- 가설검정의 기본 순서
STEP1: 가설 설정 - 귀무가설과 대립가설 각각 설정
STEP2: 가설에 적합한 검정 방법 선택
STEP3: 유의수준 결정
STEP4: 검정방법에 따라서 표본의 검정통계량과 p-value 계산
STEP5: 유의수준과 p-value를 비교하여 귀무가설의 기각여부 결정
- 가설검정의 종류
- 분포에 따른 구분
| 검정 방식 | 관련 분포 | 활용대상 | 대상 | 검정통계량 |
| Z-검정 | 표준정규분포(Z분포) | 집단 개수: 주로 2개 표본의 평균 비교 모집단의 분산을 알 수 있는 경우 |
연속형 자료 |  |
| t-검정 | t분포 | 집단 개수: 주로 2개 표본의 평균 비교 모집단의 분산을 알 수 없는 경우 |
연속형 자료 | 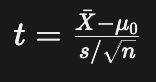 |
| F-검정 (분산분석 ANOVA) | F분포 | 집단 개수: 주로 3개 이상 두 개 이상의 그룹의 분산 비교 3개 이상의 집단 간 평균의 차이 비교 |
연속형 자료 | 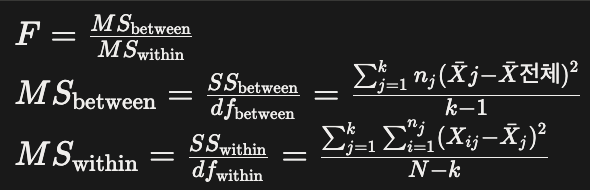 |
| 이항 비율 검정 | 이항분포 표준정규분포(Z-분포) |
집단 개수 : 1개 or 2개 표본의 비율 비교 ( ex. 전환율 비교) |
범주형 자료 | 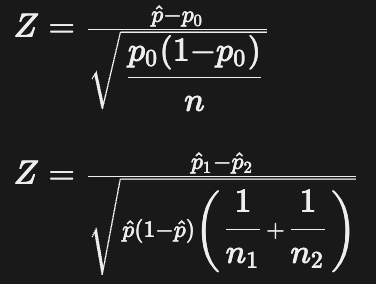 |
| 카이제곱검정 | 카이제곱분포 | 집단 개수: 주로 2개 이상 독립성 검정 : 두 범주형 변수가 독립적인지 적합도 검정 : 데이터가 특정 분포를 따르는지 |
범주형 자료 | 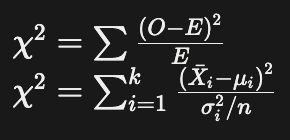 |
- 상황에 따른 구분 (모수검정)
| 비교 대상 | 상황 | 검정 | 관련분포 | 전제조건 |
| 평균 | 한 집단 vs 기준값 | 단일표본 t검정 | t분포 | 정규성 |
| 독립된 두 집단 | 독립표본 t검정 | t분포 | 정규성, 등분산성 | |
| 대응된 두 집단 | 대응표본 t검정 | t분포 | 정규성 | |
| 세 집단 이상 | ANOVA | F분포 | 정규성, 등분산성, 독립성 | |
| 비율 | 한 집단 vs 기준값 | 단일표본 이항비율 z-검정 | 이항분포 | 표본수가 커야 함 ( np > 5, n(1-p) > 5) • n: 표본의 크기, p: 표본에서 구한 비율 |
| 독립된 두 집단 | 이표본 이항비율 z-검정 | 이항분포 | 표본수가 커야 함 ( np_1 > 5, np_2>5, n(1-p_1) > 5, n(1-p_2)>5) 독립성 |
현실적으로 모집단의 분산을 알 수 있는 경우가 많지 않기 때문에 t-검정을 주로 사용합니다.
- t-검정
1개 또는 2개의 집단 간 평균 차이를 비교하는 검정 방법. 정규분포를 가정.
- t-검정의 전제
- 정규성: 정규분포에서 나온 데이터라는 전제를 가짐
- 등분산성 : 비교 대상의 분산이 같다
- → 전제가 어긋날 경우 비모수검정(non-parametric test)을 고려해야 함
- t-검정의 종류
- 단일표본 t검정 (One-Sample t-test)
- 하나의 집단 평균이 특정 기준값과 다른지 비교
- 예 : 학생들의 평균 수면시간이 7시간과 다른가?
- 귀무가설 : 모집단의 평균은 7시간이다.
