex_house_df_cleaned['토지면적_표준화']
# 두 변수의 평균과 표준편차
mu_A, sigma_A = 0,1
mu_B, sigma_B = 0,1
# x 범위 (두 분포를 모두 포함하도록)
x = np.linspace(
-4,4,500
)
# PDF 계산
pdf_A = norm.pdf(x, mu_A, sigma_A)
pdf_B = norm.pdf(x, mu_B, sigma_B)
# 시각화
plt.figure(figsize=(8,5))
plt.plot(x, pdf_A, label="건물면적",color ='blue')
plt.plot(x, pdf_B, label="토지면적",color ='orange')
plt.axvline(x=target['건물면적_표준화'].values,linestyle = "--", alpha=0.3, label="오복홈타운 건물면적",color ='blue')
plt.axvline(x=target['토지면적_표준화'].values,linestyle = "--", alpha=0.3, label="오복홈타운 토지면적",color='orange')
- 연립다세대주택 중에서 오복홈타운의 건물면적과 토지면적은 평균보다 높은가?
--> 그렇다
- 만약 둘다 평균보다 높다고 나온다면, 오복홈타운의 건물면적과 토지면적 중 어떤 면적이 평균에서 더 멀리 떨어져있을까?
--> 토지면적이 더 멀리 떨어졌다. 표준화 점수를 비교해보니 토지면적의 표준화점수가 건물면적의 표준화 점수보다 높게 나왔다. 토지면적이 토지면적의 평균에서 떨어진 정도가 건물면적이 건물면적의 평균에서 떨어진 정도보다 더 크다는걸 의미한다.
- 신뢰구간 구하기
# 같은 매물 데이터는 중복 제거
multiplex_house_only_df = multiplex_house_df.sort_values(['건물명','자치구코드','법정동코드','층','계약일'])\
.drop_duplicates(subset=['건물명','자치구코드','법정동코드','층'],keep='last')
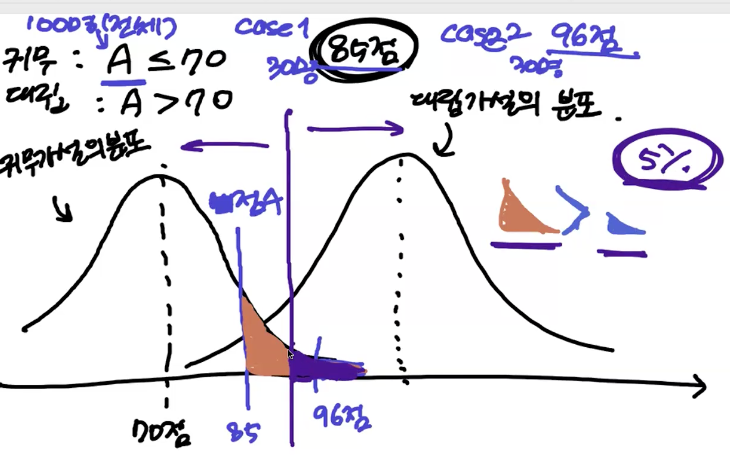
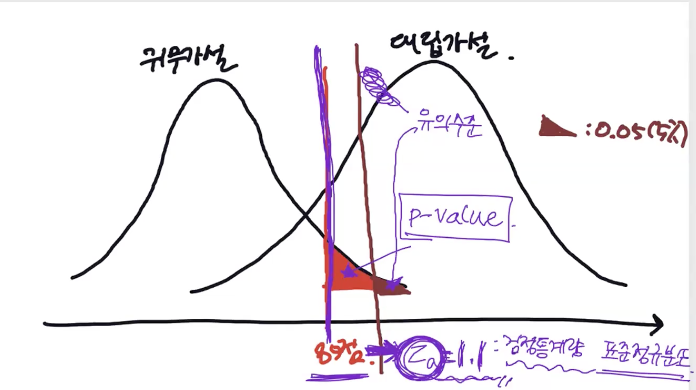
- 검정통계량 : 보라색 선, 분포 상에서 우리가 가진 표본의 위치값
- p-value : 빨간색 면적, 표본에서 나온 값의 이상을 받을 확률
- 유의수준 : 갈색 색칠부분 면적의 확률
- 1종오류와 2종오류
- 1종오류 (위양성): 귀무가설이 맞는데 대립가설을 채택한 경우
- 2종오류 (위음성): 대립가설이 맞는데 귀무가설을 채택한 경우
'통계학 공부' 카테고리의 다른 글
| ANOVA, 카이제곱 검정과 상관분석 실습 (0) | 2026.02.18 |
|---|---|
| 통계학 세션 이론 5일차 (상관관계와 인과관계, A/B Test) (0) | 2026.02.18 |
| 통계학 세션 이론 4일차 (가설검정 심화) (0) | 2026.02.18 |
| 통계학 세션 이론 3일차 (예언구간 vs 신뢰구간, 가설검정) (0) | 2026.02.18 |
| 통계학 세션 이론 2일차 (확률분포, 정규분포) (0) | 2026.02.18 |