- 대립가설 : 모집단의 평균은 7시간이 아니다.
- 연구 맥락에 따라 의미 있는 기준값을 설정하는 것이 중요
- 이표본 t검정 (Two-Sample t-test)
- 독립표본 t검정과 동의어
- 서로 독립된 두 집단의 평균 차이 비교
- 예 : 남학생과 여학생의 평균 키가 다른가?
- 귀무가설 : 두 집단의 평균은 같다.
- 대립가설 : 두 집단의 평균은 다르다.
- 전제 조건 : 정규성, 등분산성
- 정규성이 어긋날 경우 → Mann-Whitney U검정 사용 (비모수 대안)
- 정규성은 충족, 등분산성이 어긋날 경우 → Welch t검정을 사용 (정규성 가정은 여전하지만 분산은 달라져도 괜찮음)
- 대응표본 t검정 (Paired t-test)
- 같은 집단에서 전과 후를 비교하거나, 쌍을 이룬 데이터 비교
- 예 : 약 복용 전후의 혈압 차이 → 비교 대상이 같은 사람, 같은 특성
- 두 시점의 차이값(후 - 전) 자체가 정규성을 가져야 함
- 정규성 어긋날 경우 : Wilcoxon signed-rank 검정 사용
- 단일표본 t검정 (One-Sample t-test)
- 대응 여부 구분하기
| 구분 | 독립 t 검정 | 대응 t 검정 |
| 데이터 구조 | 두 집단이 전혀 다른 사람들 | 같은 사람의 전/후 변화 |
| 예시 | 실험군 vs 대조군 | 복용 전 vs 복용 후 |
| 검정이름 | 이표본 t검정 | 대응표본 t검정 |
- t-검정의 전제: 정규성과 등분산성
- 정규성 : 표본이 정규분포를 따르는 모집단에서 나왔다고 가정
- 등분산성 : 두 집단의 분산이 동일하다고 가정
- 정규성 검정 : 표본이 정규분포를 따르고 있는지 검정
| 방법 | 설명 | 사용 시기 |
| Q-Q플랏 | 정규분포와 데이터의 분위수를 비교하는 시각적 도구 | 탐색적 단계, 직관적 확인 |
| 히스토그램 확인 | 데이터 분포의 대칭성과 종모양을 시각적으로 확인 | 보조 자료로 사용 |
| 샤피로-윌크 검정 | 귀무가설: “정규분포이다” (p < 0.05면 정규성 기각) | 소표본일 때 효과적 |
| Kolmogorov-Smirnov 검정 (KS 검정) | 이론적 분포(정규분포 등)와 데이터 분포의 차이 검정 | 대체로 샤피로보다 덜 민감 |
표본의 크기가 클 때 정규성 가정 완화
n > 30이면 ( 표본의 크기가 크면 ) 중심극한 정리에 의해 자료가 정규분포가 아니더라도 정규성 가정을 기반으로 한 검정(t-검정 등)을 사용할 수 있다.
ex) Q-Q 플랏의 결과가 약간 삐져나온 정도인데 샤피로-윌크 검정에서 p-value < 0.05로 정규성 기각을 하려 했지만 표본의 크기가 크면 정규성을 가정으로 검정을 할 수 있음 (정규성 가정 완화할 수 있다)
그러나, 표본 수가 작은데 분포가 다음과 같은 특징을 보이면, 비모수 검정을 사용한다.
- 극단적 비대칭
- heavy tail
- 명백한 이상치
- 등분산성 검정
| 방법 | 설명 | 사용 시기 |
| Levene 검정 | 귀무가설: "두 집단의 분산은 같다" | 가장 널리 쓰이며 정규성 민감도 낮음 |
| Bartlett 검정 | 세 집단 이상에서 분산 동질성 검정 | 2개 이상 집단의 분산이 동일한지 검정 (정규성 가정 강함) |
정규성은 충족, 등분산성이 어긋날 경우 : Welch t검정을 사용
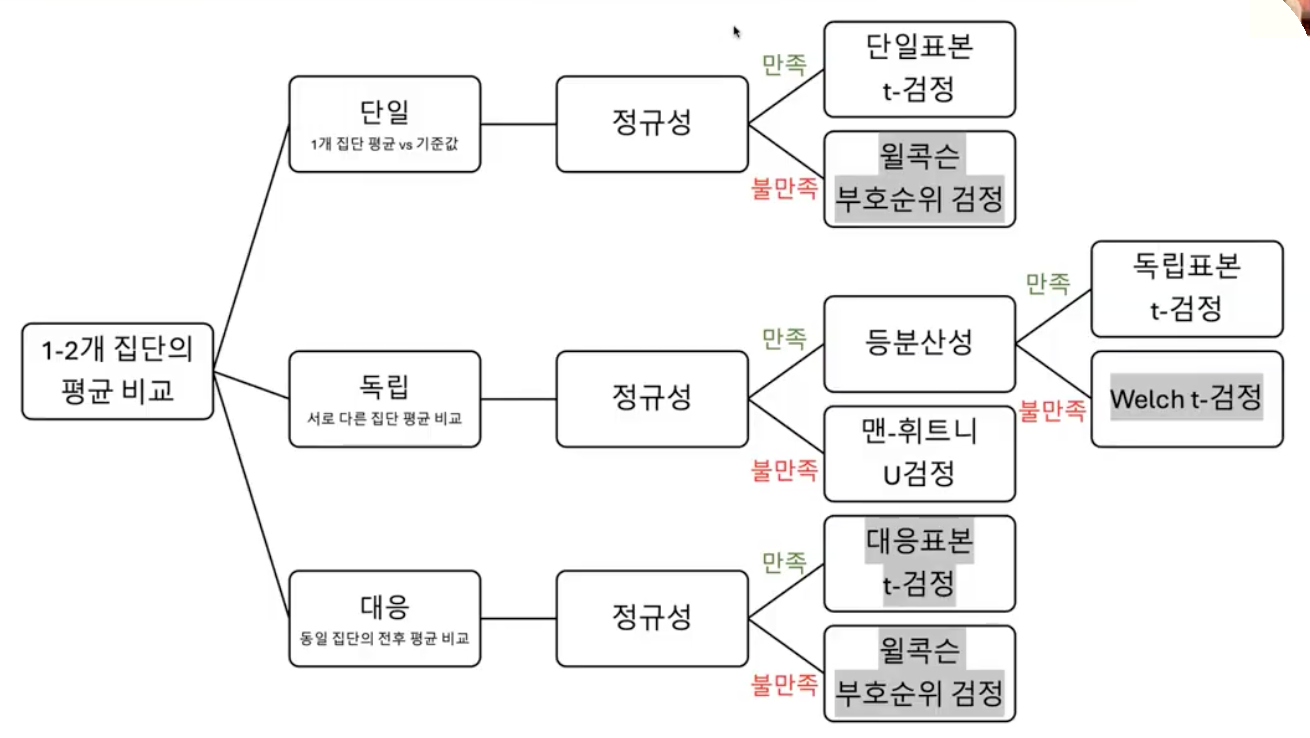
- 정리
| 단일 | 독립 | 대응 | |
| 모두 만족 | 단일표본 t-검정 | 독립표본- t검정 | 대응표본 - t검정 |
| 정규성 불만족 (비모수 검정) | Wilcoxon 부호 순위 검정 | Mann Whitney U-검정 | Wilcoxon 부호 순위 검정 |
| 등분산성 불만족 (비모수 검정) | - (단일 표본이므로 등분산성 검정 필요 없음) | Welch t검정 | - (같은 표본이므로 등분산성 검정 필요 없음) |
모수는 숫자값 자체를 가지고 비교를 하지만 비모수 검정의 경우엔 중앙값과 같이 그 값이 어디에 위치해있는지를 기준으로 비교를 함
- 가설검정
- 표본 데이터를 통해 모집단의 가설을 검증하는 과정
- 즉, 데이터가 특정 가설을 지지하는지 평가하는 과정
- 귀무가설과 대립가설을 설정하고 귀무가설을 기각할지를 결정
- 두가지 전략을 취할 수 있음
- 확증적 자료분석
- 미리 가설들을 먼저 세운 다음 가설을 검증해 나가는 분석
- 탐색적 자료분석
- 가설을 먼저 정하지 않고 데이터를 탐색해보면서 가설 후보들을 찾고 데이터의 특징을 찾는 것
- 확증적 자료분석
- 통계적유의성
- 결과가 우연히 발생한 것이 아니라 어떤 효과가 실제로 존재함을 나타내는 지표
- p값은 귀무가설이 참일경우 관찰된 통계치가 나올 확률을 의미
- 일반적으로 p값이 0.05 미만이면 결과를 통계적으로 유의하다고 판단
- p-값
- 귀무가설이 참일 때, 관찰된 결과 이상으로 극단적인 결과가 나올 확률
- 일반적으로 p-값이 유의수준보다 작으면 귀무가설을 기각
- p-값을 통한 유의성 확인
- p-값이 0.03이라면 3%확률로 우연히 이러한 결과가 나올 수 있음
- 즉, 유의수준보다 낮은 확률!!!로 귀무가설이 참일 때 이러한 유의미한 결과가 나올 수 있음
- 효과가 없다면 0.03%의 확률로 이러한 결과가 나올텐데 이 확률이 굉장히 낮으니까 효과가 없다는 가설이 거짓이지 않을까?
- 가설검정
- 모수가 특정 값과 같은지 다른지 테스트
# 기존 약물(A)와 새로운 약물(B) 효과 데이터 생성
A = np.random.normal(50, 10, 100)
B = np.random.normal(55, 10, 100)
# 평균 효과 계산
mean_A = np.mean(A)
mean_B = np.mean(B)
# t-검정 수행
t_stat, p_value = stats.ttest_ind(A, B)
print(f"A 평균 효과: {mean_A}")
print(f"B 평균 효과: {mean_B}")
print(f"t-검정 통계량: {t_stat}")
print(f"p-값: {p_value}")
"""
A 평균 효과: 50.67957035675973
B 평균 효과: 54.549213204404225
t-검정 통계량: -2.7330499997739275
p-값: 0.006843169283450394
"""import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# 1. 자유도(df) 계산 (독립표본 t-검정의 경우: n1 + n2 - 2)
df = len(A) + len(B) - 2
# 2. t-분포 곡선을 그리기 위한 x축 설정
x = np.linspace(-4, 4, 1000)
y = stats.t.pdf(x, df) # t-분포의 확률밀도함수
plt.figure(figsize=(10, 6))
plt.plot(x, y, label='t-distribution (df={})'.format(df), color='black')
# 3. 계산된 t-통계량 위치에 수직선 긋기
plt.axvline(t_stat, color='red', linestyle='--', label=f'Calculated t-stat: {t_stat:.2f}')
# 4. p-값에 해당하는 영역 색칠하기 (양측 검정)
# t-통계량이 양수일 때 오른쪽 꼬리, 음수일 때 왼쪽 꼬리를 기준으로 색칠
x_fill = np.linspace(abs(t_stat), 4, 100)
plt.fill_between(x_fill, stats.t.pdf(x_fill, df), color='red', alpha=0.3, label='p-value area (one side)')
plt.fill_between(-x_fill, stats.t.pdf(-x_fill, df), color='red', alpha=0.3)
plt.title('T-Distribution and P-value Visualization')
plt.xlabel('t-value')
plt.ylabel('Density')
plt.legend()
plt.show()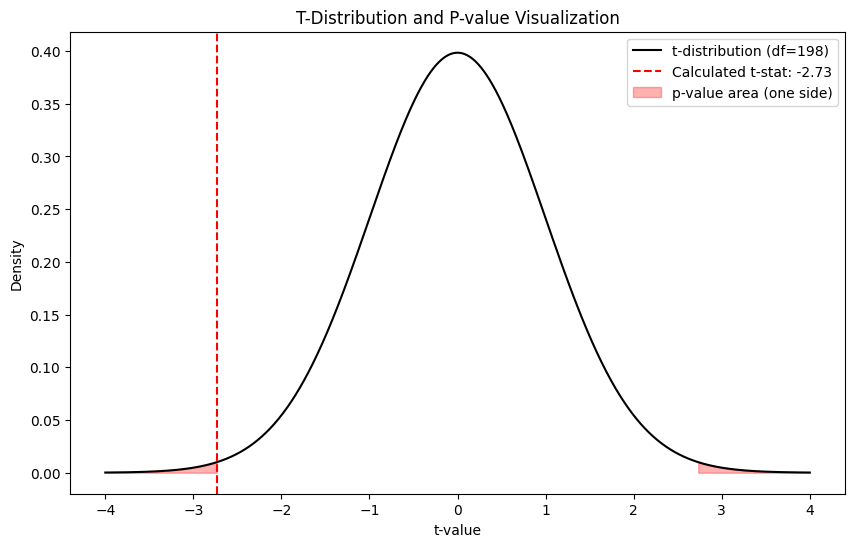
- p-value는 t 값 바깥쪽의 빨간 부분 적분한 값!
- t-value가 가운데 부분 (0에 가까운) 에 있다면 차이가 없다는 귀무가설이 일어날 법한 평범한 확률임
- but 바깥쪽 꼬리 부분에 있다면 차이가 이정도로 크게 날 확률은 매우 희박하다는 것을 보여주는 영역임.
- t-value 바깥쪽 면적(p-value)가 0.05보다 작게 나왔다는 것은 이런 극단적인 결과가 나올 확률이 5% 미만으로 매우 낮으니 이건 단순한 우연이 아니라 유의미한 차이다!!!라고 결론을 내리는 근거가 됨
- 가설 설정 (용의자 선상): "이 약물(B)은 기존 약물(A)이랑 똑같을 거야. (귀무가설)"
- 데이터 증거 수집: 실험을 해보니 효과 차이가 꽤 크게 났고, 그걸 계산해보니 $t$-통계량이 나왔습니다.
- 확률 계산 (p-value): "만약 진짜로 효과가 똑같다면(귀무가설이 참이라면), 이렇게 큰 차이가 날 확률이 **고작 3%($p=0.03$)**밖에 안 되는데?"
- 최종 결론: "3%라는 희박한 확률이 우연히 일어났다고 보기엔 너무 억지스러워. 차라리 '효과가 똑같다'는 처음 가설이 틀렸다고 보는 게 훨씬 합리적이야!"
즉, p-value가 작다는 건:
"우연이라고 하기엔 너무나도 '말이 안 되는(희귀한)' 상황이 벌어졌다. 그러므로 이건 우연이 아니라 실제 약물의 효과다!"라고 선언하는 것입니다.
- t 검정
- 두 집단 간의 평균 차이가 통계적으로 유의미한지 확인하는 검정방법
- 독립표본 t검정과 대응표본 t검정으로 나뉨
- 독립표본 t검정
- 두 독립된 그룹의 평균을 비교
- 대응표본 t검정
- 동일한 그룹의 사전/사후 평균을 비교
- 독립표본 t검정
- p-값을 통한 유의성 확인
- 두 클래스의 시험성적 비교 (독립표본 t검정)
- 다이어트 전후 체중 비교 (대응표본 t검정)
# 학생 점수 데이터
scores_method1 = np.random.normal(70,10,30)
scores_method2 = np.random.normal(75,10,30)
# 독립표본 t검정
t_stat, p_val = stats.ttest_ind(scores_method1, scores_method2)
print(f"T-statistic: {t_stat}. P-value: {p_val}")
# T-statistic: 0.18014269599828237. P-value: 0.8576684770959845
- 다중검정
- 여러 가설을 동시에 검정! 하지만 오류가 발생할 수 있음!
- 각 검정마다 유의수준을 조정하지 않으면 1종 오류 (귀무가설이 참인데 기각하는 오류) 발생 확률이 증가
- 보정 방법
- 본페르니 보정, 튜키 보정, 던넷 보정, 윌리엄스 보정 등
- 가장 대표적이고 기본적인게 본페로니 보정
# 세 그룹의 데이터 생성
np.random.seed(42)
group_A = np.random.normal(10, 2, 30)
group_B = np.random.normal(12, 2, 30)
group_C = np.random.normal(11, 2, 30)
# 세 그룹 간 평균 차이에 대한 t 검정 수행
p_values = []
p_values.append(stats.ttest_ind(group_A, group_B).pvalue)
p_values.append(stats.ttest_ind(group_B, group_C).pvalue)
p_values.append(stats.ttest_ind(group_C, group_A).pvalue)
# 본페로니 보정 적용
alpha = 0.05
adjusted_alpha = alpha / len(p_values)
# 결과 출력
print(f"본페로니 보정되기 전 유의 수준: {alpha:.4f}")
for i, p in enumerate(p_values):
if p < alpha:
print(f"검정 {i+1}: 유의미한 차이 발견 (p={p:.4f})")
else:
print(f"검정 {i+1}: 유의미한 차이 없음 (p={p:.4f})")
# 결과 출력
print(f"본페로니 보정된 유의 수준: {adjusted_alpha:.4f}")
for i, p in enumerate(p_values):
if p < adjusted_alpha:
print(f"검정 {i+1}: 유의미한 차이 발견 (p={p:.4f})")
else:
print(f"검정 {i+1}: 유의미한 차이 없음 (p={p:.4f})")
# 본페로니 보정되기 전 유의 수준: 0.0500
# 검정 1: 유의미한 차이 발견 (p=0.0000)
# 검정 2: 유의미한 차이 없음 (p=0.1461)
# 검정 3: 유의미한 차이 발견 (p=0.0058)
# 본페로니 보정된 유의 수준: 0.0167
# 검정 1: 유의미한 차이 발견 (p=0.0000)
# 검정 2: 유의미한 차이 없음 (p=0.1461)
# 검정 3: 유의미한 차이 발견 (p=0.0058)- 본페로니 보정
- 유의수준을 p_value의 개수로 나누어 더 기준을 타이트하게 만듦 (그룹이 3개여서 p_values가 3개로 나옴..)
- 이번 사례에서는 본페로니 보정을 하기 전과 한 후의 결과가 같지만 실무에선 달라지는 경우 많음
- 귀무가설
- 언제나!!! '차이가 없다', '특별한 일이 일어나지 않았다', '서로 관련이 없다'는 보수적인 입장!
- 독립성 검정
- 귀무가설: 변수간 상관이 없다 (독립이다)
- p값이 유의수준보다 낮으면 귀무가설 기각이니까 연관이 있다, 즉 독립이 아니다
- p값이 유의수준보다 높으면 귀무가설 채택이니까 연관이 없다, 독립이다.
- 적합도 검정
- 귀무가설: 예상과 차이가 없다 (일치한다)
- P값이 유의수준보다 낮으면 귀무가설 기각이니까 차이가 있다, 즉 관측 분포와 기대 분포가 일치하지 않는다 (정상이 아니다)
- p값이 유의수준보다 높으면 귀무가설 채택이니까 차이가 없다, 즉 관측 분포와 기댓값이 일치한다 (정상이다. 골고루 나온다)
- 카이제곱검정
- 범주형 데이터의 표본분포가 모집단 분포와 일치하는지 검정 (적합도 검정)
- 두 범주형 변수 간의 독립성을 검정 (독립성 검정)
- 적합도 검정
- 관찰된 분포와 기대된 분포가 일치하는지 검정
- p값이 높으면 관측분포와 기댓값에 차이가 있다
- p값이 낮으면 관찰된 분포가 기대된 분포에 일치한다
- 독립성 검정
- 두 범주형 변수 간의 독립성을 검정
- p값이 높으면 귀무가설대로 두 범주형 변수에 연관성이 없다, 즉 독립이다
- p값이 낮으면 귀무가설 기각으로 두 범주형 변수에 연관성이 있다, 즉 독립성이 없다
# 적합도 검정
observed = [20, 30, 25, 25]
expected = [25, 25, 25, 25]
chi2_stat, p_value = stats.chisquare(observed, f_exp=expected)
print(f"적합도 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")
# 적합도 검정 카이제곱 통계량: 2.0, p-값: 0.5724067044708798
# p-value가 0.05보다 큼 --> 귀무가설대로 관측값과 기댓값에 차이가 없다
# 독립성 검정
observed = np.array([[10, 10, 20], [20, 20, 40]])
chi2_stat, p_value, dof, expected = stats.chi2_contingency(observed)
print(f"독립성 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")
# 독립성 검정 카이제곱 통계량: 0.0, p-값: 1.0
# p-value가 0.05보다 큼 --> 두 범주형 변수는 연관이 없다 --> 독립이다
# 나이와 흡연 여부 독립성 검정
observed = np.array([[30, 10], [20, 40]])
chi2_stat, p_value, dof, expected = stats.chi2_contingency(observed)
print(f"독립성 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")
# 독립성 검정 카이제곱 통계량: 15.041666666666666, p-값: 0.00010516355403363106
# p-value가 0.05보다 작음 --> 귀무가설 기각 --> 두 범주형 변수는 연관이 있다 --> 독립성이 없다
'통계학 공부' 카테고리의 다른 글
| ANOVA, 카이제곱 검정과 상관분석 (0) | 2026.02.18 |
|---|---|
| 가설검정 실습 (단일, 독립, 대응표본 t검정) (1) | 2026.02.18 |
| 선형회귀, 다항회귀, 스플라인회귀, 피어슨 / 비모수 / 상호정보 상관계수 (1) | 2026.01.10 |
| AB 테스트, 가설검정, t 검정, 다중검정, 카이제곱검정, 제 1종/2종 오류 (1) | 2026.01.10 |
| 스튜던트t분포, 카이제곱분포, 이항분포, 푸아송분포 (0) | 2026.01.10 |